







一.共享栈
原理:
想要一个数组实现两个栈,那么就必须一个栈的栈顶从数组下标为0处开始,另一个栈从数组额最大下标处开始,两个栈相对而生如下图所示:

如何判断栈满?
当两个栈顶标记重合时,表示共享栈已经满了
代码如下:
头文件ShareStack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
typedef char StackType;
typedef struct ShareStack{
StackType* space;
size_t size_left;
size_t size_right;
size_t max_size;
}ShareStack;
void ShareStackInit(ShareStack* stack); //共享栈的初始化
void ShareStackDestroy(ShareStack* stack); //销毁共享栈
//对左边栈进行操作
void LeftShareStackPush(ShareStack* stack, StackType value);//入栈
void LeftShareStackPop(ShareStack* stack); //出栈
int LeftShareStackTop(ShareStack* stack, StackType* value); //取栈顶元素
//对右边栈进行操作
void RightShareStackPush(ShareStack* stack, StackType value); //入栈
void RightShareStackPop(ShareStack* stack); //出栈
int RightShareStackTop(ShareStack* stack, StackType* value);//取栈顶元素
头文件的实现ShareStack.c:
#include"ShareStack.h"
void ShareStackInit(ShareStack* stack) {
if(stack == NULL) {
return;
}
stack->max_size = 10;
stack->size_left = 0;
stack->size_right = stack->max_size;
stack->space = malloc(stack->max_size * sizeof(ShareStack));
return;
}
void ShareStackDestroy(ShareStack* stack) {
if(stack == NULL) {
return;
}
stack->max_size = 0;
stack->size_left = 0;
stack->size_right = 0;
free(stack->space);
stack->space = NULL;
}
void LeftShareStackPush(ShareStack* stack, StackType value) {
if(stack == NULL) {
return;
}
if(stack->size_left == stack->size_right) {
return;
}
stack->space[stack->size_left] = value;
stack->size_left++;
return;
}
void LeftShareStackPop(ShareStack* stack) {
if(stack == NULL) {
return;
}
if(stack->size_left == 0) {
return;
}
stack->size_left--;
return;
}
int LeftShareStackTop(ShareStack* stack, StackType* value) {
if(stack == NULL || value == NULL) {
return 0;
}
if(stack->size_left == 0) {
return 0;
}
*value = stack->space[stack->size_left - 1];
return 1;
}
void RightShareStackPush(ShareStack* stack, StackType value) {
if(stack == NULL) {
return;
}
if(stack->size_left == stack->size_right) {
return;
}
stack->size_right--;
stack->space[stack->size_right] = value;
return;
}
void RightShareStackPop(ShareStack* stack) {
if(stack == NULL) {
return;
}
if(stack->size_left == stack->max_size) {
return;
}
stack->size_right++;
return;
}
int RightShareStackTop(ShareStack* stack, StackType* value) {
if(stack == NULL || value == NULL) {
return 0;
}
if(stack->size_right == stack->max_size) {
return 0;
}
*value = stack->space[stack->size_right];
return 1;
}
///
//以下为测试代码
///
void TestShareStack() {
int ret;
StackType value;
ShareStack stack;
ShareStackInit(&stack);
printf("LeftStack:\n");
LeftShareStackPush(&stack, 'a');
LeftShareStackPush(&stack, 'b');
LeftShareStackPush(&stack, 'c');
LeftShareStackPush(&stack, 'd');
ret = LeftShareStackTop(&stack, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect d, actual %c\n", value);
LeftShareStackPop(&stack);
ret = LeftShareStackTop(&stack, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect c, actual %c\n", value);
LeftShareStackPop(&stack);
ret = LeftShareStackTop(&stack, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect b, actual %c\n", value);
LeftShareStackPop(&stack);
ret = LeftShareStackTop(&stack, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect a, actual %c\n", value);
LeftShareStackPop(&stack);
ret = LeftShareStackTop(&stack, &value); //对空栈进行取栈顶元素
LeftShareStackPop(&stack); //对空栈出栈
printf("ret expect 0, actual %d\n", ret);
printf("\nRightStack\n");
RightShareStackPush(&stack, 'A');
RightShareStackPush(&stack, 'B');
RightShareStackPush(&stack, 'C');
RightShareStackPush(&stack, 'D');
ret = RightShareStackTop(&stack, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect D, actual %c\n", value);
RightShareStackPop(&stack);
ret = RightShareStackTop(&stack, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect C, actual %c\n", value);
RightShareStackPop(&stack);
ret = RightShareStackTop(&stack, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect B, actual %c\n", value);
RightShareStackPop(&stack);
ret = RightShareStackTop(&stack, &value);
printf("ret expect 1, actual %d\n", ret);
printf("value expect A, actual %c\n", value);
RightShareStackPop(&stack);
ret = RightShareStackTop(&stack, &value); //对空栈进行取栈顶元素
RightShareStackPop(&stack); //对空栈出栈
printf("ret expect 0, actual %d\n", ret);
ShareStackDestroy(&stack);
}
int main()
{
TestShareStack();
return 0;
}
二.地址是常量,不能自增所以定义int a[4];a++是非法的;
三.二维数组与二级指针:
几个重要公式:a[i]+j == &a[i][j];*(a+i)+j == &a[i][j];
对于int (*p)[N] = a; /*其中N是二维数组a[M][N]的列数, 是一个数字, 前面说过, 数组长度不能定义成变量*/
有*(p+i) + j == &a[i][j];
理解:int(*p)[N]定义了一个指针p指向int[N];a=a[0]={...(n个int数据)};
四.原地逆序(数组比链表快)
1.数组(前后交换,只需要循环n/2次)
void reverse(char *str)
{
int i;
char *p = str + strlen(str) - 1, a = 'a';//最好有初始化
for (i = 0; i <= strlen(str)/2; i++)//str[i] != '\0'//修改了for循环的条件
{
a = str[i];
str[i] = *p;
*p = a;
p--;
}2.链表
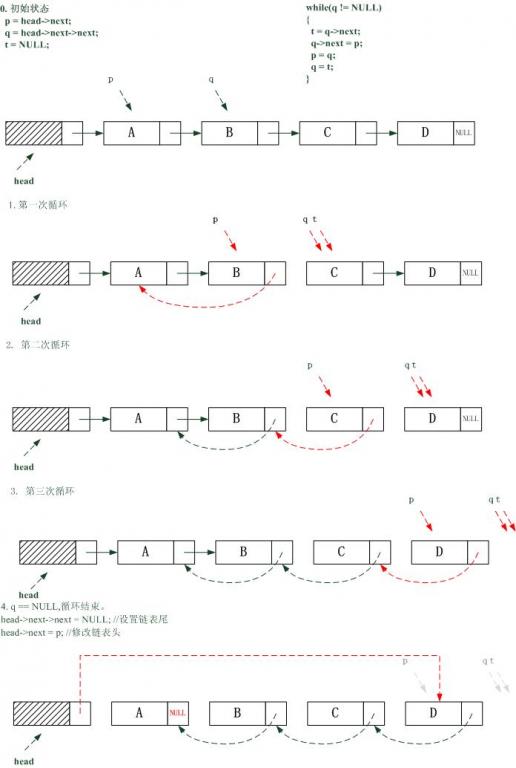
五.数组和链表的查找(数组为何比链表快?)
1、寻址操作次数链表要多一些。数组只需对 [基地址+元素大小*k] 就能找到第k个元素的地址,对其取地址就能获得该元素。链表要获得第k个元素,首先要在其第k-1个元素寻找到其next指针偏移,再将next指针作为地址获得值,这样就要从第一个元素找起,多了多步寻址操作,当数据量大且其它操作较少时,这就有差距了。
该回答源自:http://tieba.baidu.com/p/5069120437
2、CPU缓存会把一片连续的内存空间读入,因为数组结构是连续的内存地址,所以数组全部或者部分元素被连续存在CPU缓存里面,平均读取每个元素的时间只要3个CPU时钟周期。 而链表的节点是分散在堆空间里面的,这时候CPU缓存帮不上忙,只能是去读取内存,平均读取时间需要100个CPU时钟周期。这样算下来,数组访问的速度比链表快33倍! (这里只是介绍概念,具体的数字因CPU而异)。
因此,程序中尽量使用连续的数据结构,这样可以充分发挥CPU缓存的威力。这种对缓存友好的算法称为 Cache-obliviousalgorithm。
该回答源自:https://blog.csdn.net/islandww/article/details/72511737
六.乱七八糟
1.假如数组中大部分元素已经排好序,现在要对它们排序,插入排序最快。
2.

3.二分查找
//二分查找(折半查找),版本1
int BinarySearch1(int a[], int value, int n)
{
int low, high, mid;
low = 0;
high = n-1;
while(low<=high)
{
mid = (low+high)/2;
if(a[mid]==value)
return mid;
if(a[mid]>value)
high = mid-1;
if(a[mid]<value)
low = mid+1;
}
return -1;
}
//二分查找,递归版本
int BinarySearch2(int a[], int value, int low, int high)
{
int mid = low+(high-low)/2;
if(a[mid]==value)
return mid;
if(a[mid]>value)
return BinarySearch2(a, value, low, mid-1);
if(a[mid]<value)
return BinarySearch2(a, value, mid+1, high);
}















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









