







Java Database Connectivity (JDBC) API 是 J2EE 的一部分,是 Java 语言访问关系数据库的基于标准的首要机制,提供了对数据库访问和缓存管理的直接控制。
JDBC 中的 CallableStatement 对象为所有的关系数据库管理系统 (RDBMS: Relational Database Management System) 提供了一种标准形式调用存储过程的方法。对存储过程的调用有两种形式:带结果参数和不带结果参数。结果参数是一种输出参数,是存储过程的返回值。两种形式都可带有数量可变的输入(IN 参数)、输出(OUT 参数)或输入和输出(INOUT 参数)的参数。
在 JDBC 中调用存储过程的语法为:{call procedure_name[(?, ?, …)]};返回结果参数的存储过程的语法为:{? = call procedure_name[(?, ?, …)]};不带参数的存储过程的语法为:{call procedure_name}。其中,问号代表参数,方括号表示其间的内容是可选项。
使用 CallableStatement 对象调用存储过程的过程如下:
- 使用 Connection.prepareCall 方法创建一个 CallableStatement 对象。
- 使用 CallableStatement.setXXX 方法给输入参数(IN)赋值。
- 使用 CallableStatement.registerOutParameter 方法来指明哪些参数只做输出参数(OUT),哪些是输入输出参数(INOUT)。
- 调用以下方法之一来调用存储过程:
- int CallableStatement.executeUpdate: 存储过程不返回结果集。
- ResultSet CallableStatement.executeQuery: 存储过程返回一个结果集。
- Boolean CallableStatement.execute: 存储过程返回多个结果集。
- int[] CallableStatement.executeBatch: 提交批处理命令到数据库执行。
- 如果存储过程返回结果集,则得到其结果集。
- 调用 CallableStatement.getXXX 方法从输出参数 (OUT) 或者输入输出参数 (INOUT) 取值。
- 使用完 CallableStatement 对象后,使用 CallableStatement.close 方法关闭 CallableStatement 对象。
举例:清单 1. 使用 executeUpdate 来执行的存储过程
Connection con = null;
...
// Create a CallableStatement object
CallableStatement cstmt = con.prepareCall("CALL exampleJDBC (?, ?, ?, ?, ?)");
cstmt.setString (1, “BeiJing”); // Set input parameter
cstmt.setInt (2, 2008); // Set input parameter
cstmt.registerOutParameter (3, Types.INTEGER);
cstmt.registerOutParameter (4, Types.INTEGER);
cstmt.registerOutParameter (5, Types.VARCHAR);
cstmt.executeUpdate(); // Call the stored procedure
int goldnumber = cstmt.getInt(3); // Get the output parameter values
int silvernumber = cstmt.getInt(4);
String errorinfo = cstmt.getString(5);
cstmt.close(); |
当存储过程返回一个结果集时,只需遍历该结果集便可以得到存储过程执行的所有结果。具体例子见清单2。
清单 2. 存储过程返回一个结果集
CallableStatement cstmt = null;
…
boolean moreResultSets = cstmt.execute();
ResultSet rs1 = cstmt.getResultSet();
while (rs1.next())
System.out.println(rs1.getString(1) + " " + rs1.getString(2)); |
当存储过程返回多个结果集时,遍历所有结果集才能得到执行的所有结果,使用 getMoreResults() 方法跳转到下一个结果集。具体例子见清单3。
清单 3. 存储过程返回多个结果集
CallableStatement cstmt = null;
…
While (cstmt.getMoreResults()) {
ResultSet rs2 = cstmt.getResultSet();
while (rs2.next())
System.out.println(rs2.getString(1) + " " + rs2.getString(2));
rs2.close();
} |
如果存储过程返回多个结果集,每个结果集的数据结构都不一样,或者某些结果集的数据结构未知,则可以使用 getColumnName() 方法来得到结果集中数据的列名。具体例子见清单 4。
清单 4. 存储过程返回多个结果集,并且每个结果集的数据结构未知或者不一样
CallableStatement cstmt = null;
…
boolean moreResultSets = cstmt.execute();
while (moreResultSets) {
ResultSet rs = cstmt.getResultSet();
ResultSetMetaData rsmd = rs.getMetaData();
StringBuffer buffer = new StringBuffer();
for (int i = 1; i <= rsmd.getColumnCount(); i++){
buffer.append(rsmd.getColumnName(i)).append("/t");
System.out.println(buffer.toString());
while (rs.next()) {
buffer.setLength(0);
for (int i = 1; i <= rsmd.getColumnCount(); i++)
buffer.append(rs.getString(i)).append("/t");
System.out.println(buffer.toString());
}
}
rs.close();
moreResultSets = cstmt.getMoreResults();
} |
适用场景:2. 使用 IBM DB Beans 调用存储过程
多年来 JDBC 一直是 Java 开发人员进行数据访问的标准,这是一种稳定且被广泛证实的技术,目前已经发展成可以提供完全具有高速缓存和资源池机制的完善的数据库驱动程序。使用 JDBC 来调用存储过程是最常见的一种方式,由于 JDBC 是最接近于数据库的 API,因而其效率也是最高的。CallableStatement 对象为所有的 DBMS 提供了标准形式调用存储过程的方法,对于要求实现灵活,执行效率要求比较高应用,直接采用 JDBC API 来实现存储过程能很好地满足需要。
JDBC API 是 J2EE 定义的访问后端数据库的标准 API,在 JDBC 的基础上,IBM WebSphere 部门从 WebSphere Application Server 5.0 开始提供了一个扩展的数据库访问框架 IBM DB Beans。这个框架提供了 JDBC 所不具有的众多扩展功能,包括带参数的查询、跨越多个事务的结果集缓冲以及通过缓冲执行更新、元数据映射等等,同时它也隐藏了用 JDBC 访问后端数据库时必须涉及的许多复杂细节,被设计成支持任何支持 JDBC 的数据源,使得 Bean与各种 DBMS 无关。
WebSphere 的数据库访问扩展框架的 API 可以在 IBM 基于 Eclipse 的各种集成开发工具的 plugins 目录下找到,通常为 plugins 目录下插件 com.ibm.datatools.dbjars 所在目录下的 dbbeans.jar 文件中,开发时只要把这个 jar 文件放入项目的编译路径就可以使用。
在 IBM 扩展的数据库访问框架中,DBProcedureCall 对象用于调用后端数据库的存储过程,并管理存储过程的执行结果。调用 DBStatement.setConnectionSpec() 可以设置 SQL 命令的连接属性,由于这一机制,同一个连接属性设置可用于一个以上的 SQL 命令。
DBProcedureCall 继承自 DBStatement,通过 DBProcedureCall 调用存储过程时,获取元数据使用 DBStatement 的 getParameterMetaData() 方法。参数可以是自定义的 Java 类,也可以是 Java 的标准数据类型;如果要将 Java 数据类型映射到数据库字段类型,这一机制是非常有用的。下面是一个例子:
举例:清单 5. 使用 DBProcedureCall 调用存储过程
DBProcedureCall procCall = null;
DBParameterMetaData parmMetaData = null;
try {
// Create DatabaseConnection object and set its properties
procCall = new DBProcedureCall();
// Connect to database via DataSource object
procCall.setDataSourceName("jdbc/sample");
// Set user name and password
procCall.setUsername(userid);
procCall.setPassword(password);
// Make it auto commit
procCall.setAutoCommit(false);
// Set SQL statement
procCall.setCommand("{ CALL DB2ADMIN.INSERTORDER (:ORDERID,:DATE) }");
// Get DBParameterMetaData object and set its properties
parmMetaData = procCall.getParameterMetaData();
parmMetaData.setParameter(1, "ORDERID",
java.sql.DatabaseMetaData.procedureColumnIn,
java.sql.Types.CHAR, String.class);
parmMetaData.setParameter(2, "DATE",
java.sql.DatabaseMetaData.procedureColumnIn,
java.sql.Types.CHAR, String.class);
// Set input parameter for stored procedure
procCall.setParameter("ORDERID", order);
procCall.setParameter("DATE", date);
// Execute stored procedure
procCall.execute();
// Return DBProcedureCall object
return procCall;
} catch (Exception ex) {
ex.printStackTrace();
} finally {
// Release resource used by DBProcedureCall
try {
if (procCall != null)
procCall.close();
} catch (java.sql.SQLException ex) {
}
} |
IBM 集成开发环境 RDA(Rational Data Architect) 提供了对 DB Beans 的支持,能够图形化地生成 DB Beans 的绝大部分代码。RDA 是 IBM 提供的企业数据建模和整合设计工具,旨在帮助数据架构师理解数据资产及其关系,设计联邦数据库,以及流线化数据库项目,能够帮助数据架构师发现、建模、可视化、关联和开发异构数据资产。更多关于 RDA 的使用参见参考文献。
适用场景:3. WebShpere Adapter for JDBC 发现和访问存储过程
IBM 数据库访问框架提供了丰富的扩展功能,例如带参数的查询、结果集缓冲以及通过缓冲执行更新、元数据映射,等等,同时它也隐藏了用 JDBC 访问后端数据库时必须涉及的许多复杂细节,这种方式使开发人员不用针对各种 JDBC 应用单独实现这些功能。
J2EE Connector Architecture (JCA) 1.5标准定义了资源适配器 (Resource Adapter) 组件规范,使J2EE应用程序可以通过标准接口和各种企业信息系统(EIS: Enterprise Information System)交互,如ERP 系统、SCM 系统以及各种数据库系统等等,以便获取所需的数据和服务。
基于 JCA 标准,IBM 提供了 WebShpere Adapter 实现 J2EE 组件和 EIS 之间数据的交互。WebShpere Adapter 可以部署在 WebSphere 业务流程服务器 WPS (WebSphere Process Server) 或者 WebSphere 企业服务总线 ESB (WebSphere Enterprise Service Bus) 上,以连接服务器上的 J2EE 应用程序和 EIS,如图 1。
图 1. 部署在 WPS 上的 IBM WebSphere Adapter
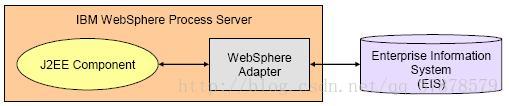
WebShpere Adapter 可以分为两类:Application Adapters 和 Technology Adapters。Application Adapters 是针对各种特定 EIS 的适配器,如 SAP, Siebel, Peoplesoft 和 Oracle eBusiness Suite 等;Technology Adapters 是针对实现某种技术的 EIS 系统,如 WebSphere Adapter for JDBC、Mail 适配器、Text 适配器和 XML 适配器。
WebSphere Adapter for JDBC 是一种提供 J2EE 应用和支持 JDBC 2.0 的数据库系统之间的连接的 WebShpere Adapter,属于 Technology Adapters。WebSphere Adapter for JDBC 使用业务对象 (BO: Business Object) 的形式来传递数据,提供了 Inbound 和 Outbound 两种方式。其工作机制见图 2。
WebSphere Adapter for JDBC 的工作机制:
图 2. WebSphere Adapter for JDBC 的工作机制
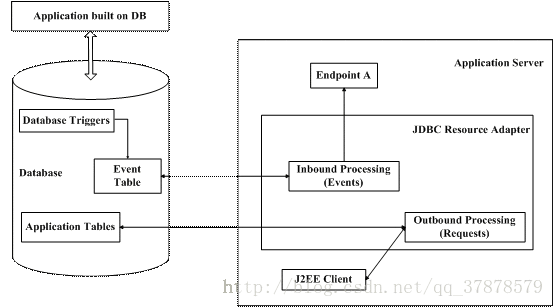
对于 Outbound 操作,J2EE 应用程序产生 BO,并将其传递给 WebSphere Adapter for JDBC,Adapter 根据 BO 中指定的操作,比如增加、删除、修改,查找,创建记录等操作,访问其连接的数据库并进行响应的操作。
对于 Inbound 操作,数据库中的数据通过某个 EIS 得到了更新,这个更新通过触发器或者其他方式被捕获,将这个事件和相应的事件信息插入到一个 “EventStore” 表中。Adapter 会监测 Event Table 中的数据,将每个事件构建成一个 Business Graph 并发送到订阅相应的数据表改变事件的 J2EE 应用程序中。
使用 IBM Websphere 集成开发环境 WID (Websphere Integration Developer) 能够开发各种 WebShpere Adapter 的组件。WID 实现了企业元数据发现(EMD: Enterprise Metadata Discovery)规范,使用企业服务发现器(ESD: Enterprise Service Discovery)来连接各种 EIS,以发现其上存在的数据和服务,并自动产生相应的访问接口。有关企业元数据发现规范和企业服务发现器的详细介绍,请看后面的参考资料。
WebSphere Adapter for JDBC 的 Outbound 操作能够自动发现数据库中的存储过程,并生成相应的业务对象和接口。这样 J2EE 应用程序只需要使用生成的业务对象和接口就可以调用数据库中的存储过程。使用 WID 创建针对存储过程的 Outbound 组件原理和步骤如下:
- 在WID中创建商业模块(Business Module):切换到Business Integration视图下,创建一个商业模块,之后创建的EIS的Outbound组件将成为这个商业模块的一部分。
- 导入 JDBC 资源适配器:将 JDBC Adapter 的 CWYBC_JDBC.RAR 文件导入到 WID 中,这个文件既包括了实现了 JCA 标准的 JDBC 适配器,也包括了企业服务发现器的文件。通常可以在下面的路径中找到这个文件:<WIDInstallDIR>/Resource Adapters/JDBC/deploy。
- 创建企业服务发现向导,并使用其创建业务对象和接口与设置连接属性:主要包括如下内容:
- 设置连接数据库属性,包括用户名,密码,数据库 URL 和 JDBC 驱动等。
- 企业服务发现器使用上述连接属性,连接到现有数据库中,自动发现数据库中的数据库表,视图,存储过程等数据库对象。
- 从发现的结果中选择某个数据库对象,设置适配器的连接方式为Outbound,企业服务发现器将创建业务对象和相应的接口。在这里,我们选择存储过程这种数据库对象。
- 设置WebSphere Adapter for JDBC运行时需要的连接属性,可以通过设置JNDI名和设置激活认证别名两种方式。使用激活别名认证方式时,大部分属性必须在创建JDBCAdapter 项目时指定,使用JNDI名认证时,这些属性需要在配制运行环境时在WPS管理控制台设置。
举例:图 3. 使用 IBM WID 生成的 WebSphere Adapter for JDBC EIS 导出组件
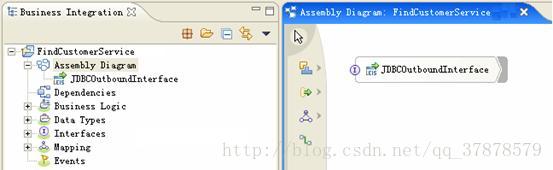
需要说明的是,对于需要 7*24 小时的应用或者对于含有多个适配器的应用,推荐使用 JNDI 方式设置WebSphere Adapter for JDBC 运行时需要的连接属性。这样的话,当数据库发生变化,例如数据库迁移,用户名密码变更等,只需要动态修改 WPS 中 JNDI 的配置信息即可,无需重新部署和启动适配器所在的商业模块也无需修改每个适配器。
IBM WebSphere Adapter for JDBC 将存储过程自动生成一系列的业务对象和接口供开发人员使用,数据库充当服务提供程序或者使用者,开发人员只需要处理 Inbound 和 Outbound 即可。这种方式适用于数据库结构已经固定,不会再有显著变化的情况,比如对现有系统或者遗留的整合或者再次开发。假如在一个新项目中大量采用WebSphere Adapter for JDBC 这种方式,很可能反而降低开发效率,尤其不推荐将这种方式用于极限编程。当用户的需求或者数据库表结构经常不断变化时,使用 IBM WebSphere Adapter 进行开发的成本将大大提高,因为数据库表的每一次变化都会导致需要重新生成 WebSphere Adapter for JDBC 的 Inbound 或者 Outbound 组件,业务对象和接口的变化进而导致调用这些组件的模块也需要重新进行修改。
随着 Web Service 的广泛使用,Web Service 已经成为了异构系统服务相互调用的事实标准。各种语言各种环境下的服务都可以封装成 Web Service,暴露给别人使用,存储过程也不例外。
在这方面,IBM 和微软一直是先行者。IBM 开发了 Web 服务对象运行时框架 WORF(Web service Object Runtime Frameworks),WORF 支持使用 DB2 作为 Web 服务提供程序,可以很容易地将数据库数据和存储过程暴露为 Web 服务。微软提供了 SQLXML 3.0(SQL Server 2000 Web Release 3)来实现该功能。SQLXML 3.0 使你能够从数据库中选择存储过程并从虚拟目录中选择 XML 模版,把它们暴露为 Web 服务的方法。
在介绍 WORF 之前,先介绍几个概念:DAD, DXX, DADX。
DAD(Document Access Definition)即文档访问定义,是一种定义 XML 与关系数据之间的映射的 XML 文档格式,通过DAD文件可以将XML文件中的数据映射到数据库中来,见图4。DAD使用DTD来定义其文件结构,更多关于DAD的内容可以阅读参考资料中DB2 XML Extender相关的链接。
图 4. 通过 DAD 文件实现 XML 文件和 DB2 数据的映射
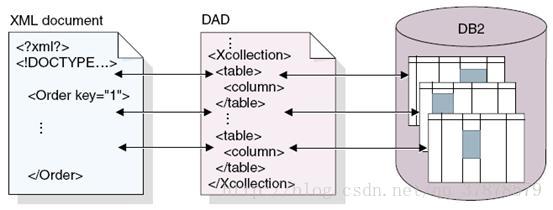
DXX(DB2 XML Extender)为 DB2 提供了一组新的数据类型、函数和存储过程,用于存储和访问 XML 文档,从关系数据生成 XML 文档或者将 XML 文档分解成关系数据。DB2 XML Extender 使用 DAD 来定义 XML 和关系数据之间的映射。
DADX(Document Access Definition Extension)即文档访问定义扩展,是一种指定如何通过使用由 DAD 文档和 SQL 语句定义的操作来创建 Web 服务的 XML 文档格式,目前其规范版本为 DADX1.0。
下面是一个简单的 DADX 文件,这个 DADX 文件定义了一个名字为 findCustomer 的操作,其操作是查询Customer 表中的所有记录。
清单 6. DADX 文件示例
<?xml version="1.0" encoding="UTF-8"?> <DADX xmlns="http://schemas.ibm.com/db2/dxx/dadx" > <documentation> A simple DADX example that accesses the Company database. </documentation> <operation name="findCustomer"> <documentation> Lists all the customers. </documentation> <query> <SQL_query>SELECT * FROM Customer</SQL_query> </query> </operation> </DADX> |
WORF 提供了一个构建 XML Web 服务和访问 DB2 的环境,这个环境包含在 IBM WID 中,也可以单独下载。WORF 使用 DADX 文件描述可以通过 Internet 调用的 SQL 操作;支持通过 HTTP GET、POST 和 SOAP 绑定访问服务,当收到一个服务请求时,WORF 将装载请求中指定的 DADX 文件,连接到 DB2,运行 SQL 语句,并提交数据库事务。它将把结果格式化成 XML,必要时转换数据类型,然后把响应返回给请求者。
DAD 和 DADX 都是 IBM 定义的 XML 文档格式,目前主要用于 IBM DB2 产品中,这一点从 DADX 的命名空间 “http://schemas.ibm.com/db2/dxx/dadx” 看出。只有安装上 DB2 XML Extender 之后,DB2 才能支持 XML 和 DB2 关系数据之间的映射。DAD, DADX, DB2 XML Extender 以及 WORF 四者之间的关系如下:
图 5. DAD, DADX, DB2 XML Extender, WORF 四者之间的关系
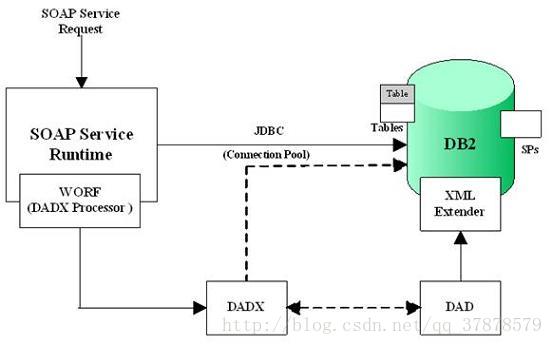
从 SQL 语句或存储过程创建 Web Service 过程主要分为两步:第一步是使用 WID 从 SQL 语句或存储过程创建一个 DADX 文件;第二步是从 DADX 文件创建 Web 服务,包括生成 WSDL 服务描述。这里只是对其原理作进行介绍,更详细步骤可见参考文献。
在分布式应用,多个系统的业务整合等情况下,使用 DADX 将存储过程封装成 Web Service 暴露给其他系统使用是一种不错的方法。通过 IBM 提供的 WORF, DADX, WID 等工具和规范,不需要对 SOAP,WSDL,JDBC 等有太多的了解,也不需要编写复杂和费时的代码,即可快速地将 DB2 以数据提供者或数据消费者的方式,集成到企业应用程序和应用环境中,这在相当程度上简化了开发过程,能帮助企业面对需求迅速做出响应,实现自己 SOA 解决方案。由于 XML 对于 Web 服务的运行是必不可少的一部分,因此 XML 处理的开销会引起性能方面的代价,对于单机应用程序以及要求快速响应的系统,将存储过程暴露成 Web Service 将会抵消掉存储过程高效的优点,并不是一种较好的方案。
EJB(Enterprise Java Bean)是 Sun 推出的 java 平台上的服务器端组件。EJB 技术能够加速和简化基于 java 技术的分布式、事务性的、安全的和可移植性的应用开发,主要用于企业级应用中。EJB 包括实体 Bean,会话 Bean 和消息驱动 Bean。
其中,实体 Bean 主要用来实现数据的持久化。会话 EJB 在 J2EE 应用程序中被用来完成一些服务器端的业务操作,例如访问数据库、调用其他 EJB 组件。实体 Bean 因其设计复杂,消耗大量的资源等缺点而声名狼藉。因而,在实际应用中,应该尽可能少地使用实体 Bean,其中,一种解决方案就是使用会话 Bean 和 JDBC 或者 IBM DB Beans 的组合方式,使用 JDBC 或者 IBM DB Beans 来调用存储过程。参考文献中的《将 DBMS 存储过程封装为会话 EJB 组件中的方法》详细介绍了如何将使用会话 Bean 和 IBM DB Beans 结合的方式来封装 DBMS 存储过程。
在使用会话 Bean 和 JDBC 或者 IBM DB Beans 的组合方式时,会话 Bean 将对数据库的所有访问委托给 JDBC 或者 IBM DB Beans 来实现。这种方式相对于实体 Bean 来说,能使开发人员对数据管理有细粒度的控制权,利用成熟和灵活的 JDBC 或者 IBM DB Beans 数据库管理访问技术,容易进行功能优化,并将这些功能全部封装成一个相对简单的组件体系结构中。
其缺点在于,与 JDBC 或者 IBM DB Beans 结合的会话 Bean 有三个关键问题:Bean 的实现通常比较复杂;会话 Bean 需要开发人员实现自己的事务支持;持久性也需要开发人员自己控制,无法由容器提供和保障。
相对于实体 Bean,使用会话 Bean 和 JDBC 或者 IBM DB Beans 的组合方式来封装 DBMS 存储过程具有灵活性高,资源消耗小等优点。这种方式对于不需要事务支持的业务流程或者只是对数据库进行查询操作的存储过程,是一种比较好的选择。
上述操作完成之后便可以在商业模块的装配图(Assembly Diagram)中看到一个 EIS 的 Outbound 组件。图 3 是一个创建成功的 EIS 的 Outbound 组件的效果图。存储过程的输入和输出参数自动映射为业务对象,存储过程的方法自动映射为组件的接口。用户使用时,只需要将输入参数封装成相应业务对象,调用该组件提供的接口即可。
清单1是一个使用 executeUpdate 来执行的存储过程的例子。存储过程名为 exampleJDBC,含有五个参数,前两个分别是 String 和 Int 类型的输入参数,后三个分别是整型,整型和字符型的输出参数。分别给输入参数赋值 ”Beijing” 和 2008,执行 executeUpdate 命令后,从后三个输出参数中可以得到输出值,没有结果集返回。需要说明的是,这里的参数下标是以 1 开始的,与 java 数组下标以 0 开始不同。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









