



 本文解析了一条SQL查询,针对 Activiti 工作流实例和任务列表的联查,探讨了如何通过explain分析优化查询速度,重点关注索引使用、行数过滤和效率比,提供关键字段解释及优化建议。
本文解析了一条SQL查询,针对 Activiti 工作流实例和任务列表的联查,探讨了如何通过explain分析优化查询速度,重点关注索引使用、行数过滤和效率比,提供关键字段解释及优化建议。
SELECT
inst.PROC_INST_ID_ AS process_instance_id,
def.KEY_ AS process_definition_key,
def.NAME_ AS process_name,
inst.PROC_DEF_ID_ AS process_definition_id,
inst.START_USER_ID_ AS start_user_id,
inst.BUSINESS_KEY_ AS business_key,
inst.DURATION_ AS duration,
inst.START_USER_ID_ AS starter,
v1.TEXT_ AS creator,
ext.entity_code AS entity_code,
cast( inst.START_TIME_ AS datetime ) AS start_time,
cast( inst.END_TIME_ AS datetime ) AS end_time,
(
SELECT
GROUP_CONCAT( iden.USER_ID_ )
FROM
act_hi_identitylink iden
WHERE
task.ID_ = iden.TASK_ID_
AND iden.TYPE_ IN ( 'participant', 'candidate' )
) AS approvers,
TIMESTAMPDIFF( SECOND, STR_TO_DATE( inst.START_TIME_, '%Y-%m-%d %H:%i:%s' ), now( ) ) AS total_time,
TIMESTAMPDIFF( SECOND, STR_TO_DATE( task.CREATE_TIME_, '%Y-%m-%d %H:%i:%s' ), now( ) ) AS wait_time,
task.ID_ AS id,
task.TASK_DEF_KEY_ AS task_def_key,
task.FORM_KEY_ AS form_key,
(
CASE
WHEN state.state = 'A001' THEN
'进行中'
WHEN state.state = 'A002' THEN
'已完成'
WHEN state.state = 'A003' THEN
'终止'
WHEN state.state = 'A004' THEN
'撤回' ELSE '挂起'
END
) AS type,
( SELECT v.text_ FROM act_hi_varinst v WHERE v.NAME_ = 'remark' AND v.PROC_INST_ID_ = inst.PROC_INST_ID_ ) AS remark,
state.state,
task.NAME_ AS NAME,
variable.TEXT_ AS orgCode
FROM
act_hi_procinst inst
LEFT JOIN act_procinst_state state ON state.procinst_id = inst.PROC_INST_ID_
LEFT JOIN (
SELECT
ID_,
NAME_,
PROC_INST_ID_,
CREATE_TIME_,
FORM_KEY_,
TASK_DEF_KEY_
FROM
(
SELECT
ID_,
NAME_,
PROC_INST_ID_,
CREATE_TIME_,
FORM_KEY_,
TASK_DEF_KEY_
FROM
act_ru_task table3
WHERE
NOT EXISTS (
SELECT
table1.ID_
FROM
act_ru_task table1
LEFT JOIN act_ru_variable table2 ON table1.ID_ = table2.TASK_ID_
WHERE
table2.NAME_ = '$taskComplated'
AND table2.TYPE_ = 'string'
AND table2.TEXT_ = 'Y'
AND table3.ID_ = table1.ID_
)
) table4
WHERE
NOT EXISTS (
SELECT
table5.ID_
FROM
act_ru_task table5
LEFT JOIN act_ru_variable table6 ON table5.ID_ = table6.TASK_ID_
WHERE
table6.NAME_ = 'ifCurrentSubNode'
AND table6.TYPE_ = 'string'
AND table6.TEXT_ = 'false'
AND table4.ID_ = table5.ID_
)
) task ON task.PROC_INST_ID_ = inst.PROC_INST_ID_
LEFT JOIN act_re_procdef def ON inst.PROC_DEF_ID_ = def.ID_
LEFT JOIN act_re_procdef_ext ext ON def.KEY_ = ext.proc_key
LEFT JOIN act_ru_variable v1 ON v1.PROC_INST_ID_ = inst.ID_
AND v1.NAME_ = 'creator'
LEFT JOIN ( SELECT TEXT_, PROC_INST_ID_ FROM act_ru_variable WHERE NAME_ = '$orgCode' AND TYPE_ = 'string' ) variable ON variable.PROC_INST_ID_ = inst.ID_
WHERE
1 = 1
AND state.state = 'A001'
AND inst.END_TIME_ IS NULL
ORDER BY
inst.START_TIME_ DESC
LIMIT 20
这是一条联查Activiti工作流的信息到任务列表的sql,优化前查询速度是3-6秒左右
直接交给explain分析,语法如下
explain (
-- 你的sql
)
explain结果如下(因为是优化后做的复盘,所以这图也是优化后的图,无法还原整个优化经历,主要讲我对explain的玩法理解)
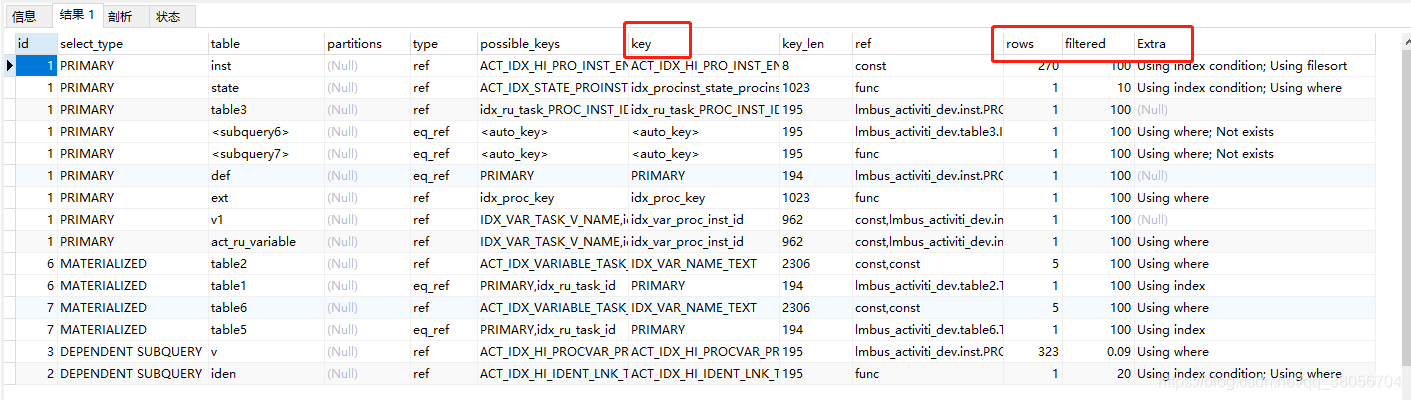
首先要留意四个字段:key、rows、fiter、extra
key能读到的信息:这一查询走了什么索引/有没有走索引
rows:这一查询遍历了多少行,行数越多越要重点关注
filter:这个值越大越好,越小越要重点关注,代表的是结果集里与遍历集的比例,可以理解为这条sql查询花的时间与所得结果的性价比
extra:Using index是好的,Using filesort是不好的,我们尽量每个sql都有using index
通过这四个字段基本知道那些表要建立索引了
主要复合索引的顺序和查询的顺序要一致,不然不会走索引,还有就是select *的查询效率真的很低,记得用select 具体字段代替
就这样吧~

















 2514
2514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









