







背景
没啥背景,就是想清个库存…emm 真说要说背景的话,就是云计算时代来了,大页内存在服务器上的应用越来越多了。
Tips:由于内核中大页相关的feature仍有一些在开发中,所以可能随着时间的推移,文中描述将会有不对的地方(虽然本来也可能有不对的地方),本文基于linux 5.12的内核。
大页的优点:
降低TLB miss的概率:拿普通的4KB页面和2MB的大页相比,都是使用一条页表项,能cover的内存大小却差了511倍,所以更多的使用大页能大大减少系统中页表项的数量,再加上TLB cache大小固定且有限,再再加上程序访问的地址的局部性原理,TLB miss的概率就下来了。
降低walk page table的长度:由于大页的页表级数(PGD PUD PMD)比普通页面级数(PGD PUD PMD PTE)小1,所以在走表时会高效一些。(以普通页面是四级页表为例)
综上,外在的体现就是访问内存的带宽会有提升。
推荐一篇关于大页性能测评的文章:HERE
大页的种类:
-
静态大页(persistent hugepage),通过用户自行控制它的分配、释放、使用。 关于释放:早期的内核在启动阶段预分配大页是不支持释放的,当前内核(5.12)已经支持了。
-
透明大页(transparent hugepage),由系统自己控制透明大页的分配、释放、使用。若用户开启透明大页功能,系统会在后台运行一个khugepaged的内核线程扫描系统内存,将合适的内存合并成为大页,用户无感。
本文主要介绍静态大页:后面有时间的话会单独写一篇透明大页的 (待填坑)。
静态大页的使用:
方式一:通过在bootargs传参在系统启动过程中预留大页。
bootargs参数:预分配大页数量hugepages= 和 预分配大页的大小hugepagesz= ,更详细的使用可参看内核文档kernel-parameters.txt
方法一相对于方法二的优点是开机时就通过bootmem分配大页,不存在因为内存碎片导致分不出大页的情况,从而保证预留的成功性。
方式二:通过sysfs下的文件节点申请和释放大页
echo 5 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
含义:保持系统中2MB的大页有5个。若已经存在5个大页则什么都不做;若少于5个则分配够5个;若多于5个则释放多余的大页(前提是未被使用)。
echo 5 > /sys/devices/system/node/node[0-9]*/hugepages/hugepages-2048kB/nr_hugepages
含义:在指定的numa node上分配5个指定大小(2MB)的大页。
cat /sys/kernel/mm/hugepages/hugepages-2048kB/free_hugepages
含义:查看系统中空闲的的2MB大页的数量
编程中使用静态大页:
通过mmap接口申请内存时在flag中添加MAP_HUGETLB,并在参数len中设置页面的大小。
透明大页的使用:
通过/sys/kernel/mm/transparent_hugepage下的节点控制THP的开关、积极程度等行为。
详见官方文档:HERE
相关概念澄清:
本文首先假设读者对内存管理源码有一定的认识,接下来我们澄清几个概念:
大页内存池:在内核中有一个全局的大页内存池,它管理着系统上所有节点上的、各种大小的、已使用的、未使用的大页。当池中的页面不够时,则会通过系统分配大页填充池子,当池中的页面盈余(盈余的概念见我下面对surplus_huge_pages的注释)时,则会从池子中释放一部分的空闲页面。这个大页内存池结构如下:
struct hstate {
int next_nid_to_alloc;
int next_nid_to_free;
unsigned int order;
unsigned long mask;
unsigned long max_huge_pages;
//系统中全部的大页数量,包含surplus页面,sysfs下同名节点就是控制它的
unsigned long nr_huge_pages;
//系统中未被使用的大页数量,也包含resv_huge_pages的页面
unsigned long free_huge_pages;
//应用程序已经mmap的大页数量,未读写,即未分配实际物理页。但是这些pages也已经不可被别人用了。
unsigned long resv_huge_pages;
/*系统中超过nr_huge_pages的大页数量,可以超分的数量被/proc/sys/vm/nr_overcommit_hugepages控制,
若nr_huge_pages被改小了,但是页面仍in-use,结果就是nr_huge_pages不变,而增加surplus_huge_pages
的数量,以至于shrink的时候会根据surplus_huge_pages释放已经不用的页面。*/
unsigned long surplus_huge_pages;
//它控制着surplus_huge_pages的最大值。
unsigned long nr_overcommit_huge_pages;
struct list_head hugepage_activelist;
struct list_head hugepage_freelists[MAX_NUMNODES];
unsigned int nr_huge_pages_node[MAX_NUMNODES];
unsigned int free_huge_pages_node[MAX_NUMNODES];
unsigned int surplus_huge_pages_node[MAX_NUMNODES];
char name[HSTATE_NAME_LEN];
};
注意:对照sysfs下大页相关的文件节点,你会发现许多与大页内存池数据结构成员同名。
复合页面(compound page):复合页面是由两个及以上的连续普通页面组成,与伙伴系统分配出的order-N的连续页面相比,复合页面的meta data不太一样。复合页面的第一个页面称之为head page,剩下的pages称为tail page。tail page中的第一个page的struct page又和剩下的tail page中的元数据不太一样,但是所有的tail page的struct page中的mapping指针都会指向head page的struct page,这样就可以通过任何一个tail page找到head page了。具体细节读者可以查看内核源码中struct page里的compound page部分的定义(这块新内核中也不时会有扩充和改动)。
huge page 与 gigantic page的区别:页面大小小于MAX_ORDER的大页称之为huge page,大于等于MAX_ORDER的大页称之为gigantic page,拿常用的举例,2MB是huge page,1GB是gigantic page。huge page和gigantic page走的是不同的分配路径。huge page相对较小,所以通过伙伴系统来分配(注意:虽然走伙伴系统,但最终它的元数据设置和普通伙伴系统页面的设置是分开处理的),而gigantic page页面较大,伙伴系统无法满足分配要求,所以通过连续内存分配接口alloc_contig_range()(没错,CMA内存也走这里)
大页内存的状态: head page的page.private中存放了当前大页的状态。共四种状态,如下:
HPG_restore_reserve //当大页被用户用mmap申请了,但并未实际使用前,会处于此状态
HPG_migratable //若此大页支持迁移,分配出来时会被设置此标志
HPG_temporary //临时从伙伴系统中分配出的大页,典型的应用是作为migration的target page。
//后文释放大页的流程中会对它进行判断。
HPG_freed //当页面为空闲是会被挂载free list上,同时设置此flag
大页内存的分配:
前面我们说到,静态大页的分配方式有两种,本文我们只介绍通过sysfs分配大页的流程,因为笔者个人觉得以sysfs的方式现在的灵活性完全可以取代bootargs的方式。至于sysfs可能由于内存碎片导致大页分配失败的问题,可以通过在系统启动后立马通过脚本去预留,那时是不存在内存碎片问题的。
比方现在系统中有4个2MB的大页,通过下面的命令再去增加1个2MB的大页
命令:echo 5 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
内核中的执行则是:nr_hugepages_store ->__nr_hugepages_store_common ->set_max_huge_pages
接下来看一下核心实现set_max_huge_pages():
set_max_huge_pages
->alloc_pool_huge_page //若大页内存池中大页不够,则再分配一个新的大页放入大页内存池中。
->alloc_fresh_huge_page //在指定的node上分配一个新的大页
->alloc_gigantic_page //1GB大页走这里。基于CONTIG_ALLOC或CMA内存分配
->alloc_buddy_huge_page //2MB大页走这里。基于伙伴系统分配
->prep_compound_gigantic_page //元数据初始化。若是gigantic页,设置first tail_page的order,并设置所有tail_page指向head_page.
->prep_new_huge_page //元数据初始化。1.将page[0]的lru指向自己 2.设置hugetlb的析构函数类型 3.设置page[2]和page[3]的相关cgroup成员private变量
//3.拿大页内存池锁hugetlb_lock,并更新hstate中页面numbers 以及 设置page[0]的private的状态标志HPG_freed
下面是具体huge page和gigantic page分配细节:
alloc_gigantic_page //1G巨页
->cma_alloc //新加进来的feature,通过预留hugetlb_cma内存用以分配巨页。
->__alloc_contig_pages //形参MIGRATE_CMA.
->alloc_contig_pages //若未开启CONFIG_CMA或hugetlb_cma中的内存用完了则走这里。
->1.根据zonelist逐个在zone上逐个取1GB的pfn range.(注意两点:1先在当前zonelist上找,找不到再根据nodemask换zonelist继续找;2 migrate_movable的fallback不包含migrate_cma)
->2.找contig page需要在zone上1GB对齐,然后通过pfn_range_valid_contig()检查pfn range中的page是否可用,不可用换下1GB pageblock。
->3.__alloc_contig_pages //形参MIGRATE_MOVABLE. 原理和memory compaction一样。详见下文大图
alloc_buddy_huge_page //2MB巨页
->__alloc_pages_nodemask
->get_page_from_freelist
->rmqueue
->prep_new_page
->post_alloc_hook //页面基本信息的初始化。第一个页面的refcount初始化为1,private初始化为0。若设置了DEBUG_PAGEALLOC,则检查page的poison并unpoison
->prep_compound_page //元数据初始化。第一个page设置PG_head,refcount保持1. tail page的compound_head指向head并bit0置1,refcount重置为0.
//设置first tail的compound_dtor,设置first tail的compound_order,设置first tail的compound_nr的页面总数
以上我们可以看到huge page的分配走的是伙伴系统(参考Linux内存管理:伙伴系统实现一文)。gigantic page走的是连续内存分配__alloc_contig_pages()。
__alloc_contig_pages()很重要,涉及的知识点也较多,这里画了一幅图来说明它的大体流程:
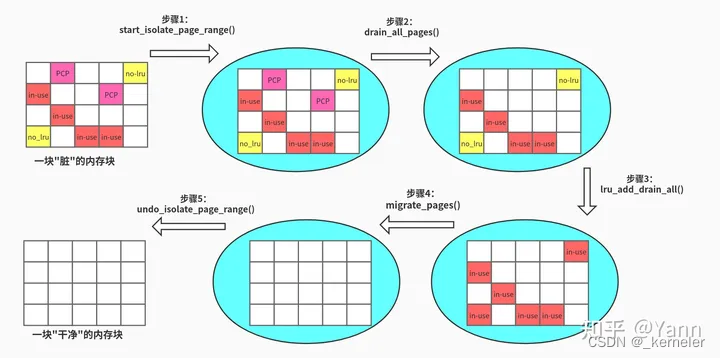
步骤1:将目标内存块(内存块的大小是pageblock整数倍,你懂的,因为内存的迁移属性是按pageblock划分的)的迁移属性标记为MIGRATE_ISOLATED,这样被标记的内存将不会被伙伴系统分配出去,方便我们后续的迁移工作。
步骤2:将PCP(per-cpu pages)的内存池清空,即将页面归还给伙伴系统,并临时关闭了pcp功能。(mm, page_alloc: disable pcplists during memory offline)
步骤3:将准备添加到LRU链表上,却还未加入LRU的页面(即还待在pagevec中的页面)添加到LRU上(后面补篇LRU的文章,待填坑)。这是为了后面migrate_page()迁移做准备,因为migrate_page()需要从LRU链表上摘取待迁移的页面,并isolate(此isolate非迁移属性的isolate)
步骤4:调用migrate_pages(),将已经有内容的页面(in-use)迁移出去。(参考之前的文章Linux内存管理:页面迁移)
步骤5:跟步骤1反着来,恢复内存块的迁移属性。至此,我们获得了一块干净且连续的内存。
大页内存的释放:
接口:put_page()
此接口既可以用来释放order-0的页面,也可以用来释放各种复合页面,包括普通复合页面、大页、透明大页。
原理:回看分配大页的流程中,在设置大页元数据时prep_new_huge_page()->set_compound_page_dtor()会去初始化大页的析构函数。而在put_page()中,若大页的refcount==0时,则会去调用它的析构函数。
实现:对大页中的任何一个页面执行put_page()最后都是对page[0](即head page)的refcount减1,当refcount为0时会去调用大页的析构函数去释放大页。
put_page
__put_page //若此次减1后refcount为0,则接着下面的步骤
__put_single_page //普通的order-0页面走这里
__put_compound_page //复合页面走这里
__page_cache_release //若是THP的话先做处理下它的page[0].lru,普通大页不需要
destroy_compound_page //调用复合页面的对应的析构函数page[1].compound_dtor。内存回收时也可能调析构函数用来回收compound page
free_compound_page //普通复合页的释放
free_huge_page //静态大页的释放,接下来详细介绍它
free_transhuge_page //透明大页的释放
核心实现:
由于put_page()可以在中断中调用,我们知道中断中是不允许特别耗时的操作的,而释放一个可能达到若干GB的大页来说,当然不会很迅速。于是free_huge_page()中就添加了在中断里释放复合页面的额外处理,defer到延时工作队列里去释放。判断如下:
free_huge_page
if !in_task
schedule_work(&free_hpage_work) //中断中走workqueue推迟释放
__free_huge_page //workqueue最终调__free_huge_page
else
__free_huge_page //进程上下文的话,直接调__free_huge_page
__free_huge_page()的流程 :
__free_huge_page
hugetlb_set_page_subpool
page->mapping = NULL
ClearHPageRestoreReserve
hugepage_subpool_put_pages
ClearHPageMigratable
hugetlb_cgroup_uncharge_page
hugetlb_cgroup_uncharge_page_rsvd
if 情况1:HPageTemporary //该hugepage是temporary状态
list_del(&page->lru) //将该hugepage从freelist或activelist上直接移除
update_and_free_page //释放该hugepage,详见下文
else if 情况2:surplus_huge_pages_node //当前node上有surplus不为零
list_del(&page->lru) //将该hugepage从freelist或activelist上直接移除
update_and_free_page //释放该hugepage,详见下文
h->surplus_huge_pages-- //减少hstate中surplus的页面和对应node的surplus的页面数量
h->surplus_huge_pages_node[nid]--
else 情况3:hstate池中的page总数无需改变
enqueue_huge_page //将页面加入大页内存池的free list上,并设置页面状态为HPG_freed
update_and_free_page //注意:此时已经持有hugetlb_lock锁
hstate //更新页面数量
set_compound_page_dtor //清空析构函数
set_page_refcounted //要被释放head page的refcount为0,此时置1用来后续释放页面使用
if gigantic_page
destroy_compound_gigantic_page //设置所有的tail page的refcount为1,释放时使用;清空head page和tail page的成员
free_gigantic_page //逐页的释放掉所有的page
else buddy_page
__free_pages //huge page的话直接走buddy释放。Tips:普通的order>0的伙伴系统页面也走这里释放:free_pages->__free_pages















 4764
4764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









