







提取知乎发现页面的内容
打开知乎的发现页面

审查元素
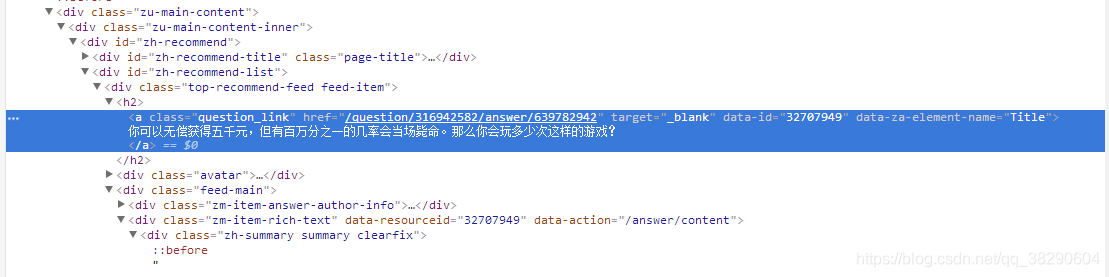
观察发现,标题隐藏在h2标签的a标签下 ,一次采用不同的方法对标题内容进行提取
1.按照标签名进行提取,前提是这个标签中只有一个属性
for a in soup.find_all('h2'):
print(a.string)2.按照属性进行提取
for a in soup.find_all(attrs={'class':'question_link'}):
print(a.string)3.按照属性查找的另一种简便写法
for a in soup.find_all(class_='quest 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









