







编译链接过程
C/C++程序从文本到可执行文件之间是一个复杂的过程. 对于源代码(.c/.cpp)文件我们是不能直接运行的, 必须经过一系列的处理才能转化为机器语言, 再通过链接相应的文件转化为可执行程序. 这个过程称为编译链接过程. 本文篇幅较长, 想直接看分析过程点击这里
下面是从源代码到可执行文件的整个编译链接的过程:
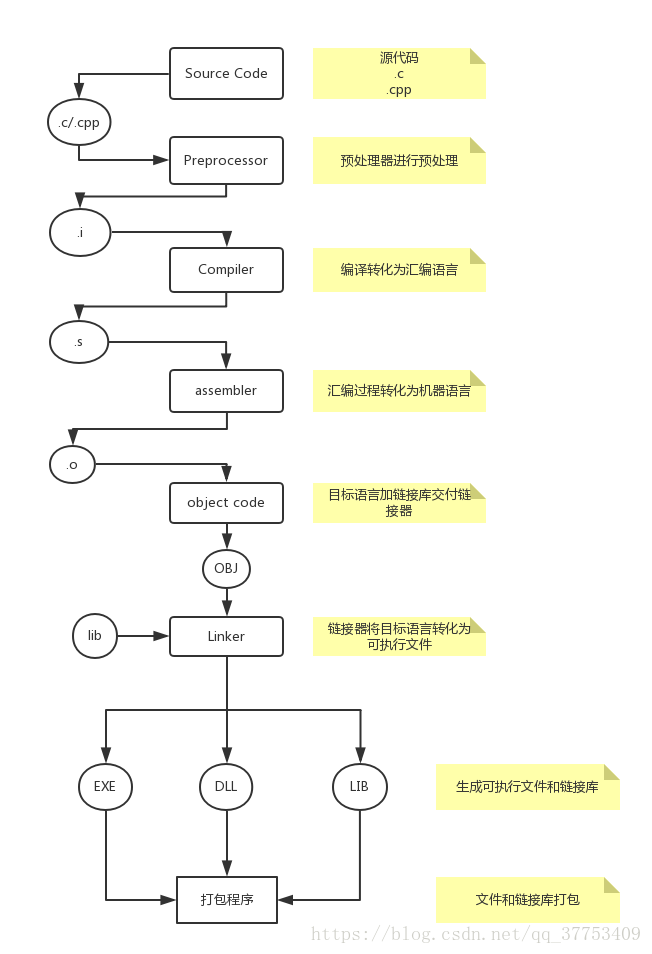
1. 编译过程
C文件编译过程又可分为: 编译 和 汇编
1.1 编译
编译是指编译器读取源程序(字符流), 对之进行词法和语法的分析, 将高级语言指令转换为功能等效的汇编代码.
简而言之就是将 高级语言(我们这里指C源文件) 代码 转化为 汇编代码
高级语言指令转化为汇编代码有需要两个过程:
1.1.1 预处理
预处理过程通过预处理器来完成, 预处理器是程序中处理输入数据,产生能用来输入到其他程序的数据的程序。输出被称为输入数据预处理过的形式,常用在之后的程序比如编译器中.
本文只讨论C预处理器, C预处理器是C语言、C++语言的预处理器。用于在编译器处理程序之前预扫描源代码,完成 头文件的包含, 宏扩展, 条件编译, 行控制(line control) 等操作。
对于C/C++语言预处理一般分为以下几个过程:
1.1.1.1 包含文件
所谓包含文件即为头文件 #include 到的文件, 在预处理的过程中会将其加入到预处理器的输出文件中, 以供编译程序处理.
#include <stdio.h>
int main(void)
{
printf("Hello, world!\n");
return 0;
}1.1.1.2 条件编译
if-else指令包括#if, #ifdef, #ifndef, #else, #elif and #endif .这些指令可以指定不同的宏来决定那些代码执行, 那些不执行. 在预处理的过程中就会将那些不执行的程序进行过滤, 预处理器只输出执行的代码到编译程序中.
#if VERBOSE >= 2
print("trace message");
#endif
#ifdef __unix__ /* __unix__ is usually defined by compilers targeting Unix systems */
# include <unistd.h>
#elif defined _WIN32 /* _WIN32 is usually defined by compilers targeting 32 or 64 bit Windows systems */
# include <windows.h>
#endif1.1.1.3 宏定义与扩展
对于已经定义的宏在进行预处理的过程中直接用已经定义好的宏进行替换, 若定义了 #undef 以后出现的这种宏都不会替换.
#define <identifier> <replacement token list> // object-like macro
#define <identifier>(<parameter list>) <replacement token list> // function-like macro, note parameters
#undef <identifier> // delete the macro1.1.1.4 特殊的宏与指令
对于某些特殊的宏在进行预处理的时候直接进行替换, 比如 C/C++语言定义了标准宏 ____LINE, ____FILE 直接替换为当前行号和文件
#define WHERESTR "[file %s, line %d]: "
#define WHEREARG __FILE__, __LINE__
#define DEBUGPRINT2(...) fprintf(stderr, __VA_ARGS__)
#define DEBUGPRINT(_fmt, ...) DEBUGPRINT2(WHERESTR _fmt, WHEREARG, __VA_ARGS__)1.1.1.5 Token连接
Token即为符号, 可以理解为变量名
使用 ## 运算符(Token Pasting Operator) 可以将两个Token连接成一个Token.
## 运算符左侧或右侧如果是另一个宏名,这个宏名将不会被宏展开,而是按照字面值被当作一个token。因此,如果需要 ## 运算符左右的宏名做宏展开,需要使用两层宏的嵌套使用,其中外层的宏展开时也一并把##运算符左右的宏名做宏展开。
#define DECLARE_STRUCT_TYPE(name) typedef struct name##_s name##_t
DECLARE_STRUCT_TYPE(g_object); // Outputs: typedef struct g_object_s g_object_t;1.1.1.6 用户定义的编译错误与警告
#error "error message"
#warning "warning message"1.1.1.7 编译器相关的预处理特性
#paragm //提供了编译器特定的预处理功能
//openmp
#pragma omp parallel for1.1.2 编译和优化
这个过程即为通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码.
这里进行汇编的过程是通过编译器进行执行的, 在编译器(Compiler)的作用下经过预处理器输入的程序就编译成了汇编代码.
1.2 汇编
汇编的过程实际上就是将汇编代码翻译成目标机器语言的过程. 生成的目标文件也就是与源程序在逻辑上等效的机器语言代码.
生成的机器语言代码被称为目标代码, 生成的二进制文件被称为目标文件, 也成为二进制文件.
典型的生成的目标文件的数据类型为:
符号起始区块(BSS Block Started by Symbol的缩写)
正文段(text segment 或译作代码段)//主要存放程序的指令, 可读可执行不可写
数据段(data segment)//主要存放全局变量和静态数据. 可读可写可执行
2. 链接过程
链接过程是由链接器进行操作的. 链接器(英语:Linker),又译为链接器、连结器,是一个程序,将一个或多个由编译器或汇编器生成的目标文件外加库链接为一个可执行文件。
在编译过程中已经得到了可执行文件, 在这里主要讨论外加库链接. 现在的大多数操作系统都提供静态链接和动态链接这两种链接方式以下是连接过程:
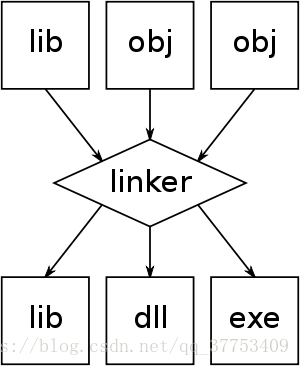
2.1 链接
2.1.1 静态链接(编译时)
链接器将函数的代码从其所在地(目标文件或静态链接库中)拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
优点: 只需保证在开发者的计算机有正确的库文件,在以二进制发布时不需考虑在用户的计算机上库文件是否存在及版本问题.
缺点: 生成的可执行文件体积较大。当初正是为了避免此问题,才开发了动态库技术。2.1.1 动态链接 (加载, 运行时)
所谓动态链接,就是把一些经常会共用的代码(静态链接的OBJ程序库)制作成DLL档,当可执行文件调用到DLL档内的函数时,操作系统才会把DLL档加载存储器内,DLL档本身的结构就是可执行档,当程序有需求时函数才进行链接。透过动态链接方式,存储器浪费的情形将可大幅降低。静态链接库则是直接链接到可执行文件。
DLL档本身也是可执行文件, 在程序执行的时候直接进行动态调用即可.2.1.3 静态链接和动态链接的比较
| 静态链接 | 动态链接 |
|---|---|
| 编译时 | 加载, 运行时 |
| lib在编译时就组装进exe文件 | 程序运行时exe文件可以动态的加载dll |
| 不用考虑计算机库文件版本 | 节省内存, 维护性高 |
| 整个软件包只有exe文件 | 软件包中有exe和dll |
| lib文件是外部函数和变量, 在编译时复制进目标程序, 后缀为.a | dll文件本身是可执行的, 在运行时动态链接, 可以包含源码, 数据, 资源的多种组合, 后缀为.so |
经过链接器的作用形成可执行文件, 最后还要进行一步操作, 进行打包. 即将生成的可执行文件(.exe, .dll, .lib)文件进行打包. 交付给计算机即可运行.
3. 编译链接过程分析
我们创建三个文件分别为test.h, test.c和main.c
//test.c文件
#include <stdio.h>
#define __PI__ 3.141592654
void print_hello(){
printf("hello world!\n");
}
void print_string(char *s){
printf("%s\n", s);
}
double getArea(int r){
return r*r*__PI__;
}
//-------------------------------------------------
//test.h文件
//test.h
void print_hello();
void print_string(char *s);
double getArea(int r);
//-------------------------------------------------
//main.c文件
#include "test.h"
#define __HELLO__ print_hello();
#define __TEMP__ print_string("hello c!");
int main(){
//test.h --> hello
print_hello();
//__HELLO__
__HELLO__
//__TEMP__
__TEMP__
}
3.1 预处理操作
gcc -E main.c | tee main.i预处理代码 main.i
# 1 "main.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "main.c"
# 1 "test.h" 1
void print_hello();
void print_string(char *s);
double getArea(int r);
# 2 "main.c" 2
int main(){
print_hello();
print_hello();
print_string("hello c!");
}可以发现, 预处理操作将定义的宏全部展开, 包含头文件, 去掉注释等 具体的预处理操作详见1.1.1
3.2 编译
gcc -S main.c编译生成后缀为.s的汇编代码, 拿出main函数来分析以下
_main:
LFB13:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $16, %esp
call ___main
call _print_hello //调用_print_hello函数
call _print_hello //调用_print_hello函数
movl $LC3, (%esp)
call _print_string //调用_print_string函数
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc3.2 汇编
//对于.c文件
gcc -c main.c
gcc -c test.c3.2 链接
对于得到的上一步汇编得到的.o文件我们进行链接.
gcc -o main main.o这里发现报错了.
main.o:main.c:(.text+0xf): undefined reference to `print_hello'
main.o:main.c:(.text+0x14): undefined reference to `print_hello'
main.o:main.c:(.text+0x20): undefined reference to `print_string是因为test.o文件没有打包成我们需要的lib格式文件, 即.a后缀的文件. 进行打包. 打包后的test.a
ar -rc test.a test.o再次链接
gcc -o main main.o ./test.a链接成功, 执行main.exe
hello world!
hello world!
hello c!代码在我的个人博客里, 请访问YancyKahn
以上就是整个编译链接的过程了, 喜欢的话点个赞.
参考文献
[1.] http://blog.51cto.com/7905648/1297255
[2.] http://www.ruanyifeng.com/blog/2014/11/compiler.html
[3.] https://blog.csdn.net/shenjianxz/article/details/52130111
[4.] https://zh.wikipedia.org/wiki/C预处理器
[5.] https://zh.wikipedia.org/wiki/%E7%9B%AE%E6%A0%87%E4%BB%A3%E7%A0%81
[6.] https://zh.wikipedia.org/wiki/%E9%93%BE%E6%8E%A5%E5%99%A8
[7.] https://blog.csdn.net/shaderdx/article/details/49929147














 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









