



 本文详细介绍了如何在Spark环境下利用Hudi进行数据的增删改查,包括环境配置、数据写入与读取Hudi表的操作步骤,以及通过Spark DataFrame处理Hudi数据的示例。Hudi的特点在于其分区管理和高效数据存储,适合大规模数据处理。
本文详细介绍了如何在Spark环境下利用Hudi进行数据的增删改查,包括环境配置、数据写入与读取Hudi表的操作步骤,以及通过Spark DataFrame处理Hudi数据的示例。Hudi的特点在于其分区管理和高效数据存储,适合大规模数据处理。
这个更全:Spark 增删改查 Hudi代码
一、使用Hudi环境准备
1.安装HDFS分布式文件系统:存储Hudi数据
Hadoop 2.8.0
首次格式化:hdfs namenode -format
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh start datanode
测试:hdfs dfs -put README.md /datas/
2.安装Spark分布式计算引擎:操作Hudi表的数据,主要CRUD
Spark 3.0.3
配置conf/spark-env.sh
启动bin/spark-shell --master local[2]
测试:
上传一文件:hdfs dfs -put README.md /datas/
scala> val datasRDD = sc.textFile("/datas/README.md")
datasRDD: org.apache.spark.rdd.RDD[String] = /datas/README.md MapPartitionsRDD[1] at textFile at <console>:24
scala> datasRDD.count
res0: Long = 103
scala> val dataFrame = spark.read.textFile("/datas/README.md")
dataFrame: org.apache.spark.sql.Dataset[String] = [value: string]
scala> dataFrame.printSchema
root
|-- value: string (nullable = true)
scala> dataFrame.show(10,false)
+------------------------------------------------------------------------------+
|value |
+------------------------------------------------------------------------------+
|# Apache Spark |
| |
|Spark is a fast and general cluster computing system for Big Data. It provides|
|high-level APIs in Scala, Java, Python, and R, and an optimized engine that |
|supports general computation graphs for data analysis. It also supports a |
|rich set of higher-level tools including Spark SQL for SQL and DataFrames, |
|MLlib for machine learning, GraphX for graph processing, |
|and Spark Streaming for stream processing. |
| |
|<http://spark.apache.org/> |
+------------------------------------------------------------------------------+
only showing top 10 rows
3.Scala 2.11.11
二、数据通过spark写入hudi
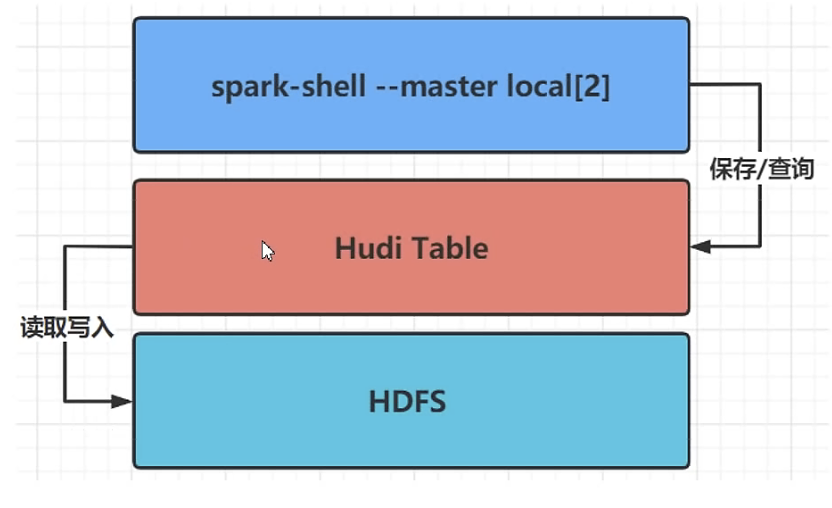
在spark-shell命令行,对Hudi表数据进行操作,需要运行spark-shell命令时,添加相关依赖包
下载到 /Users/FengZhen/.ivy2/cache,在线下载,慢
./spark-shell --master local[2] --packages org.apache.hudi:hudi-spark3-bundle_2.12:0.10.0,org.apache.spark:spark-avro_2.12:3.0.3 --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
直接使用本地jar
./spark-shell --master local[2] --jars /Users/FengZhen/Desktop/Hadoop/spark/spark-3.0.3-bin-hadoop2.7/jars/spark-avro_2.12-3.0.3.jar,/Users/FengZhen/Desktop/Hadoop/hudi/hudi-0.10.1/packaging/hudi-spark-bundle/target/hudi-spark3.1.2-bundle_2.12-0.10.1.jar --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
保存数据至Hudi表及从Hudi表加载数据
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://localhost:9000/datas/hudi-warehouse/hudi_trips_cow"
val dataGen = new DataGenerator
//准备数据
val inserts = convertToStringList(dataGen.generateInserts(10))
inserts: java.util.List[String] = [{"ts": 1643936410360, "uuid": "54782a44-5262-4cb5-9018-4b176bfcebfe", "rider": "rider-213", "driver": "driver-213", "begin_lat": 0.4726905879569653, "begin_lon": 0.46157858450465483, "end_lat": 0.754803407008858, "end_lon": 0.9671159942018241, "fare": 34.158284716382845, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1643751609190, "uuid": "80d2c5af-cc88-4775-881c-ce00bc150710", "rider": "rider-213", "driver": "driver-213", "begin_lat": 0.6100070562136587, "begin_lon": 0.8779402295427752, "end_lat": 0.3407870505929602, "end_lon": 0.5030798142293655, "fare": 43.4923811219014, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1643811519875, "uuid": "7cc20d76-37ef-4a8f-94bb-2318b38d261d", "rider": "rider-213", "driver"...
//指定两个分区,读取为dataframe格式
val df = spark.read.json(spark.sparkContext.parallelize(inserts,2))
scala> df.printSchema
root
|-- begin_lat: double (nullable = true)
|-- begin_lon: double (nullable = true)
|-- driver: string (nullable = true)
|-- end_lat: double (nullable = true)
|-- end_lon: double (nullable = true)
|-- fare: double (nullable = true)
|-- partitionpath: string (nullable = true)
|-- rider: string (nullable = true)
|-- ts: long (nullable = true)
|-- uuid: string (nullable = true)
查看数据
scala> df.select("rider", "begin_lat", "begin_lon", "driver", "fare", "uuid", "ts").show(10,truncate=false)
+---------+-------------------+-------------------+----------+------------------+------------------------------------+-------------+
|rider |begin_lat |begin_lon |driver |fare |uuid |ts |
+---------+-------------------+-------------------+----------+------------------+------------------------------------+-------------+
|rider-213|0.4726905879569653 |0.46157858450465483|driver-213|34.158284716382845|54782a44-5262-4cb5-9018-4b176bfcebfe|1643936410360|
|rider-213|0.6100070562136587 |0.8779402295427752 |driver-213|43.4923811219014 |80d2c5af-cc88-4775-881c-ce00bc150710|1643751609190|
|rider-213|0.5731835407930634 |0.4923479652912024 |driver-213|64.27696295884016 |7cc20d76-37ef-4a8f-94bb-2318b38d261d|1643811519875|
|rider-213|0.21624150367601136|0.14285051259466197|driver-213|93.56018115236618 |95c601e1-0d8a-4b4f-a441-9f7798bec7a2|1644303895565|
|rider-213|0.40613510977307 |0.5644092139040959 |driver-213|17.851135255091155|8f2b5da1-4f26-447f-9bc5-bd4c9f795024|1643952973289|
|rider-213|0.8742041526408587 |0.7528268153249502 |driver-213|19.179139106643607|427d34d4-0840-4e9f-b442-68bdbb1e62d3|1643744615179|
|rider-213|0.1856488085068272 |0.9694586417848392 |driver-213|33.92216483948643 |bec76118-3f03-4e11-b7da-c1b9cda47832|1644200519234|
|rider-213|0.0750588760043035 |0.03844104444445928|driver-213|66.62084366450246 |815de54a-f3bf-495c-aa22-2ec301f74610|1643946541239|
|rider-213|0.651058505660742 |0.8192868687714224 |driver-213|41.06290929046368 |b05819f0-36c5-4d67-9771-af9c5a528104|1644149438138|
|rider-213|0.11488393157088261|0.6273212202489661 |driver-213|27.79478688582596 |0995237e-9a58-4a9f-a58d-414f718087b1|1644250954765|
+---------+-------------------+-------------------+----------+------------------+------------------------------------+-------------+
插入数据
df.write.mode(Overwrite).format("hudi").options(getQuickstartWriteConfigs).option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).save(basePath)
写入解析
df.write
.mode(Overwrite) -- 覆盖
.format("hudi”) --hudi格式
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD_OPT_KEY, "ts”)
.option(RECORDKEY_FIELD_OPT_KEY, "uuid”)
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath”)
.option(TABLE_NAME, tableName)
.save(basePath) --保存路径
getQuickstartWriteConfigs:设置写入/更新数据至hudi时,shuffle时分区数目
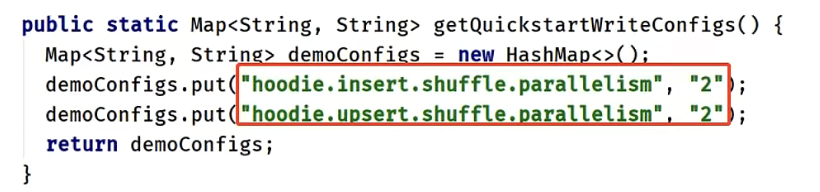
PRECOMBINE_FIELD_OPT_KEY:数据合并时,依据主键字段

RECORDKEY_FIELD_OPT_KEY:每条记录的唯一ID,支持多字段

PARTITIONPATH_FIELD_OPT_KEY:用于存放数据的分区字段

scala> df.write.mode(Overwrite).format("hudi").options(getQuickstartWriteConfigs).option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).save(basePath)
warning: there was one deprecation warning; for details, enable `:setting -deprecation' or `:replay -deprecation'
22/02/08 17:13:13 WARN config.DFSPropertiesConfiguration: Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
22/02/08 17:13:13 WARN config.DFSPropertiesConfiguration: Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
13:00 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://localhost:9000/datas/hudi-warehouse/hudi_trips_cow. Falling back to direct markers.
13:02 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://localhost:9000/datas/hudi-warehouse/hudi_trips_cow. Falling back to direct markers.
13:02 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://localhost:9000/datas/hudi-warehouse/hudi_trips_cow. Falling back to direct markers.
13:03 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://localhost:9000/datas/hudi-warehouse/hudi_trips_cow. Falling back to direct markers.
13:03 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://localhost:9000/datas/hudi-warehouse/hudi_trips_cow. Falling back to direct markers.
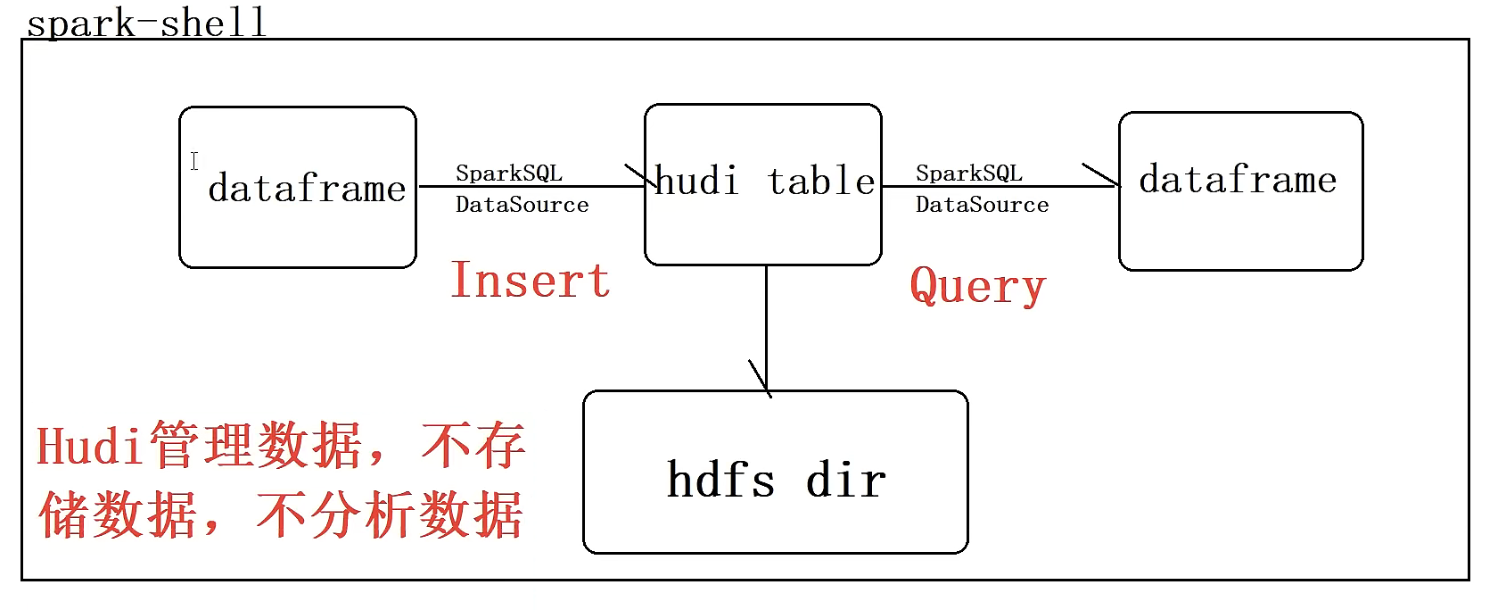
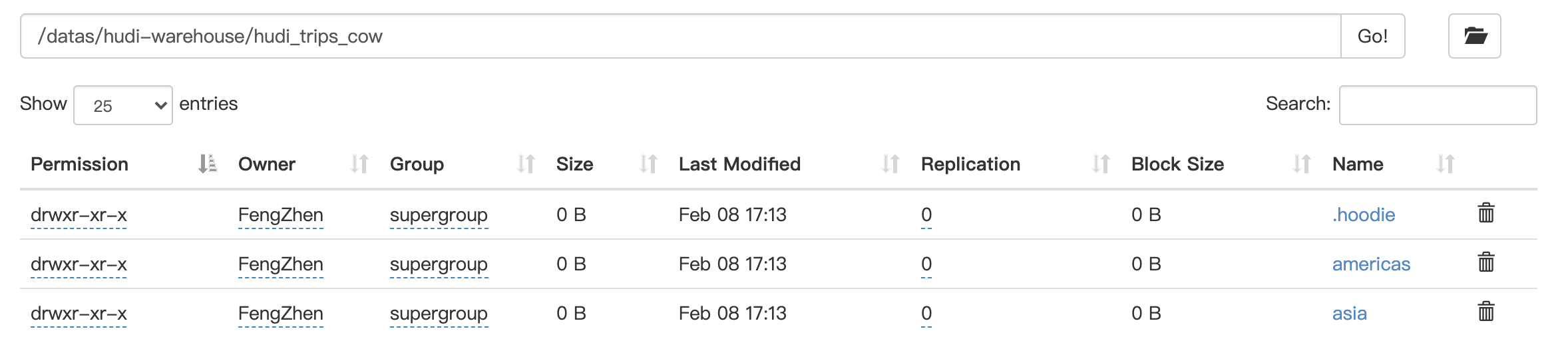
HDFS上数据存储结构如下,可以发现hudi表数据存储在HDFS上,以PARQUET列式方式存储的,有三级分区

三、通过spark读取hudi数据
val tripsSnapsshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
其中指定Hudi表数据存储路径即可,采用正则Regex匹配方式,由于保存Hudi表属于分区表,并且为三级分区(相当于hive中表指定三个分区字段),使用表达式:/*/*/*/*加载所有数据
scala> tripsSnapsshotDF.printSchema
root
|-- _hoodie_commit_time: string (nullable = true)
|-- _hoodie_commit_seqno: string (nullable = true)
|-- _hoodie_record_key: string (nullable = true)
|-- _hoodie_partition_path: string (nullable = true)
|-- _hoodie_file_name: string (nullable = true)
|-- begin_lat: double (nullable = true)
|-- begin_lon: double (nullable = true)
|-- driver: string (nullable = true)
|-- end_lat: double (nullable = true)
|-- end_lon: double (nullable = true)
|-- fare: double (nullable = true)
|-- partitionpath: string (nullable = true)
|-- rider: string (nullable = true)
|-- ts: long (nullable = true)
|-- uuid: string (nullable = true)
字段解释:
_hoodie_commit_time:数据提交时间
_hoodie_commit_seqno:数据提交序列号
_hoodie_record_key:数据row key,对应上述数据的UUID
_hoodie_partition_path:数据分区存储路径
_hoodie_file_name:数据所在文件名称
将hudi表数据注册为临时视图,采用SQL方式查询分析数据
tripsSnapsshotDF.createOrReplaceTempView("hudi_trips_snapshot”)
查找乘车费用大于20的
scala> spark.sql("SELECT fare, begin_lon, begin_lat, ts FROM hudi_trips_snapshot WHERE fare > 20.0").show()
+------------------+-------------------+-------------------+-------------+
| fare| begin_lon| begin_lat| ts|
+------------------+-------------------+-------------------+-------------+
| 33.92216483948643| 0.9694586417848392| 0.1856488085068272|1644200519234|
| 93.56018115236618|0.14285051259466197|0.21624150367601136|1644303895565|
| 64.27696295884016| 0.4923479652912024| 0.5731835407930634|1643811519875|
| 27.79478688582596| 0.6273212202489661|0.11488393157088261|1644250954765|
| 43.4923811219014| 0.8779402295427752| 0.6100070562136587|1643751609190|
| 66.62084366450246|0.03844104444445928| 0.0750588760043035|1643946541239|
|34.158284716382845|0.46157858450465483| 0.4726905879569653|1643936410360|
| 41.06290929046368| 0.8192868687714224| 0.651058505660742|1644149438138|
+------------------+-------------------+-------------------+-------------+
scala> spark.sql("SELECT _hoodie_commit_time, _hoodie_commit_seqno, _hoodie_record_key, _hoodie_partition_path,_hoodie_file_name FROM hudi_trips_snapshot").show(false)
+-------------------+----------------------+------------------------------------+------------------------------------+------------------------------------------------------------------------+
|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key |_hoodie_partition_path |_hoodie_file_name |
+-------------------+----------------------+------------------------------------+------------------------------------+------------------------------------------------------------------------+
|20220208171313818 |20220208171313818_1_4 |bec76118-3f03-4e11-b7da-c1b9cda47832|americas/united_states/san_francisco|f42b8b67-c841-49e0-8514-682a26df08de-0_1-35-34_20220208171313818.parquet|
|20220208171313818 |20220208171313818_1_7 |95c601e1-0d8a-4b4f-a441-9f7798bec7a2|americas/united_states/san_francisco|f42b8b67-c841-49e0-8514-682a26df08de-0_1-35-34_20220208171313818.parquet|
|20220208171313818 |20220208171313818_1_8 |7cc20d76-37ef-4a8f-94bb-2318b38d261d|americas/united_states/san_francisco|f42b8b67-c841-49e0-8514-682a26df08de-0_1-35-34_20220208171313818.parquet|
|20220208171313818 |20220208171313818_1_9 |427d34d4-0840-4e9f-b442-68bdbb1e62d3|americas/united_states/san_francisco|f42b8b67-c841-49e0-8514-682a26df08de-0_1-35-34_20220208171313818.parquet|
|20220208171313818 |20220208171313818_1_10|0995237e-9a58-4a9f-a58d-414f718087b1|americas/united_states/san_francisco|f42b8b67-c841-49e0-8514-682a26df08de-0_1-35-34_20220208171313818.parquet|
|20220208171313818 |20220208171313818_0_1 |80d2c5af-cc88-4775-881c-ce00bc150710|americas/brazil/sao_paulo |31556e7e-4086-4be9-b3e4-951d32ec19de-0_0-29-33_20220208171313818.parquet|
|20220208171313818 |20220208171313818_0_2 |815de54a-f3bf-495c-aa22-2ec301f74610|americas/brazil/sao_paulo |31556e7e-4086-4be9-b3e4-951d32ec19de-0_0-29-33_20220208171313818.parquet|
|20220208171313818 |20220208171313818_0_3 |54782a44-5262-4cb5-9018-4b176bfcebfe|americas/brazil/sao_paulo |31556e7e-4086-4be9-b3e4-951d32ec19de-0_0-29-33_20220208171313818.parquet|
|20220208171313818 |20220208171313818_2_5 |b05819f0-36c5-4d67-9771-af9c5a528104|asia/india/chennai |66ff0450-85af-4653-9da4-e26c4fbbc438-0_2-35-35_20220208171313818.parquet|
|20220208171313818 |20220208171313818_2_6 |8f2b5da1-4f26-447f-9bc5-bd4c9f795024|asia/india/chennai |66ff0450-85af-4653-9da4-e26c4fbbc438-0_2-35-35_20220208171313818.parquet|
+-------------------+----------------------+------------------------------------+------------------------------------+------------------------------------------------------------------------+
四、结论
Hudi如何管理数据?
使用table形式组织数据,并且每张表中数据类似hive分区表,按照分区字段划分数据到不同目录中,每条数据有主键PrimaryKey, 标识数据唯一性

















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









