





1.JavaIO基本概念
1.1.JavaIO流基本概念
如果想实现内存与磁盘间的文件读写的话,那么就需要接触**“流”这个概念。流好比是管道,从磁盘到内存是输入,从内存到到磁盘是输出,衍生出来的概念就是输入流和输出流**。有时候我们从磁盘读写的是多媒体等文件,有时候我们从磁盘读写的纯文本文件(.java,.txt),那么流又可以从另外一个维度划分为字节流和字符流。
总而言之,根据输入输出和字节字符的区分把流分为如下四个大类:

四个抽象类都继承了Closeable,这个Closeable中有一个方法叫做close,其作用是当流不再需要时,调用此方法释放与流相关的系统资源。而Closeable继承自AutoCloseable,AutoCloseable的一个典型应用就是try-with-resources,如下所示:
//模拟纯文本复制的案例
try(FileWriter out = new FileWriter("IO/properties/demo2.txt");
FileReader in = new FileReader("IO/properties/demo1.txt")
) {
//每次读10个字符
char [] charArray = new char[10];
int readCount;
while ((readCount=in.read(charArray))!=-1){
out.write(charArray,0,readCount);
}
out.flush();
} catch (IOException e) {
e.printStackTrace();
}
在try语句块中可以写任意与资源(类必须实现AutoCloseable接口)相关的赋值语句,用分号;隔开,这样就可以避免用户没有手动释放资源的情况发生。这里可以看出任意与流相关的资源都可以采用try-with-resources的语法。
字节输出流和字符输出流都实现了Flushable接口,这个接口的一个重要方法是flush,即强制将缓冲区的字符或是字节写入到磁盘当中,避免数据的丢失。
事实上,close和flush方法在四大抽象类的各个实现类中可能有不同的重写,其功能肯定得到了一定的扩展,这一点需要注意。其次,以Stream为结尾的流都是字节流,以Writer/Reader结尾的是字符流。
1.2.JavaIO核心掌握流
需要掌握的流如下
1.文件流:
FileInputStream
FileOutputStream
FileWriter
FileReader
2.转换流(字节转为字符)
InputStreamReader
OutputStreamWriter
3.缓冲流
BufferedInputStream
BufferedOutputStream
BufferedReader
BufferedWriter
4.数据流
DataInputStream
DataOutputStream
5.标准输出流
PrintWriter
PrintStream
6.对象流
ObjectInputStream
ObjectOutputStream
2.文件流
2.1FileInputStream
文件字节输入流,无敌存在,任何类型文件都可以用这个流来读。主要弄清楚它的构造方法和核心方法
构造方法
FileInputStream(File file);
FileInputStrem(String name);
二者本质差不多,都是说明文件的路径在哪里。文件的路径分为绝对路径和相对路径。**而相对路径以项目为根路径。关于路径的规定适用于任意其他的流。**在Windows中,反斜杠和正斜杠都是可以的,不过需要注意反斜杠是转义字符
FileWriter out = new FileWriter(“IO/properties/demo2.txt”);
FileWriter out = new FileWriter(“IO\\properties\\demo2.txt”);
实例方法
// 读一个字节 返回字节的ASCII码值 当无字节可读时,返回-1
int read();
/* 每一次最多读arr.length大小的字节,并存储到arr中
当字节数没有达到arr.length(即文件最后几个字节达不到arr.length时),
这些字节会覆盖掉arr的一部分,而另一部分不会被覆盖掉
该方法返回读到的字节数量,当无字节可读时返回-1
*/
int read(byte [] arr)
/*
每一次最多读len大小的字节,并从off位置开始存储到arr中
该方法返回读到的字节数量,当无字节可读时返回-1
其实这个方法用得还是比较少
*/
int read(byte [] arr,int off ,int len)
//返回文件剩余未读的个数
int available();
// 跳过n个字节不读,并返回实际跳过没读的字节数
long skip(long n);
//关闭与输入流相关的资源
void close()
注意:上面的byte [] arr 实际上说的就是缓冲区
实战
问题描述
仅利用FileInputStream读取含中文字符的文本文件,并打印到控制台中。
基本思路
1、String有构造函数,传入byte数组即可转为String
2、中文字符是两个字节,所以考虑将所有字节都存储到ArrayList中,然后再转化为byte数组,这样可以避免乱码
3、byte数组不能挑选得很大,毕竟数组占用连续的内存空间。
代码
package com.lordbao.fileinputstream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @Author Lord_Bao
* @Date 2020/9/4 11:19
* @Version 1.0
*/
public class Main2 {
public static void main(String[] args) {
try(FileInputStream fis = new FileInputStream("IO\\properties\\123.txt") ) {
//一次读5个字节
byte [] byteArray = new byte[5];
//用ArrayList存储字节数组
List<Byte> byteArrayList = new ArrayList<>();
int readCount;
//每次从byteArray缓冲区中读取 readCount大小的字节,存储到ArrayList中
while ((readCount=fis.read(byteArray)) !=-1){
for (int i=0;i<readCount;i++){
byteArrayList.add(byteArray[i]);
}
}
//调用List的toArray(T [])方法 ,拿到Byte数组
Byte [] finalByteArray = new Byte[byteArrayList.size()];
finalByteArray = byteArrayList.toArray(finalByteArray);
//Byte数组 转为 byte数组
byte [] finalbyteArray = new byte[finalByteArray.length];
for (int i=0;i<finalByteArray.length;i++){
finalbyteArray[i] = finalByteArray[i];
}
//通过byte数组转为String
String s = new String(finalbyteArray);
System.out.println(s);
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果
666 老铁
礼物走起来
注意
byte [] byteArray = new byte[fis.available()];
虽然可以这样写,但是真正情况下,要考虑数组占用内存的问题,毕竟文本的大小是未知的。
2.2FileOutputStream
文件字节输出流,它的作用是将缓冲区的字节写入到文件中,和FileInputStream类似,主要研究它的构造方法和实例方法。
构造方法
//创建文件输出流以写入由指定的 File对象表示的文件。文件不存在就创建
FileOutputStream(File file)
//创建文件输出流以写入由指定的 File对象表示的文件。文件不创建就创建,boolean表示是否在源文件进行追加。true表示追加,false表示覆盖
FileOutputStream(File file, boolean append)
//同上面类似
FileOutputStream(String name)
//同上面类似
FileOutputStream(String name, boolean append)
实例方法
//关闭此文件输出流并释放与此流相关联的任何系统资源。
void close()
//将 b.length个字节从指定的字节数组写入此文件输出流。
void write(byte[] b)
//将 len字节从位于偏移量 off的指定字节数组写入此文件输出流。
void write(byte[] b, int off, int len)
//将指定的字节写入此文件输出流。
void write(int b)
//刷新
void flush()
实战
问题描述
利用FileInputStream和FileOutputStream 实现文件的复制
基本思路
使用FIleInputStream和FileoutputStream边读边写
代码
package com.lordbao.fileoutputsream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @Author Lord_Bao
* @Date 2020/9/4 15:09
* @Version 1.0
*
* 文件复制
*/
public class Main2 {
public static void main(String[] args) {
try(FileInputStream fis = new FileInputStream("IO/properties/demo1.txt");
FileOutputStream fos=new FileOutputStream("IO/properties/demo2.txt")) {
// 每次读1kb
byte [] byteArr = new byte[1024];
int readCount = 0;
while ((readCount = fis.read(byteArr))!=-1){
fos.write(byteArr,0,readCount);
// fos.write(byteArr);不要用这个方法,可能会多写数据
}
//刷新
fos.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
注意
//不要用这个方法,可能会多写数据
fos.write(byteArr)
2.3FileReader
FileReader就只能来读纯文本,叫做文件字符输入流,只能读字符,同样,只需了解这个类的构造方法和实例方法。
构造方法
FileReader继承自InputStreamReader(转换流),它的底层实际还是FileInputStream,只不过一个读字符,另一个读字节
public FileReader(String fileName) throws FileNotFoundException {
super(new FileInputStream(fileName));
}
public FileReader(File file) throws FileNotFoundException {
super(new FileInputStream(file));
}
实例方法
//关闭流并释放与之相关联的任何系统资源。
void close()
//读一个字符
int read()
//读取最大cubf长度的字符并放到cubf中
int read(char[] cbuf)
//读取length长度的字符并放到以offset下标的cubf数组里
int read(char[] cbuf, int offset, int length)
// 跳过n个字符不读,并返回实际跳过没读的字节数
long skip(long n);
FileReader并没有查看有还剩余几个字符未读的方法。
2.4FileWriter
FileWriter就只能来写入纯文本,叫做文件字符输出流,只能写字符,同样,只需了解这个类的构造方法和实例方法。
构造方法
FileWriter继承自OutputStreamWriter(转换流),它的底层实际还是FileOutputStream,只不过一个写字符,另一个写字节。
public FileWriter(String fileName) throws IOException {
super(new FileOutputStream(fileName));
}
public FileWriter(String fileName, boolean append) throws IOException {
super(new FileOutputStream(fileName, append));
}
public FileWriter(File file) throws IOException {
super(new FileOutputStream(file));
}
public FileWriter(File file, boolean append) throws IOException {
super(new FileOutputStream(file, append));
}
实例方法
//关闭流,先刷新。
void close()
//刷新流
void flush()
//写整个数组
void write(char[] cbuf)
//写入字符数组的一部分
void write(char[] cbuf, int off, int len)
//写一个字符
void write(int c)
//写入整个String
void write(String str)
//写入String的一部分
void write(String str, int off, int len)
2.5文件流总结
1、FileInputStream和FIleReader的其实没什么区别,只不过一个读字节,一个读字符,而且不能发现FileReader的本质就是FileInputStream。
2、FileOutputStream和FIleWriter的其实没什么区别,只不过一个写字节,一个写字符,而且不能发现FileWriter的本质就是FileOutputStream。当然这里需要强调的是:FileWriter有一个方法很好,就是可以写String类型。事实上,所有的Writer都可以写String类型。这是字符流的好处的体现。
3、FileWriter继承自OutputStreamWriter,FileReader继承自InputStreamWriter。这两个后面会提到。
3.缓冲流
其实在上面的关于文件读写时,缓冲数组其实是比较麻烦的事,所以缓冲流被提出来,当然缓冲流不是单独存在的,这里后面会提到到。
3.1BufferedInputSteam
老规矩,看构造方法和实例方法
构造方法
//内部缓冲区 byte的数组
protected volatile byte buf[];
//默认缓冲区的大小是8192个字节,即8k
private static int DEFAULT_BUFFER_SIZE = 8192;
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
可以看出来构造方法需要传入一个InputStream的子类对象。这里其实出现了一个概念,节点流和包装流,上面所示的BufferedInputStream是包装流,而InputStream的子类对象就是节点流。而以后只需要调用最外层的包装流的close方法就可以顺带着释放节点流的相关的资源。
关于缓冲输出流的实例方法,其实和FileInputStream差不多,不过底层代码区别很大,现在看不懂,以后再说吧
// 读一个字节 返回字节的ASCII码值 当无字节可读时,返回-1
int read();
/* 每一次最多读arr.length大小的字节,并存储到arr中
当字节数没有达到arr.length(即文件最后几个字节达不到arr.length时),
这些字节会覆盖掉arr的一部分,而另一部分不会被覆盖掉
该方法返回读到的字节数量,当无字节可读时返回-1
*/
int read(byte [] arr)
/*
每一次最多读len大小的字节,并从off位置开始存储到arr中
该方法返回读到的字节数量,当无字节可读时返回-1
其实这个方法用得还是比较少
*/
int read(byte [] arr,int off ,int len)
//返回文件剩余未读的个数
int available();
// 跳过n个字节不读,并返回实际跳过没读的字节数
long skip(long n);
//关闭与输入流相关的资源
void close()
3.2BufferedOutputStream
查看构造方法和实例域,发现和BufferedInputStream差不多。
protected byte buf[];
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
你会发现和BufferedInputStream出奇类似!
先比较FileReader而言,BufferedReader有一个更腰间盘突出的方法
//此方法会读取一行,并且忽略掉行尾的 \r 或 \n
//当没有行读时,会返回null
String readLine()
3.4BufferedWriter
不用说了,查看实例域和构造方法
private char cb[];
private static int defaultCharBufferSize = 8192;
public BufferedWriter(Writer out) {
this(out, defaultCharBufferSize);
}
public BufferedWriter(Writer out, int sz) {
super(out);
if (sz <= 0)
throw new IllegalArgumentException("Buffer size <= 0");
this.out = out;
cb = new char[sz];
nChars = sz;
nextChar = 0;
lineSeparator = java.security.AccessController.doPrivileged(
new sun.security.action.GetPropertyAction("line.separator"));
}
相比FileWriter,BufferedWriter有一个更突出的方法
//即新起一行
public void newLine()
4.转换流
转换流可以实现将字节流转换为字符流,具体的例子如下所示
package com.lordbao.conclusion;
import java.io.*;
/**
* @Author Lord_Bao
* @Date 2020/9/6 18:49
* @Version 1.0
*/
public class TestInputStreamReaderAndOutputStreamWriter {
public static void main(String[] args) {
try(BufferedWriter bw = new BufferedWriter( new OutputStreamWriter(new FileOutputStream("IO/properties/123.txt")));
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("IO/properties/abc.txt")))) {
//省略一万字
} catch (IOException e) {
e.printStackTrace();
}
}
}
5.数据流
数据流是专门读写数据的,没有字符流,只有字节流,而且存储的数据以纯文本打开是乱码。
5.1DataInputStream
看构造方法
public DataInputStream(InputStream in) {
super(in);
}
可以看出DataInputStream也是一个包装流,而且只有一个有参构造方法。
实例方法
int read(byte[] b) ;
int read(byte[] b, int off, int len) ;
boolean readBoolean() ;
long readLong();
short readShort();
byte readByte() ;
char readChar() ;
double readDouble() ;
float readFloat() ;
int readInt();
DataInputStream可以读取用DataOutputStream写入的文本文件,不过需要注意的是读的顺序一定要和DataOutputStream写入的顺序一样,否则可能出现乱码。
5.2DataoutputStream
构造方法
public DataOutputStream(OutputStream out) {
super(out);
}
和DataInputStream类似
实例方法

见名知义,不废话。
6.标准输出流
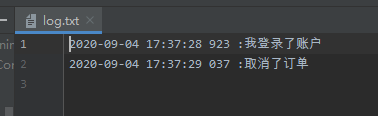
标准输出流分为PrintStream和PrintWriter,标准输出流不需要手动关闭,这里关于这两个类不在详写,不过有个案例可以记住:可以通过修改System的输出到控制台改为输出到文本文件,这样可以模拟日志打印:
Logger
package com.lordbao.util;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @Author Lord_Bao
* @Date 2020/9/4 17:25
* @Version 1.0
*/
public class Logger {
private static PrintStream ps;
static {
try {
//IO/properties/log.txt 目录文件地址
ps = new PrintStream(new FileOutputStream("IO/properties/log.txt",true));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
public static void log(String s){
System.setOut(ps);
Date date = new Date();
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
String dateString = formatter.format(date);
System.out.println(dateString+" :"+s);
}
}
Test
package com.lordbao.printStream;
import com.lordbao.util.Logger;
/**
* @Author Lord_Bao
* @Date 2020/9/4 17:33
* @Version 1.0
*/
public class Main {
public static void main(String[] args) {
Logger.log("我登录了账户");
Logger.log("取消了订单");
}
}
效果
7.File
File是文件和目录名的抽象表示
构造方法
//从父抽象路径名和子路径名字符串创建新的 File实例。
File(File parent, String child) ;
//通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例。
File(String pathname) ;
//从父路径名字符串和子路径名字符串创建新的 File实例。
File(String parent, String child) ;
//通过将给定的 file: URI转换为抽象路径名来创建新的 File实例。
File(URI uri) ;
实例方法
//测试此抽象路径名表示的文件或目录是否存在
boolean exists();
//判断文件是否存在并且是否为目录
boolean isDirectory();
//判读文件是否存在并且是否是普通文件
boolean isFile();
//创建目录
boolean mkdir();
//递归创建子目录
boolean mkdirs();
//创建普通文件
boolean createNewFile() ;
//获得绝对路径
String getAbsolutePath();
//获得父路径
String getParent();
//获得父路径代表的FIle
File getParentFile();
//获得文件的目录或文件名
String getName();
//返回此抽象路径名表示的文件上次修改的时间(自1970年开始的毫秒数)。
long lastModified() ;
// 返回由此抽象路径名表示的文件的长度
long length();
//返回File(此时是特指目录)下的文件或是目录
File[] listFiles()
实战
问题描述
利用FIle 和 FileInputStream 和FileOutputStream实现目录复制
这里我就复制我的项目的IO文件夹
基本思路
利用递归实现目录复制,详细情况见代码
代码如下
package com.lordbao.test;
import java.io.*;
/**
* @Author Lord_Bao
* @Date 2020/9/6 19:50
* @Version 1.0
*
* 将IO目录下的所有文件和目录都复制到IOBAK目录下
*
* 1.判断IOBAK目录是否存在
* 显然 IO目录肯定是存在的,而IOBAK目录则不一定存在
* 所以需要判断IOBAK目录是否存在
*
* 1.首先判断是否存在一个叫IOBAK的文件或是目录 即destFile.exists()
* 如果不存在,则进行递归创建IOBAK目录,为什么是递归创建呢?
* 因为目标目录可能是 xxx/yyy/IOBAK这样的参数,为了程序健壮性,采用递归创建
* 2.如果存在,则需要进一步判断是不是文件 即destFile.isFile
* 如果是文件,由于同名无法创建,那么目标目录必须改为另外一个名字,比如IOBAK(1)。然后递归创建目标目录
* 注意,这里不再考虑IOBAK(1)还存在重名的情况
*
* 其实第1步,自己不要乱设置目标目录就行了。
*
* 2.关于递归函数的参数以及递归终止条件分析如下
* 2.1递归参数
* 首先,第一个参数肯定是等待被复制的目录 即 File sourceFile
* 当然这里传入 等待被复制的目录的路径也可以,没什么区别 即 String sourceFilePath
*
* 其次,第二个参数是第一个参数 File sourceFile下的文件或目录将被复制的目录路径 即 String destPath
*
* 2.2终止条件
* 当sourceFile目录下的都是文件时,递归终止
*/
public class TestCopyDirectoryDemo {
public static void main(String[] args) {
//等待被复制的源目录路径
String sourceDirPath="IO";
//目标目录路径
String destDirPath="IOBAK";
File sourceFile = new File(sourceDirPath);
File destFile = new File(destDirPath);
//如果目标目录不存在.则递归创建目标目录
if (!destFile.exists()){
//递归创建目标目录
destFile.mkdirs();
//如果存在一个重名的文件,则将目标目录改为IOBAK(1),并递归创建目标目录
//这里不考虑还存在一个IOBAK(1)的文件或是目录
}else if (destFile.isFile()){
destDirPath = destDirPath+"(1)";
destFile = new File(destDirPath);
destFile.mkdirs();
}
copy(sourceFile,destDirPath);
}
/**
*
* @param sourceFile 等待被复制的目录
* @param destPath sourceFile下的文件或是目录将被复制的目录路径
*
* 简单来说,就是sourceFile目录下的文件或是目录都要复制到destPath下
*/
private static void copy(File sourceFile ,String destPath){
File[] subFiles = sourceFile.listFiles();
for (File file:subFiles){
//如果文件的话,就复制到destPath下
if (file.isFile()){
//拼接新的目标文件名
String newFileName = destPath+"/"+file.getName();
try(FileInputStream fis = new FileInputStream(file);
FileOutputStream fos = new FileOutputStream(newFileName)) {
//每次读取1Mb
byte [] byteArr = new byte[1024 * 1024];
int readCount;
while ((readCount=fis.read(byteArr))!=-1){
fos.write(byteArr,0,readCount);
}
fos.flush();
} catch (IOException e) {
e.printStackTrace();
}
}else {
//程序进行到此步,说明file是目录,那么就要创建目录
String newDestPath = destPath+"/"+file.getName();
File tempDir = new File(newDestPath);
tempDir.mkdir();
copy(file,newDestPath);
}
}
}
}
执行代码前


执行代码后
















 2454
2454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









