







from nltk.book import * #首先导入包
1. text.concordance(word) # 搜索word的上下文
2. text.similar(word) #还有哪些词出现在相似的上下文中
3. text.common_contexts([word1,word2…]) #搜索两个或以上word共用的上下文
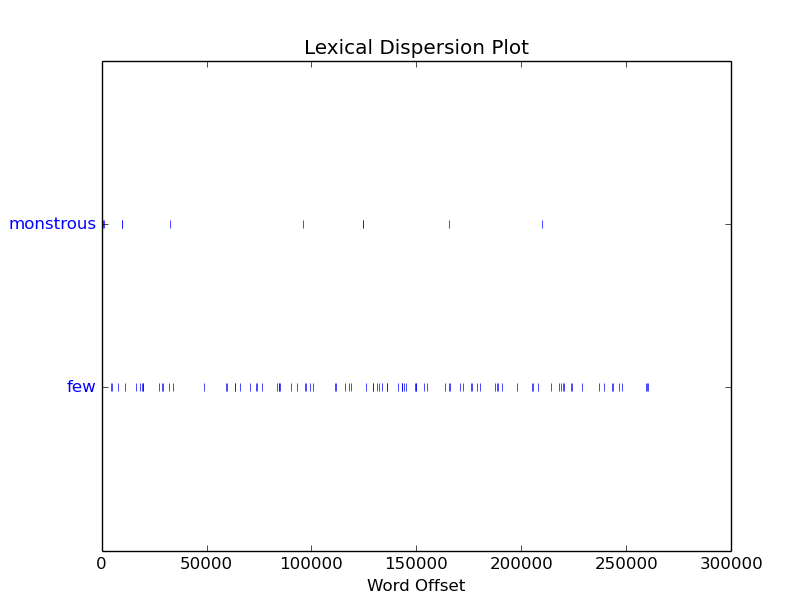
4. text.dispersion_plot([word1, word2,]) #这个函数是用离散图 表示 语料中word 出现的位置序列表示.
5. fdist1 = FreqDist(text) #频率分布
fdist1.hapaxes() #统计只出现一次的词
6. bigrams(list) #提取二元词语(双连词)

text.collocations() #找到频繁的双连词

6. generate()函数:
随机产生文本中的一段文本,每次运行它,输出的文本都会不同。
7.defaultdict() : 默认字典,可赋初值。














 7357
7357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









