









HDFS的高可用:
需求:
我们之前搭建的hadoop集群是一个NameNode和三个DateNode
原先那套机制:
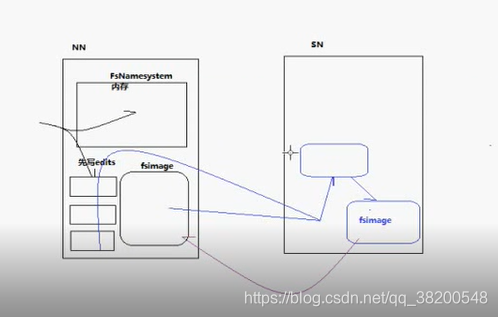
FSNameSystem 元数据对内存的管理器,里面管理的数据都在内存里面,但是在内存里面的数据不太可靠,所以有一个 fsimage 做持久化操作,更新的操作是在edits里面,当一个客户端做数据的操作的时候,导致元数据要发生变化,先把操作记录在日志里面,如果操作成功了,就再记录在内存里面。这些 edits里面的操作记录的数据跟fsimage里面的数据没有合并,fsimage里面的数据要比内存里面的数据落后一大截。这个时候SecondaryNameNode就出场了,它隔一段时间,就把edits文件下载下来,进行合并 – 把他们都加载到内存形成一份新的元数据。然后再把内存中的数据进行持久化到一个文件 – (更新的fsimage),然后会将这份新的fsimage发送到NameNode这一边。把NameNode这边旧的fsimage替换掉。
但是我们发现一个问题
一旦NameNode机器宕机了,那么hdfs系统无法再提供服务了。可用性比较低。
可用性 – 7*24h – 365d
之前我们多web程序使用的是keepalived来实现高可用,但是放在这里是不行的,web服务是需要用来提供访问就可以。但是hadoop机器会实时产生新的文件到hdfs文件系统里面。
keepalived本省对业务程序是没有任何的侵入的,就是去配置机器的ip。keepalived会维护一个虚拟的ip地址,对外提供一个统一的ip。
在hadoop集群里面不是简单地切换ip就可以了。
解决办法:
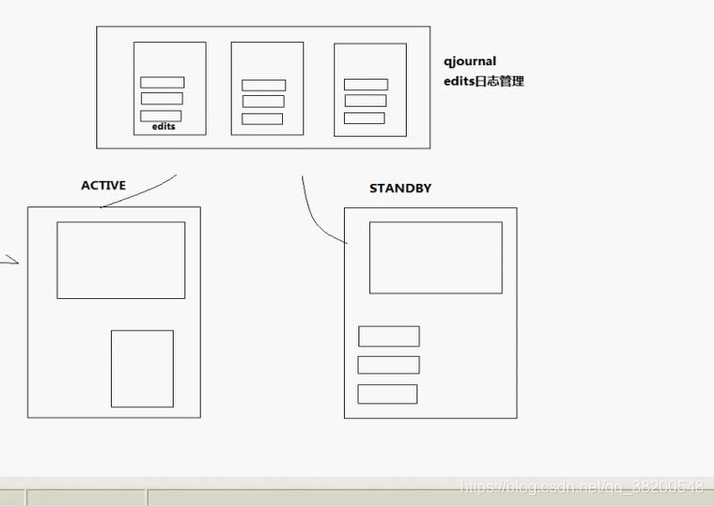
我们要至少有两个NameDode,并且有状态标识,Active:正在提供服务的,StandBy-候补。
由于要对提供服务,那么一定会涉及到数据的同步问题。
数据要进行同步,比较棘手,元数据是比较大的,内存里面可能会有好几个g。
凡是涉及到分布式里面的麻烦事里面,就搞一个第三方出来。
我们把edits文件都拿出来,放在第三方。
Active只要操作了,就往第三方的edits文件中记录,StandBy也从第三方中拿edits文件,在本地进行合并成新的元数据。
这样Active跟StandBy相差的数据就不会太大
第三方得必须非常可靠,第三方挂了之后,我们应该保证还能正常工作,只是Active跟StandBy之间的数据同步就无法进行了。
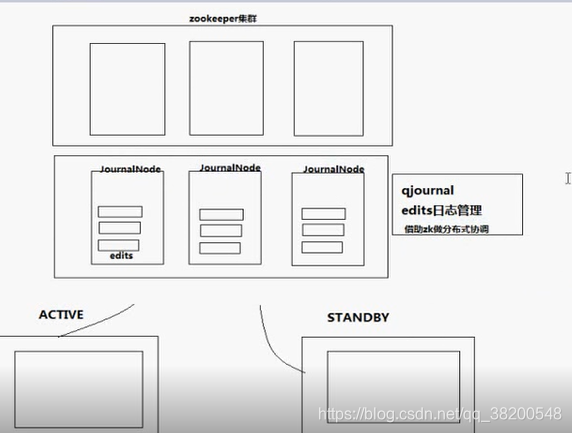
第三方也是一个集群
qjournal : 分布式系统
这个第三方集群要利用zookeeper实现分布式系统
这个HA集群要保持一致性,可靠性,需要有一个第三方来协调,这个第三方就是zookeeper。所以这个系统要部署,就必须要有一个zookeeper集群。
NameNode本地为了保险起见,还是需要再存一份edits文件的。edits文件比较小。
每一台NameNode上面都有一个程序 ZKFX
ZKFC : zookeeper fail control 失败切换的。
ZKFC可以通过rpc接口去调用NameNode – 能够更加精确地知道NameNode的工作状态。
ZKFC通过zookeeper上的节点来实现动态感知。
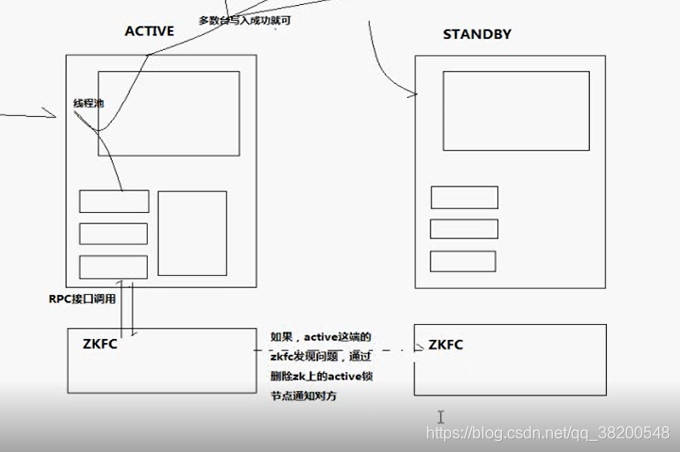
ZKFC在切换状态之前,需要先杀死一个NameNode,防止出现脑裂现象。
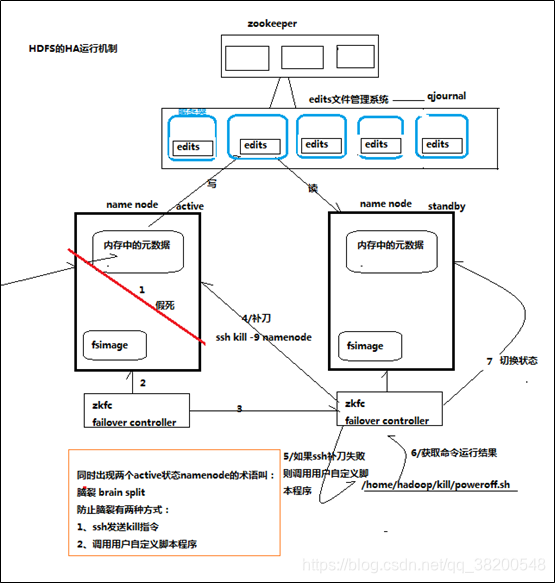
这两个NameNode会有一个逻辑名称,这样对外提供服务,只需要设置这个逻辑名称就可以了。
HA机制是不需要SecondaryNameNode的,因为StandBy这台机器在闲置的时候,是可以充当SecondaryNameNode的作用的。 – checkPoint
YARN的高可用:
yarn的高可用并那不是那么迫切。
但是也可以实现,有两个ResourceManager,也是通过zookeeper去动态感知。
分布式系统肯定是可以让所有的都不放在一起的,但是有的情况下,放在一起会好一点,比如说NodeManager和DatanNode放在一起就比较合理。其他情况,只要有机器就分开,机器不够才放在一起。
机器分布:
ha1 namenode zkfc
ha2 namenode zkfc
ha3 resourcemanager
ha4 resourcemanager
ha5 nodemanager datanode zookeeper journalnode
ha6 nodemanager datanode zookeeper journalnode
ha7 nodemanager datanode zookeeper journalnode
journalnode : 写edits日志的集群
如果是三台机器的话:
ha1 namenode zkfc resoursemanager nodemanager datanode zookeeper journalnode
ha2 namenode zkfc resoursemanager nodemanager datanode zookeeper journalnode
ha3 nodemanager datanode zookeeper journalnode
步骤:
首先先从之前的hadoop集群中挑选一个复制,最好是很纯净版本的,这样机器压力会小一点。
比如我复制的就是之前的bd2这个机器,克隆好之后(我使用的是完整克隆)我也不太清楚完整克隆还是链接克隆更加适合。
复制好之后我就先修改了hostname:
/etc/sysconfig/network
把hostname改成ha1,
然后修改host文件
/etc/hosts
里面设置成:
192.168.17.161 ha1
192.168.17.162 ha2
192.168.17.163 ha3
192.168.17.164 ha4
192.168.17.165 ha5
192.168.17.166 ha6
192.168.17.167 ha7
由于我是克隆的,所以还需要修改网卡
参考文章:
https://blog.csdn.net/zuixiaoyao_001/article/details/80641665
我直接把原先的eth0删除,然后把eth1改成eth0。
接着就是配置ip了
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes #是否开机启用
BOOTPROTO=static #ip地址设置为静态
IPADDR=192.168.17.161
NETMASK=255.255.255.0
如果这里面有mac地址,就应该修改成eth0的mac地址
然后就reboot重启。这样ip就设置好了。
这样一台ha1里面已经有jdk,安装了hadoop,还有hadoop这个用户都配置好了。
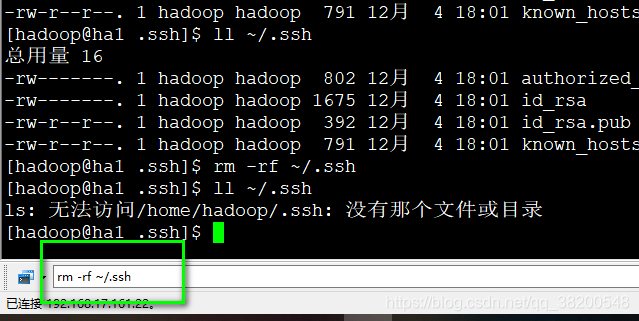
注意你需要检查一下有没有免密登录。
没有的话需要设置
然后就把这台ha1复制6份。
要配置免密登录,之前克隆过来的时候配置了,但是克隆过来之后是失效了,所以全部都删除
rm -rf ~/.ssh
重新生成免密登录的秘钥,全部发送
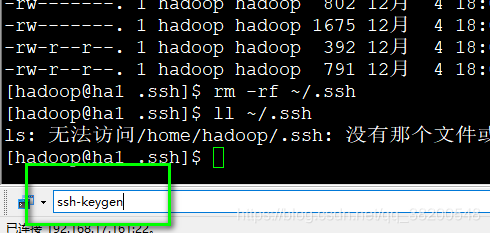
然后使用
ssh-copy-id ha1
ssh-copy-id ha2
ssh-copy-id ha3
ssh-copy-id ha4
ssh-copy-id ha5
ssh-copy-id ha6
ssh-copy-id ha7
我只在ha1和ha2上进行了免密登录的设置
在ha5上上传zookeeper.
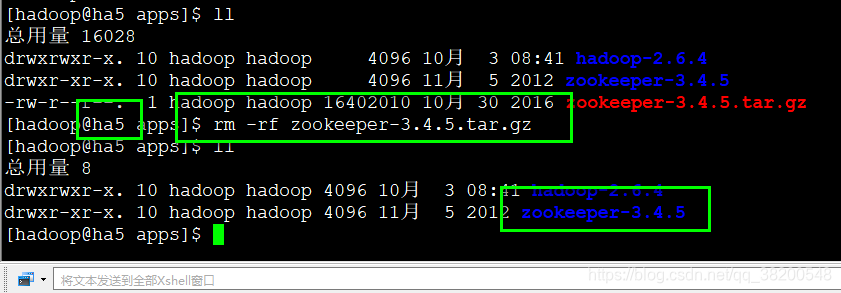
为了复制快速点,我们把zookeeper里面的我们不需要用的文件删除。
rm -rf *.xml *.txt docs src *.asc *.md5 *.sha1
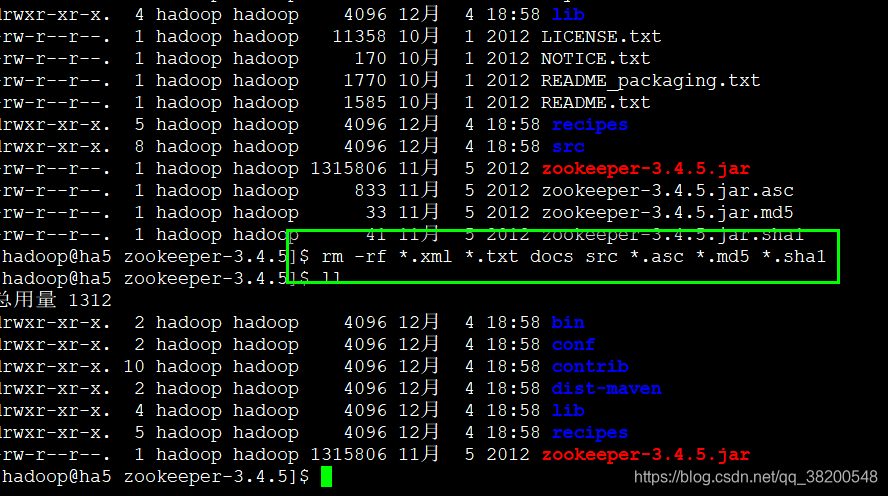
dist-maven 这个文件夹也可以删除。
修改配置文件
将zoo-template.cfg改成zoo.cfg
vi zoo.cfg
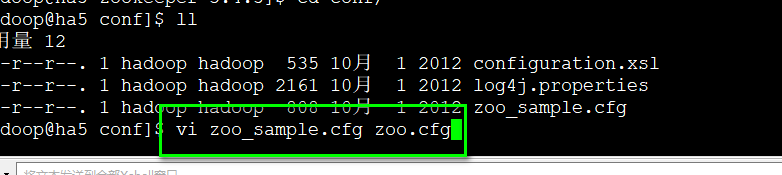
修改 :
dataDir=/home/hadoop/zkdata
在配置文件最后增加:
server.1=ha5:2888:3888
server.2=ha6:2888:3888
server.3=ha7:2888:3888
创建目录
mkdir /home/hadoop/zkdata
进入 zkdata这个目录
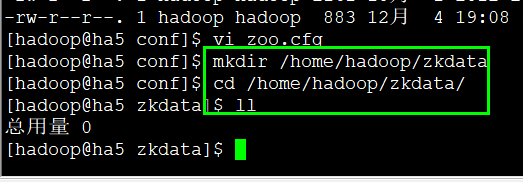
然后往这个目录写上myid
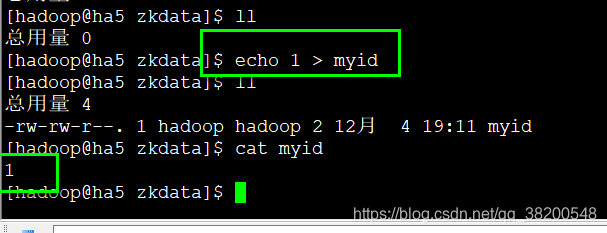
将配置好了的zookeeper复制到ha6,ha7上
scp -r apps/zookeeper-3.4.5/ ha5://home/hadoop/apps/
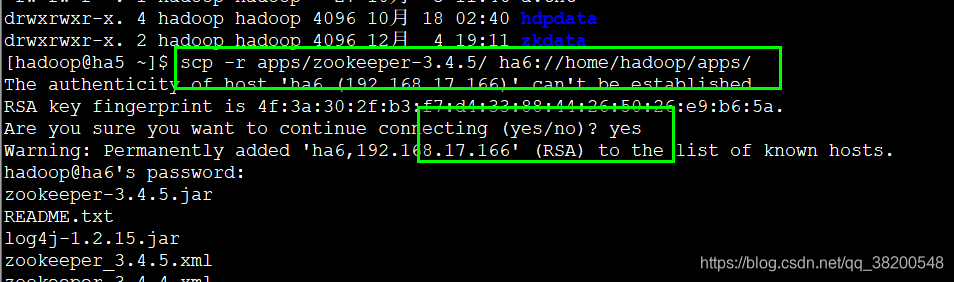
将zkdata复制到ha6,ha7
scp -r zkdata/ ha6:$PWD

然后分别在ha6跟ha7上修改myid。
echo 2 > myid -- ha6
echo 3 > myid -- ha7
现在我们先启动一下zookeeper,看一下能否正常启动
bin/zkServer.sh start
三台机器都需要启动zookeeper
使用jps查看一下进程:
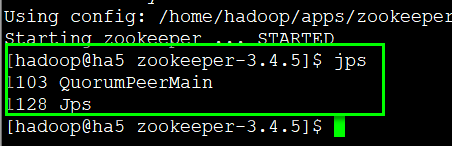
出现了 QuorumPeerMain
ha5,ha6,ha7每台机器都去查看,如果都出现这个进程,那么zookeeper机器能够正常启动。
到现在zookeeper集群就搞定了
现在就要安装Hadoop集群了
把原先的hadoop文件都删除 每台机器上的hadoop都删除。
我们现在ha1上配置hadoop,然后再复制到其他的机器上去。
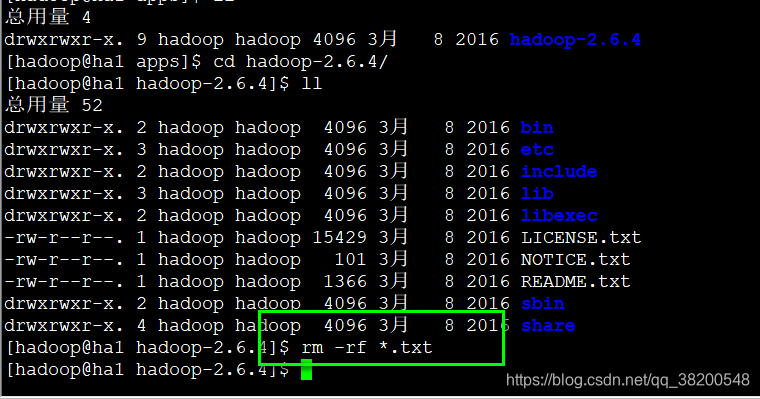
删除一些不需要用的文件,复制的时候,更快。
还可以删除 share里面的doc 文件
接下来就是修改hadoop的配置文件了
hadoop-env.sh
- 配置JAVA_HOME : 因为是使用ssh启动,是在子进程中启动 $JAVE_HOME直接获取不到,所以需要手动指定。
core-site.xml
- 1.指定hdfs的nameservice,就是NameNode的逻辑名称
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns/</value>
</property>
- 2.指定hadoop的临时目录
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/apps/hdpdata/</value>
</property>
- 3.指定zookeeper的地址
<property>
<name>ha.zookeeper.quorum</name>
<value>ha5:2181,ha6:2181,ha7:2181</value>
</property>
</configuration>
hdfs-site.xml
- 1.指定hdfs的nameservice为ns,需要和core-site.xml中保持yic一致
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
- 2.ns下有两个NameNode,分别是nn1,nn2
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
- 3.两个NameNode的http和RPC通信地址
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>ha1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>ha1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>ha2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>ha2:50070</value>
</property>
- 4.指定NameNode的edits元数据在JournalNode上的存放位置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ha5:8485;ha6:8485;ha7:8485/ns</value>
</property>
- 5.指定JournalNode在本地磁盘存放数据的位置
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journaldata</value>
</property>
- 6.开启NameNode失败自动切换
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
- 7.配置失败自动切换实现方式
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
- 8.配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property
- 9.使用sshfence隔离机制时需要ssh免登陆
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
- 10.配置sshfence隔离机制超时时间
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
将mapred-site.xml.template改名为mapred-site.xml,并且修改
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml – yarn的高可用
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ha3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>ha4</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>ha5:2181,ha6:2181,ha7:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置slaves文件 – 就是制定DataNode
slaves是指子节点的位置,因为要在ha1上启动HDFS,在ha3上启动yarn,所以ha1上的slaves文件指定的是datanode的位置,ha3上的slaves文件指定的是NodeManager的位置
vi slaves
到此为止,hadoop的配置就完成了,接下来的就是将配置好了的hadoop分发到其他的机器上。
注意:严格按照下面的步骤!!!
1. 启动zookeeper集群(分别在ha5、ha6、ha7上启动zk)
cd /hadoop/zookeeper-3.4.5/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status
2.启动journalnode(分别在在ha5、ha6、ha7上执行)
cd /hadoop/hadoop-2.6.4
sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,hadoop05、hadoop06、hadoop07上多了JournalNode进程

3.接下来就是格式化NameNode,只要格式化一个,因为两个NameNode的元数据要完全严格一致。cluster-id,pool都得一样,所以只能格式化一台,然后复制给另一台。
格式化只能在ha1或者ha2其中的一台上进行
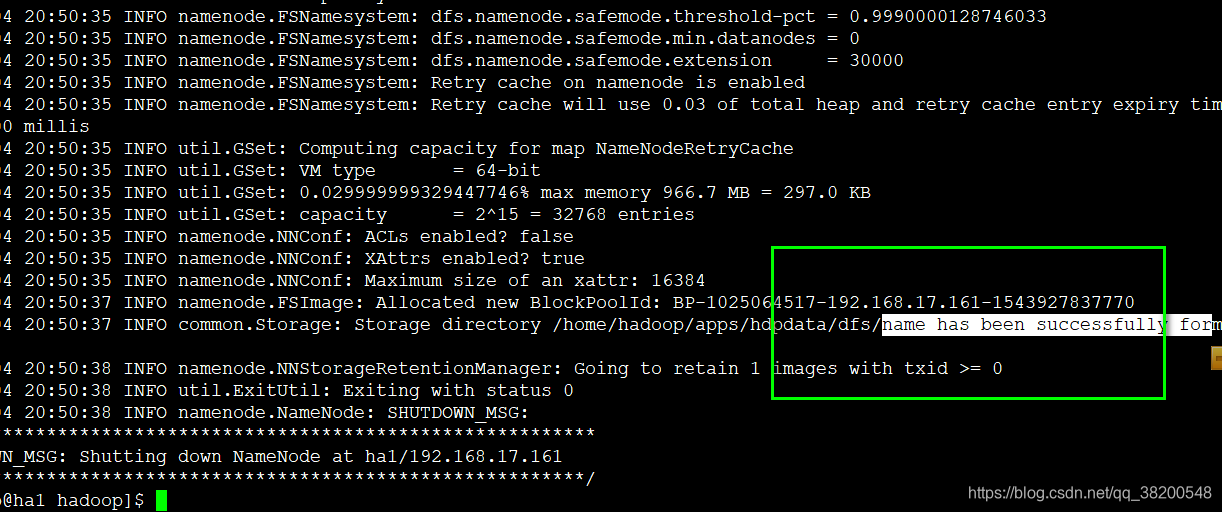
格式化成功之后,查看:
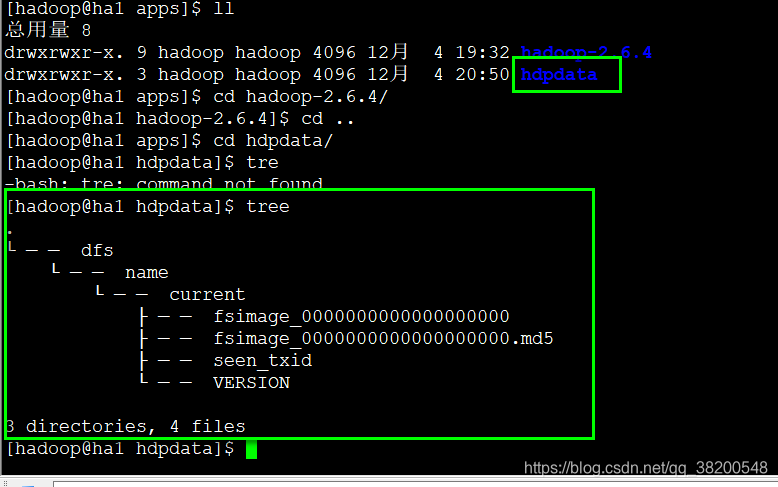
可以进入目录里面查看一下这个VERSION文件:
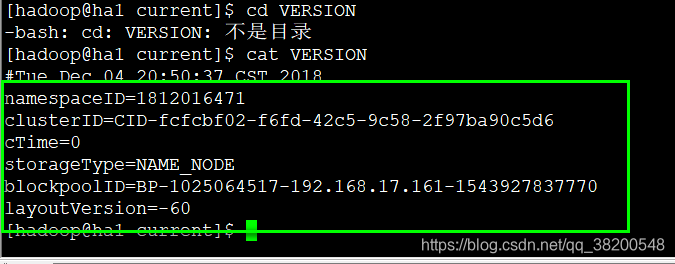
将ha1格式化之后生成的hdpdata复制到ha2相应的文件夹里。
scp -r hdpdata/ ha2:~/apps/

这样两个NameNode的初识数据都是一样的。
然后还需要格式化ZKFC
在ha1上,格式化一次就可以,因为是往zookeeper上写。
hdfs zkfc -formatZK
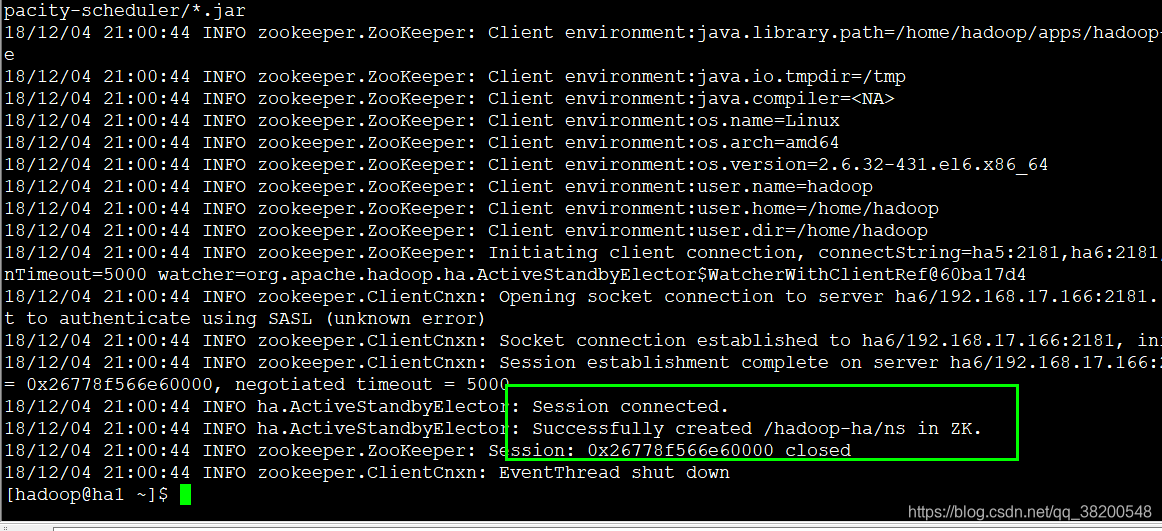
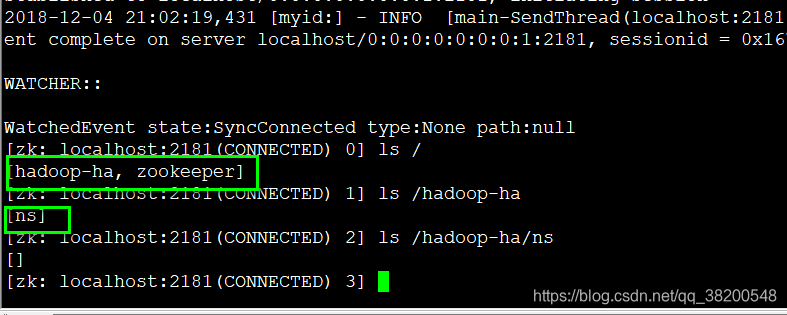
bin/zkCli.sh
查看zookeeper上的节点
在mini1上启动,mini1到所有机器的免密登录都要配置
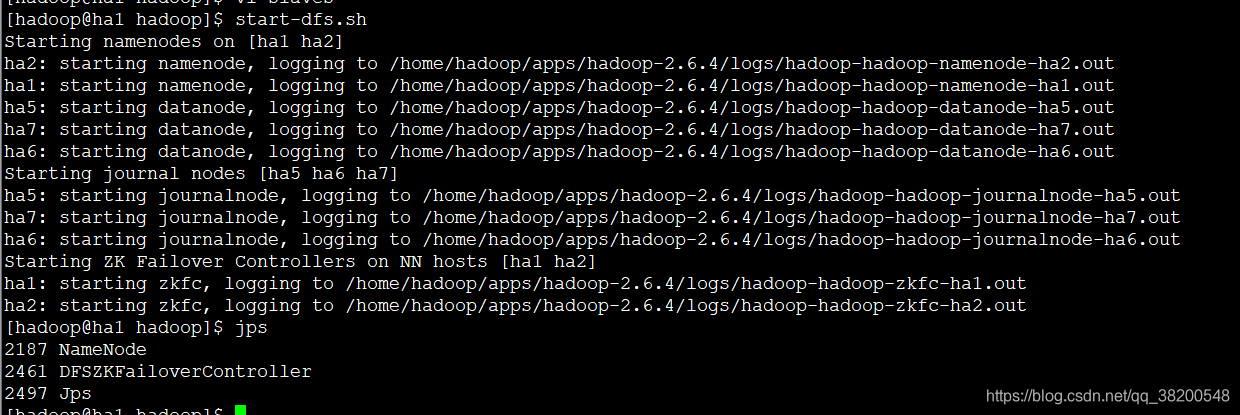
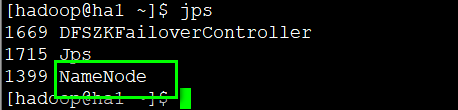
start-dfs会启动ha1跟ha2上面的NameNode,以及ha5,ha6,ha7上面的DataNode,还有ha5,ha6,ha7上面的journalnode – 写edits文件的。还会启动ha1跟ha2上的两个太监 – zkfc
启动yarn,yarn是在ha3获取ha4上的,所以ha3跟ha4到其他机器的免密登录都要配置好

在ha3上启动yarn,就会启动自己(ha3)上的resourcemanager,然后还会启动ha5,ha6,ha7上的NodeManager
在ha4上还需要手动启动一个ResourceManager:

ResourceManager 的启动脚本不是使用ssh,而是直接在本地启动的。所以必须放在ha3,ha4上启动
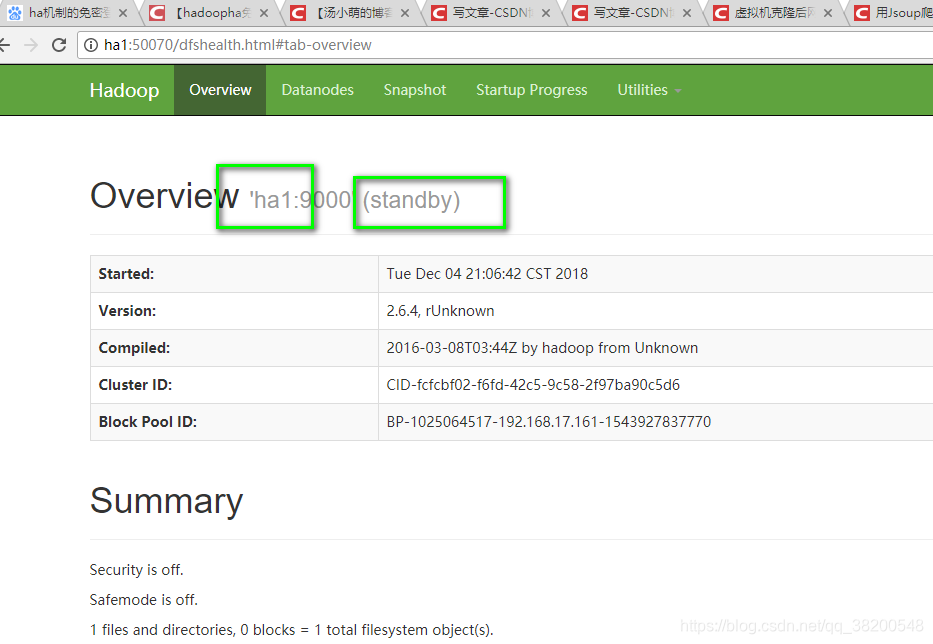
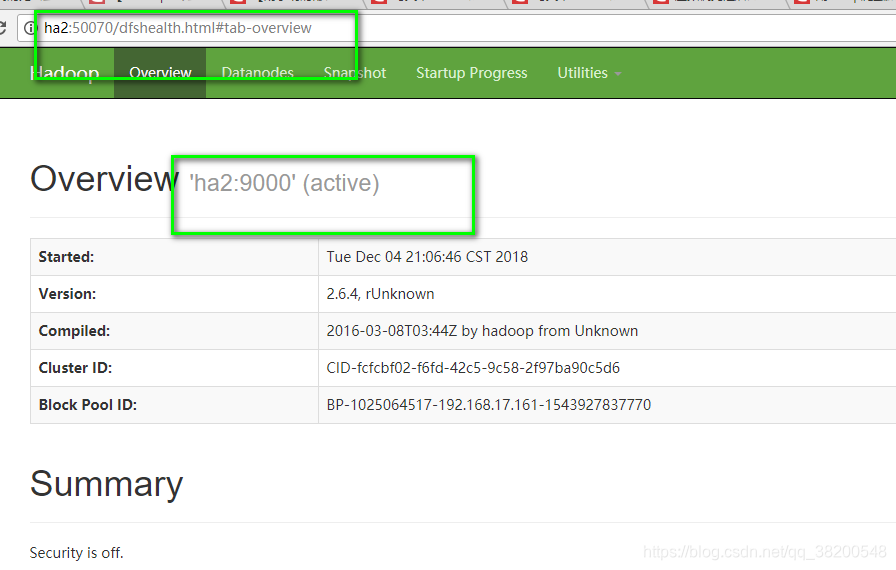
如果你访问yarn集群:
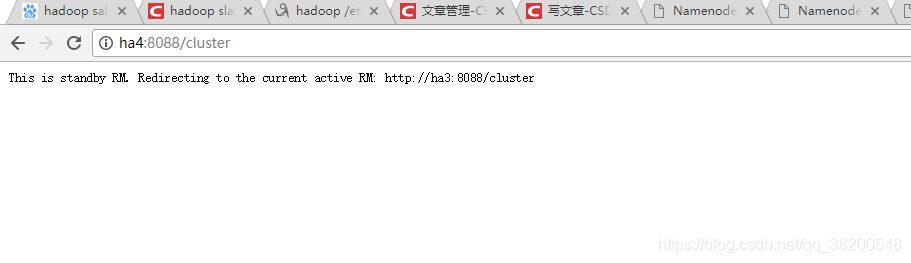
只有ha3会提供这个访问页面。访问ha4的页面会直接跳转到ha3的yarn集群的页面。
在ha1上关闭hdfs – 就是关闭ha1跟ha2上的NameNode,还会关闭ha5,ha6,ha7上的DataNode
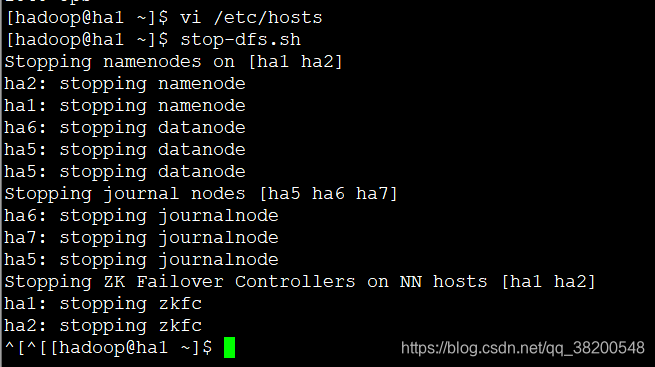
在ha3上关闭yarn
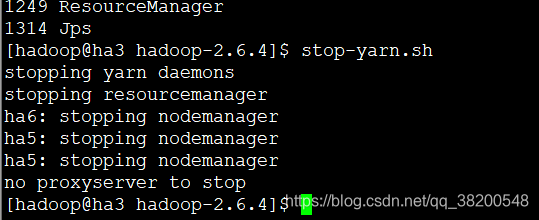
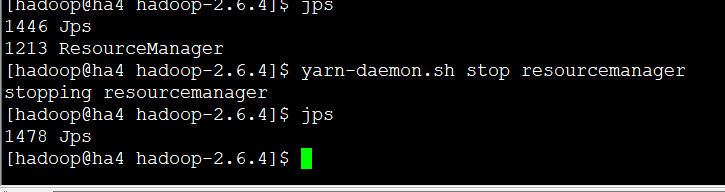
ha4上之前是手动启动resourceManager的,所以现在也需要手动关闭
最后再关闭zookeeper 集群
测试HA机制
先像hdfs文件上上传一个文件
hadoop fs -put /etc/profile /
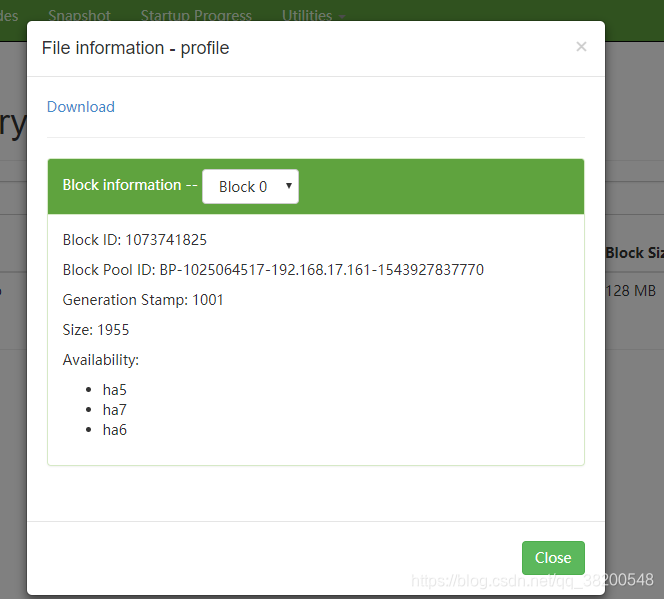
上传的这个文件会在ha5,ha6,ha7上都有副本。
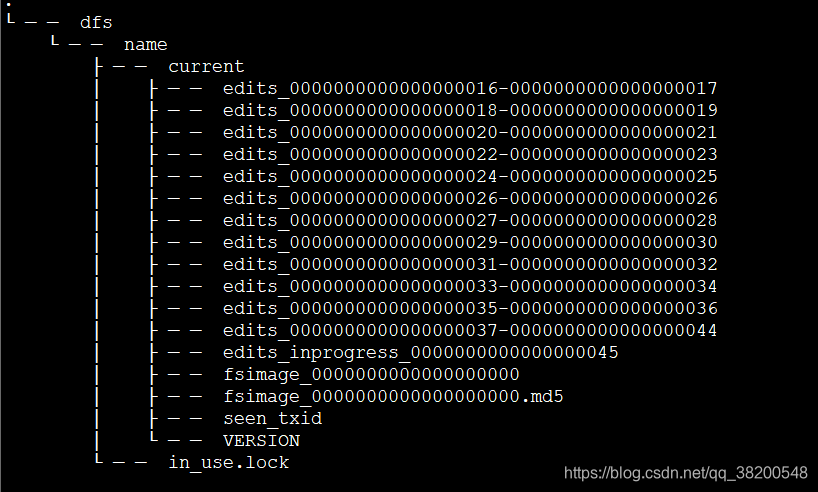
ha5,ha6,ha7上的hdpdata目录的结构:
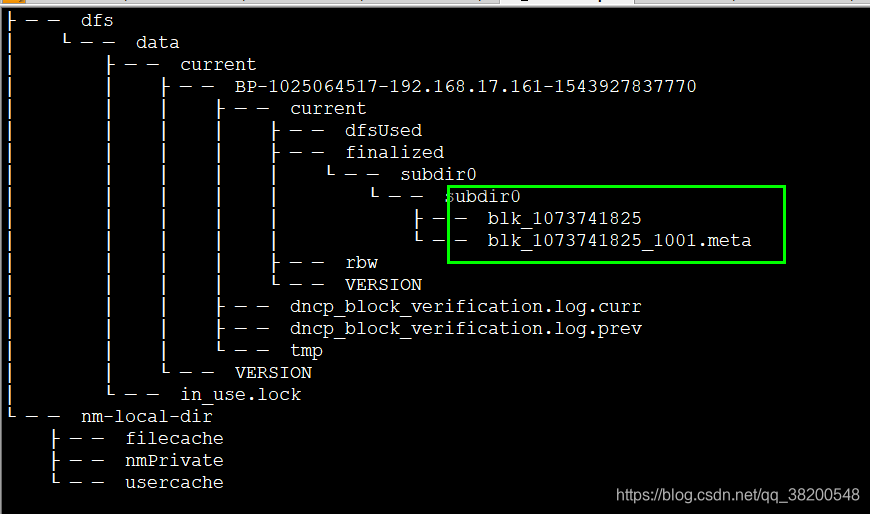
在ha1 – active上的hdpdata:
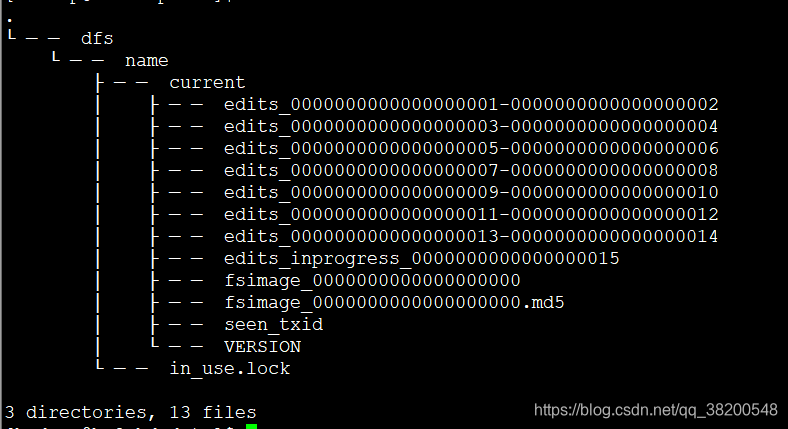
在ha2 – standby 上的hdpdata:
然后我把ha1的NameNode服务杀死。
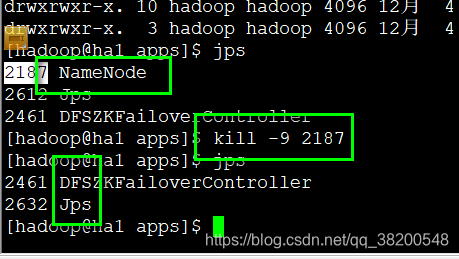
active状态立即切换过来了。
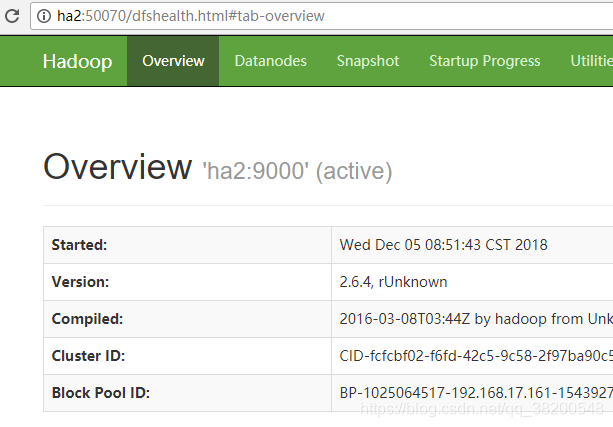
然后我又往hdfs上上传了文件:

接着我又关闭了ha2上的NameNode,启动了ha1上的NameNode,发现无论哪个NameNode宕机了,都能正常操作hdfs。
ha2上的hdpdata:
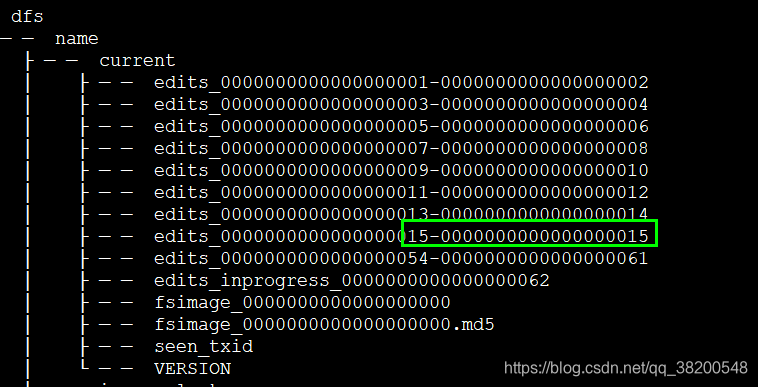
ha1上的hdpdata:
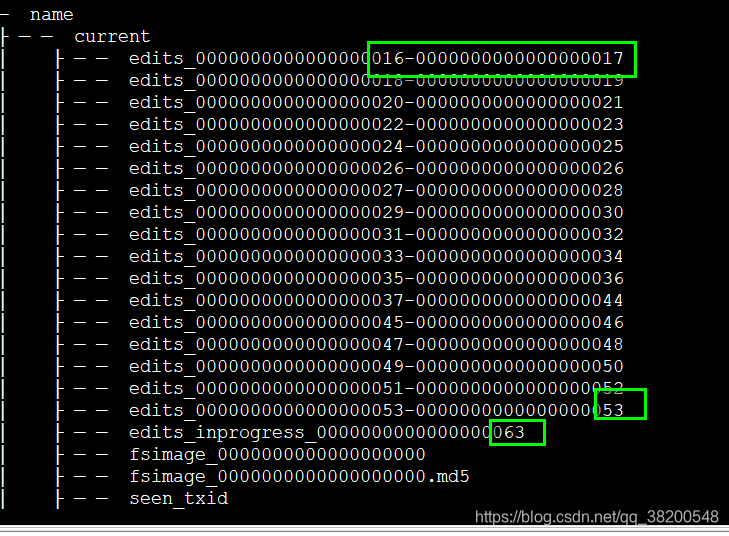
这些edits文件都是交替这递增的。
如果正在对hdfs文件正在操作的过程中 active 的 NamenNode突然宕机了。那么这次hdfs操作可能会失败
hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA、YARN等。最新的hadoop-2.6.4又增加了YARN HA
注意:apache提供的hadoop-2.6.4的安装包是在32位操作系统编译的,因为hadoop依赖一些C++的本地库,
所以如果在64位的操作上安装hadoop-2.6.4就需要重新在64操作系统上重新编译
(建议第一次安装用32位的系统,我将编译好的64位的也上传到群共享里了,如果有兴趣的可以自己编译一下)
前期准备就不详细说了,课堂上都介绍了
1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系 /etc/hosts
######注意######如果你们公司是租用的服务器或是使用的云主机(如华为用主机、阿里云主机等)
/etc/hosts里面要配置的是内网IP地址和主机名的映射关系
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
集群规划:
主机名 IP 安装的软件 运行的进程
mini1 192.168.1.200 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
mini2 192.168.1.201 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
mini3 192.168.1.202 jdk、hadoop ResourceManager
mini4 192.168.1.203 jdk、hadoop ResourceManager
mini5 192.168.1.205 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
mini6 192.168.1.206 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
mini7 192.168.1.207 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
说明:
1.在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态
2.hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.6.4解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
安装步骤:
1.安装配置zooekeeper集群(在hadoop05上)
1.1解压
tar -zxvf zookeeper-3.4.5.tar.gz -C /home/hadoop/app/
1.2修改配置
cd /home/hadoop/app/zookeeper-3.4.5/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:dataDir=/home/hadoop/app/zookeeper-3.4.5/tmp
在最后添加:
server.1=hadoop05:2888:3888
server.2=hadoop06:2888:3888
server.3=hadoop07:2888:3888
保存退出
然后创建一个tmp文件夹
mkdir /home/hadoop/app/zookeeper-3.4.5/tmp
echo 1 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid
1.3将配置好的zookeeper拷贝到其他节点(首先分别在hadoop06、hadoop07根目录下创建一个hadoop目录:mkdir /hadoop)
scp -r /home/hadoop/app/zookeeper-3.4.5/ hadoop06:/home/hadoop/app/
scp -r /home/hadoop/app/zookeeper-3.4.5/ hadoop07:/home/hadoop/app/
注意:修改hadoop06、hadoop07对应/hadoop/zookeeper-3.4.5/tmp/myid内容
hadoop06:
echo 2 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid
hadoop07:
echo 3 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid
2.安装配置hadoop集群(在hadoop00上操作)
2.1解压
tar -zxvf hadoop-2.6.4.tar.gz -C /home/hadoop/app/
2.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_55
export HADOOP_HOME=/hadoop/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /home/hadoop/app/hadoop-2.6.4/etc/hadoop
2.2.1修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_55
###############################################################################
2.2.2修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bi/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hdpdata/</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>mini5:2181,mini6:2181,mini7:2181</value>
</property>
</configuration>
###############################################################################
2.2.3修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为bi,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>bi</value>
</property>
<!-- bi下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.bi</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.bi.nn1</name>
<value>mini1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.bi.nn1</name>
<value>mini1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.bi.nn2</name>
<value>mini2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.bi.nn2</name>
<value>mini2:50070</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://mini5:8485;mini6:8485;mini7:8485/bi</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.bi</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
###############################################################################
2.2.4修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
###############################################################################
2.2.5修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>mini3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>mini4</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>mini5:2181,mini6:2181,mini7:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2.2.6修改slaves(slaves是指定子节点的位置,因为要在hadoop01上启动HDFS、在hadoop03启动yarn,所以hadoop01上的slaves文件指定的是datanode的位置,hadoop03上的slaves文件指定的是nodemanager的位置)
mini5
mini6
mini7
2.2.7配置免密码登陆
#首先要配置hadoop00到hadoop01、hadoop02、hadoop03、hadoop04、hadoop05、hadoop06、hadoop07的免密码登陆
#在hadoop01上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点,包括自己
ssh-coyp-id hadoop00
ssh-coyp-id hadoop01
ssh-coyp-id hadoop02
ssh-coyp-id hadoop03
ssh-coyp-id hadoop04
ssh-coyp-id hadoop05
ssh-coyp-id hadoop06
ssh-coyp-id hadoop07
#配置hadoop02到hadoop04、hadoop05、hadoop06、hadoop07的免密码登陆
#在hadoop02上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点
ssh-coyp-id hadoop03
ssh-coyp-id hadoop04
ssh-coyp-id hadoop05
ssh-coyp-id hadoop06
ssh-coyp-id hadoop07
#注意:两个namenode之间要配置ssh免密码登陆,别忘了配置hadoop01到hadoop00的免登陆
在hadoop01上生产一对钥匙
ssh-keygen -t rsa
ssh-coyp-id -i hadoop00
2.4将配置好的hadoop拷贝到其他节点
scp -r /hadoop/ hadoop02:/
scp -r /hadoop/ hadoop03:/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hadoop04:/hadoop/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hadoop05:/hadoop/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hadoop06:/hadoop/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hadoop07:/hadoop/
###注意:严格按照下面的步骤!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
2.5启动zookeeper集群(分别在mini5、mini6、mini7上启动zk)
cd /hadoop/zookeeper-3.4.5/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status
2.6启动journalnode(分别在在mini5、mini6、mini7上执行)
cd /hadoop/hadoop-2.6.4
sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,hadoop05、hadoop06、hadoop07上多了JournalNode进程
2.7格式化HDFS
#在mini1上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/hadoop/hadoop-2.6.4/tmp,然后将/hadoop/hadoop-2.6.4/tmp拷贝到hadoop02的/hadoop/hadoop-2.6.4/下。
scp -r tmp/ hadoop02:/home/hadoop/app/hadoop-2.6.4/
##也可以这样,建议hdfs namenode -bootstrapStandby
2.8格式化ZKFC(在mini1上执行一次即可)
hdfs zkfc -formatZK
2.9启动HDFS(在mini1上执行)
sbin/start-dfs.sh
2.10启动YARN(#####注意#####:是在hadoop02上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
sbin/start-yarn.sh
到此,hadoop-2.6.4配置完毕,可以统计浏览器访问:
http://hadoop00:50070
NameNode 'hadoop01:9000' (active)
http://hadoop01:50070
NameNode 'hadoop02:9000' (standby)
验证HDFS HA
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill -9 <pid of NN>
通过浏览器访问:http://192.168.1.202:50070
NameNode 'hadoop02:9000' (active)
这个时候hadoop02上的NameNode变成了active
在执行命令:
hadoop fs -ls /
-rw-r--r-- 3 root supergroup 1926 2014-02-06 15:36 /profile
刚才上传的文件依然存在!!!
手动启动那个挂掉的NameNode
sbin/hadoop-daemon.sh start namenode
通过浏览器访问:http://192.168.1.201:50070
NameNode 'hadoop01:9000' (standby)
验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar wordcount /profile /out
OK,大功告成!!!
测试集群工作状态的一些指令 :
bin/hdfs dfsadmin -report 查看hdfs的各节点状态信息
bin/hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态
sbin/hadoop-daemon.sh start namenode 单独启动一个namenode进程
./hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
参考:
https://blog.csdn.net/qq_33161208/article/details/80925232
这位作者的博客,写真步骤很清晰。














 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









