







深度学习模型压缩和加速算法的三个方向,分别为加速网络结构设计、模型裁剪与稀疏化、量化加速
目前在深度学习领域分类两个派别,一派为学院派,研究强大、复杂的模型网络和实验方法,为了追求更高的性能;另一派为工程派,旨在将算法更稳定、高效的落地在硬件平台上,效率是其追求的目标。复杂的模型固然具有更好的性能,但是高额的存储空间、计算资源消耗是使其难以有效的应用在各硬件平台上的重要原因。所以,卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,深度学习模型压缩与加速成为了学术界和工业界都重点关注的研究领域之一。本文主要介绍深度学习模型压缩和加速算法的三个方向,分别为加速网络结构设计、模型裁剪与稀疏化、量化加速。
关键词:深度学习、模型压缩、模型加速
I.加速网络设计
分组卷积
分组卷积即将输入的feature maps分成不同的组(沿channel维度进行分组),然后对不同的组分别进行卷积操作,即每一个卷积核至于输入的feature maps的其中一组进行连接,而普通的卷积操作是与所有的feature maps进行连接计算。分组数k越多,卷积操作的总参数量和总计算量就越少(减少k倍)。然而分组卷积有一个致命的缺点就是不同分组的通道间减少了信息流通,即输出的feature maps只考虑了输入特征的部分信息,因此在实际应用的时候会在分组卷积之后进行信息融合操作,接下来主要讲两个比较经典的结构,ShuffleNet[1]和MobileNet[2]结构。
1)ShuffleNet结构:
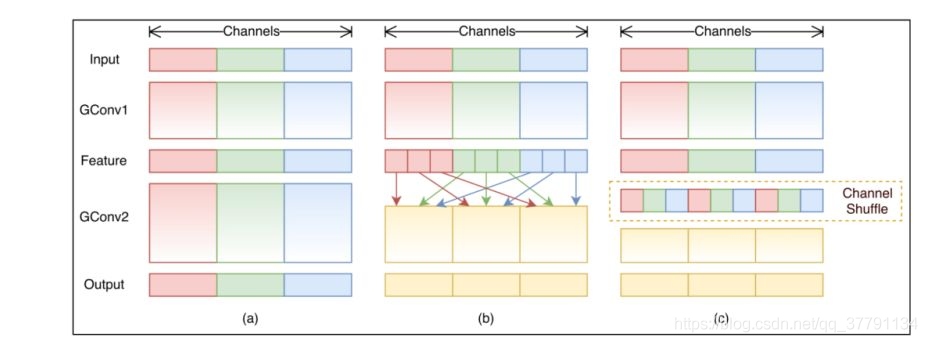
如上图所示,图a是一般的group convolution的实现效果,其造成的问题是,输出通道只和输入的某些通道有关,导致全局信息 流通不畅,网络表达能力不足。图b就是shufflenet结构,即通过均匀排列,把group convolution后的feature map按通道进行均匀混合,这样就可以更好的获取全局信息了。图c是操作后的等价效果图。在分组卷积的时候,每一个卷积核操作的通道数减少,所以可以大量减少计算量。
2)MobileNet结构:
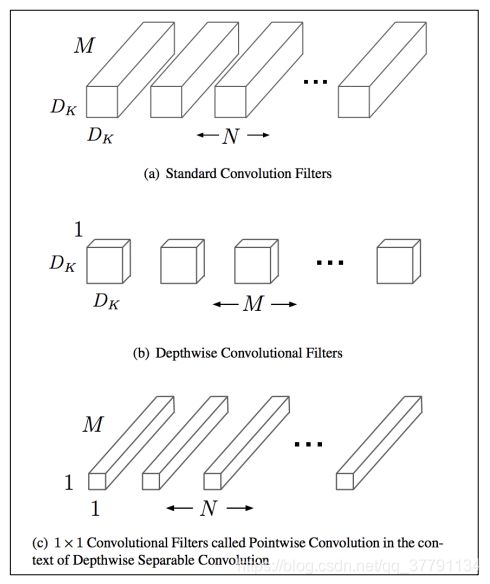
如上图所示,mobilenet采用了depthwise separable convolutions的思想,采用depthwise (或叫channelwise)和1x1 pointwise的方法进行分解卷积。其中depthwise separable convolutions即对每一个通道进行卷积操作,可以看成是每组只有一个通道的分组卷积,最后使用开销较小的1x1卷积进行通道融合,可以大大减少计算量。
分解卷积
分解卷积,即将普通的kxk卷积分解为kx1和1xk卷积,通过这种方式可以在感受野相同的时候大量减少计算量,同时也减少了参数量,在某种程度上可以看成是使用2k个参数模拟k*k个参数的卷积效果,从而造成网络的容量减小,但是可以在较少损失精度的前提下,达到网络加速的效果。
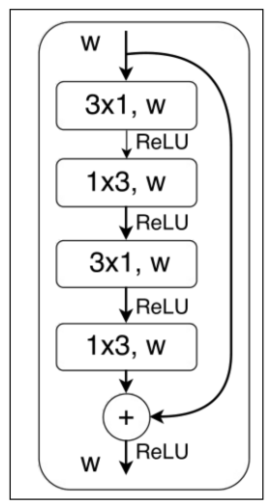
右图是在图像语义分割任务上取得非常好的效果的ERFNet[3]的主要模块,称为NonBottleNeck结构借鉴自ResNet[4]中的Non-Bottleneck结构,相应改进为使用分解卷积替换标准卷积,这样可以减少一定的参数和计算量,使网络更趋近于efficiency。
Bottleneck结构
右图为ENet[5]中的Bottleneck结构,借鉴自ResNet中的Bottleneck结构,主要是通过1x1卷积进行降维和升维,能在一定程度上能够减少计算量和参数量。其中1x1卷积操作的参数量和计算量少,使用其进行网络的降维和升维操作(减少或者增加通道数)的开销比较小,从而能够达到网络加速的目
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









