




Jesd204b(串行接口):将采样的高速AD/DA数据与逻辑器件通信,进行数据传输的协议;
最大线速率支持 12.5G;
线速率:单个Lane(高速接口差分对)传输的速率
JESD204B与LVDS 接口参数比较:
- Jesd204b接口更节省IO资源;
- PCB板面积jesd204b只需要1层布线;
高速串行数据流恢复技术:
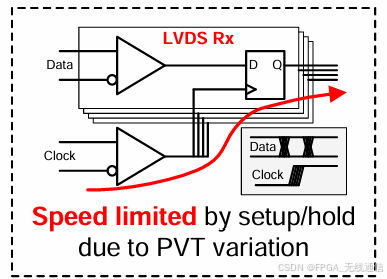
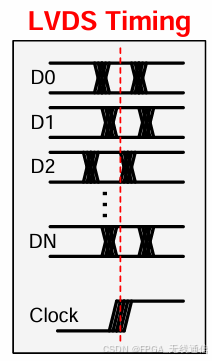
LVDS方案时钟对齐是根据不同电压温度路径来校准延迟保证时钟和数据满足建立和保持时间门限,恢复串行bit流;
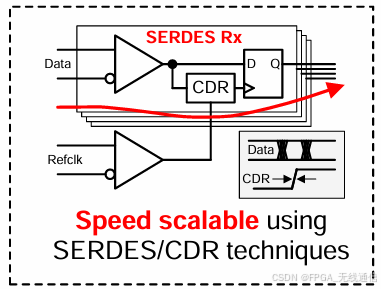
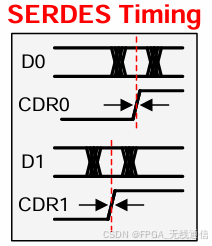
Jesd204使用serdes技术,高速接口的时钟是从数据中使用CDR技术调制参考时钟的时钟相位位置,对齐数据有效采样窗完成的采样;
Jesd204b 支持3个子类;
常用的为子类1,使用sysref进行确定性延迟的同步;
特点:确定性延迟,sysref,sync,device clock;
对于frame、LMFC、sampling clock 都是由device clock 时钟派生出来的;
L:Lane数;
M:ADC/DAC 通道数;
F:每帧多少个字节;
Clock generater:产生SYSREF;
SYSRFE:对齐LMFC;与device clock 源同步产生;
确定性延迟:固定延迟 + 变化延迟;
对于jesd204b来讲,从采样数据输入到 jesd204b发送端 到jesd204b接收端采样数据输出这段时间的延迟是确定的;
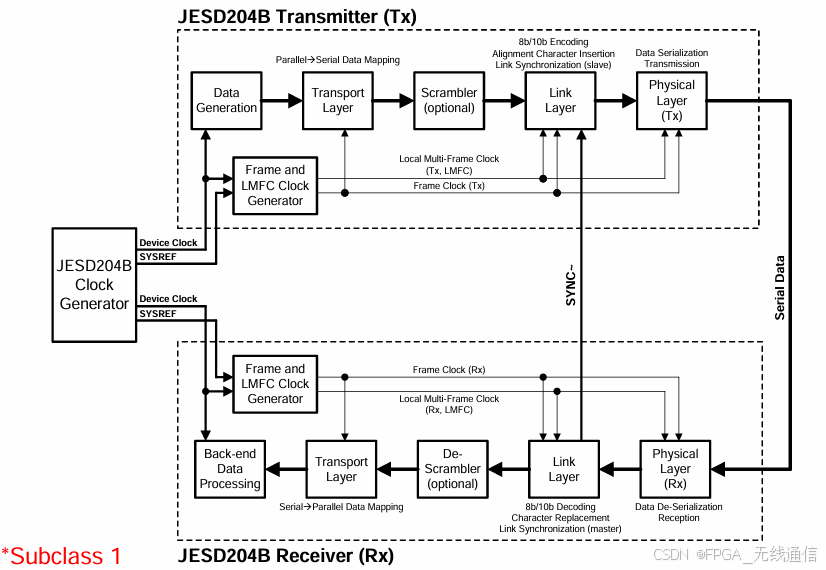
物理层架构:
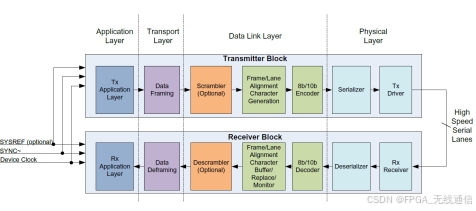
传输层:
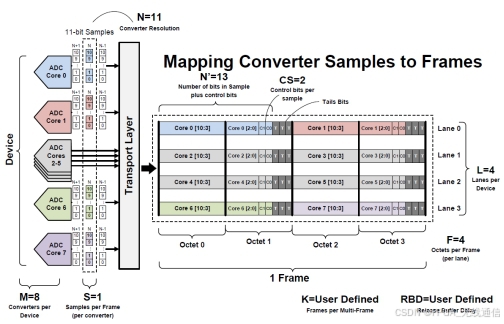
线速率:每个lane传输的bit 速率;
Fs:采样率每秒钟采样的次数定义;
bits:采样深度,采样量化bit,ADC或DAC的量化比特;
线速率计算:
假定采样率FS = 100M;
ADC通道8个,bit位宽16;lane =4;
8B/10B 编码前线速率:100M x 8 x 16 / 4 = 3.2G ,每条lane的线速率;
编码后:3.2G / 0.8 = 0.8 4G;
另一种方法:(根据上图参数计算)
编码前:Fs/s * F * L * 7 /L = 100M/1 * 4 * 4 * 8 /4 = 3.2G;
编码后:3.2G/0.8=4 G;
AD9371结构框图:
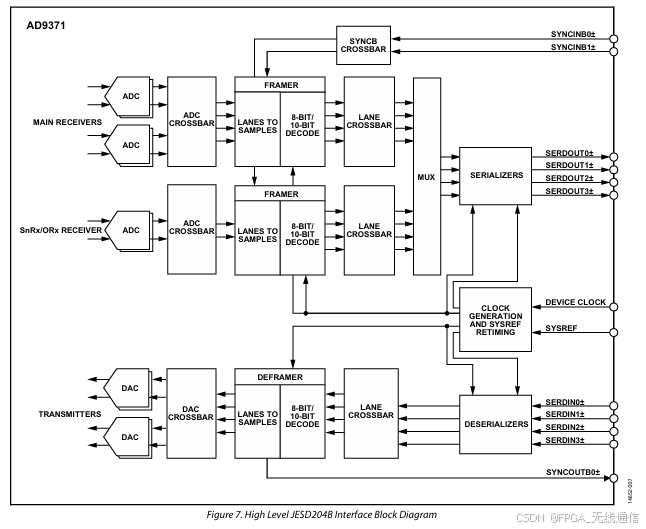
接收和发射均为4个ADC和DAC;分IQ;
fpga给出来,用于同步的:
右侧信号与FPGA相连接;
采样率:122.88M
采样深度:16bit;
ADC通道:4;
有4条Lane;
线速率计算: 122.88 * 16 * 4(ADC) / 0.8 / 4(Lane) =2,457.6 M ≈ 2.4G;
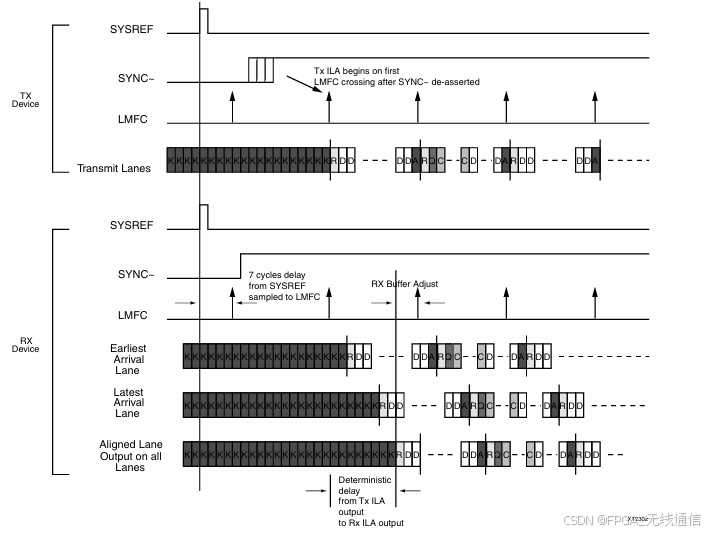
Subclass 1 建立连接过程(TX端):
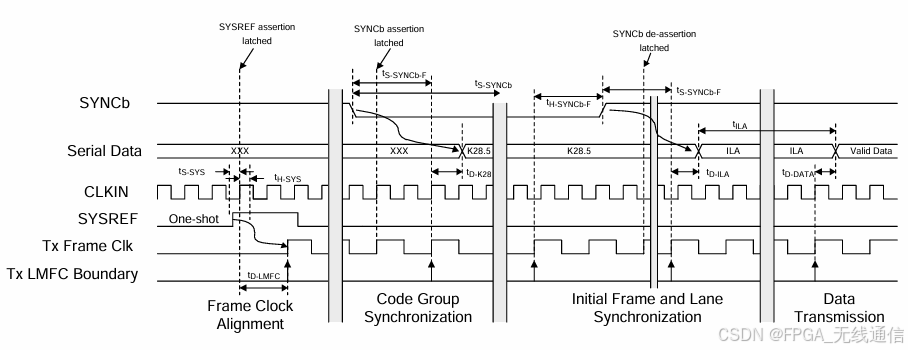
SYNCb:同步信号,由RX侧提供;
Clock generater 产生 CLKIN(device clock)和SYSREF;
第一阶段:SYSREF产生,触发同步,产生 TX frame clk 和 LMFC clk;
LMFCOffset可以指示0~31,为本地多帧计数器的偏移值,最大为32个frame组成一个LMFC;
LMFC边界与第一个frame clk 上升沿对齐的;
第二阶段:CGS组码同步,接收数据方拉低SYNCb信号触发同步开始;
TX侧输出K28.5同步码,直到RX方把SYNCb拉高;RX方至少接收到4个连续的K28.5才能拉高;
第三阶段:ILAS阶段,完成Lane 的对齐;
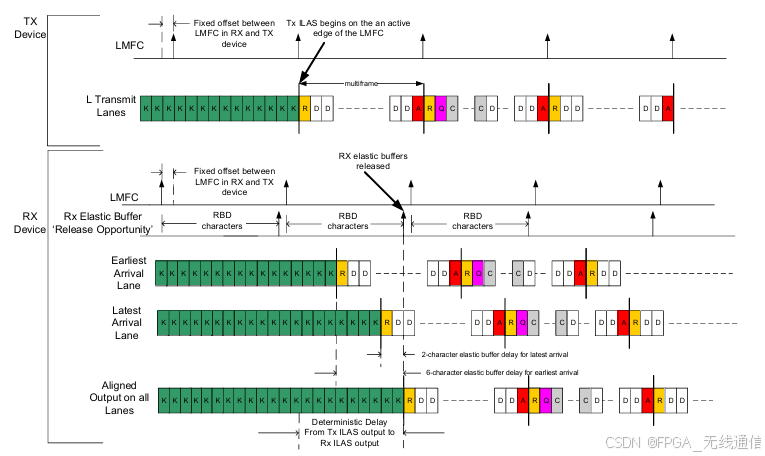
从多帧的边界开始向FIFO中存数,Earilest arrival Lane 存一个FIFO,Latest Arrival Lane存一个FIFO,当RBD边界到来的时候,且这两个FIFO中都存了多帧起始R字符的时候,就开始读数据;相当于按照读的边界将数据读出,完成Lane的对齐;每个Lane对应一个FIFO,每个Lane都存了R码,就可以开始FIFO 读,完成对齐 ILAS;
帧边界对齐;从多帧的边界开始/R/,往RBD里面存数;在最早到达的Lane检测到/R/时将数据存入FIFO,最晚到达的Lane检测到起始/R/的时候将数据存入FIFO,当RBD边界到来,并且两个FIFO都存入了多帧的起始/R/时,就开始从FIFO里往外读数,此时两个FIFO(每个Lane存在一个FIFO)都会按照读的边界进行数据同步读出;RBD不存K码,RBD值可设置,1<RBD<32;
初始化LANE对齐,会发4个多帧,对齐之后才会进入用户数据传输阶段;
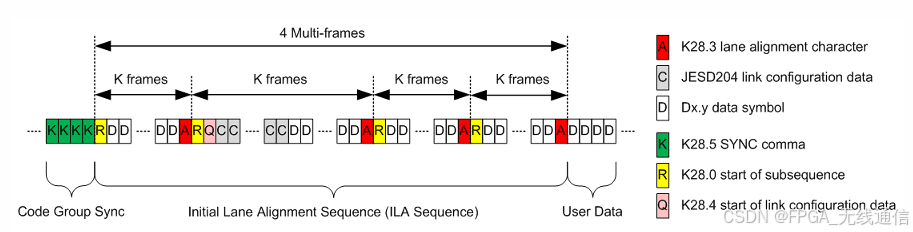
传输层接口定义
AD9371:高8位先发;
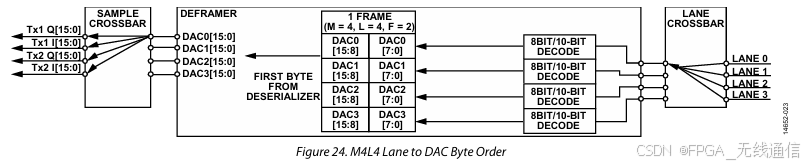
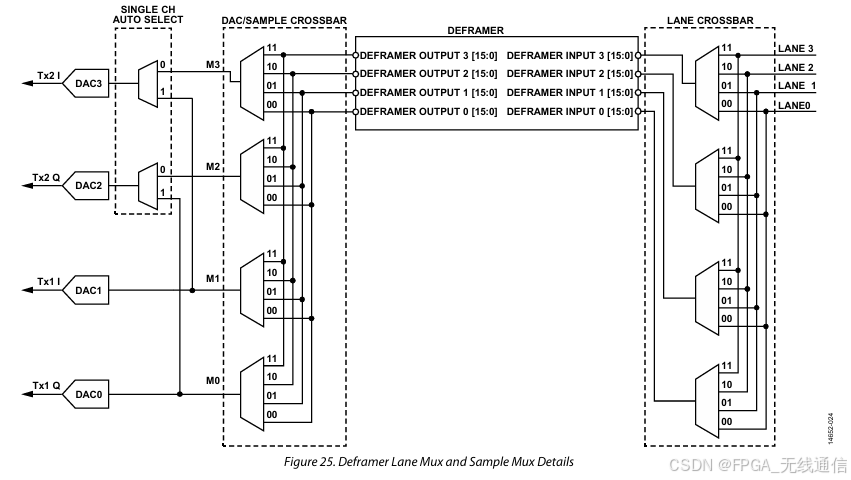
通过上图(RX相同),根据以下2个参数,确定了Lane的走线以及与Tx 的对接关系,通过该关系,就知道了I Q 的排序,即{Tx2Q, Tx2I, Tx1Q, Tx1I};rx也是相同原理,这样就能够确定在jesd204b的数据接口,其 I Q 数据谁放低位,谁放高位;
AD9371初始化函数相关参数:deserializerLaneCrossbar、MYKONOS_ADDR_DEFRAMER_DAC_XBAR_SEL;
数据排列:先发高字节,再低字节;发送的高字节放xilinx IP 的低8位;
FPGA 数据通过LANE给到DAC:(ADC是采集数据给FPGA的Lane)
deserializerLaneCrossbar 配置值可知Lane crossbar 对应关系;
MYKONOS_ADDR_DEFRAMER_DAC_XBAR_SEL 配置值可知dac/sample crossbar 对应关系;
MYKONOS_ADDR_DEFRAMER_DAC_XBAR_SEL=0xB1 = 10110001
Tx1 Q 为01;Tx1 I 为00;Tx2 Q 为11;Tx2 I 为10;
deserializerLaneCrossbar = 0xE4 = 11100100
LANE0 为00;LANE1 为01;LANE2为10;LANE3为11;
Xilinx 接口关系:32位对应一个Lane,最低的8位先发;

TX_TDATA[31:0]包含了DAC的两次采样;第一次采样放低16位,第二次采样放高16位;
即 Lane0 对应 I 路的 2 个采样;
对应用户的接口都是32位递增,低32位对应Lane0;
先发低字节,即最低 8 位先发;
给xilinx 的tx_tdata接口赋值时,高字节放低8位,低字节放高8位;
假设TX1I[15:0],TX1Q[15:0],TX2I[15:0],TX2Q[15:0],如何赋值给FPGA接口 axis_tx_tdata[127:0]接口?
满足对应关系:
MYKONOS_ADDR_DEFRAMER_DAC_XBAR_SEL=0xB1 = 10110001
Tx1 Q 为01;Tx1 I 为00;Tx2 Q 为11;Tx2 I 为10;
deserializerLaneCrossbar = 0xE4 = 11100100
LANE0 为00;LANE1 为01;LANE2为10;LANE3为11;
Lane0 = Tx_tdata[31:0] = {Tx1I_1[7:0],Tx1I_1[15:8],Tx1I_0[7:0],Tx1I_0[15:8]};
Lane1 = Tx_tdata[31:0] = {Tx1Q_1[7:0],Tx1Q_1[15:8],Tx1Q_0[7:0],Tx1Q_0[15:8]};
Lane2 = Tx_tdata[31:0] = {Tx2I_1[7:0],Tx2I_1[15:8],Tx2I_0[7:0],Tx2I_0[15:8]};
Lane3 = Tx_tdata[31:0] = {Tx2Q_1[7:0],Tx2Q_1[15:8],Tx2Q_0[7:0],Tx2Q_0[15:8]};
每条Lane 对应了两个采样点;


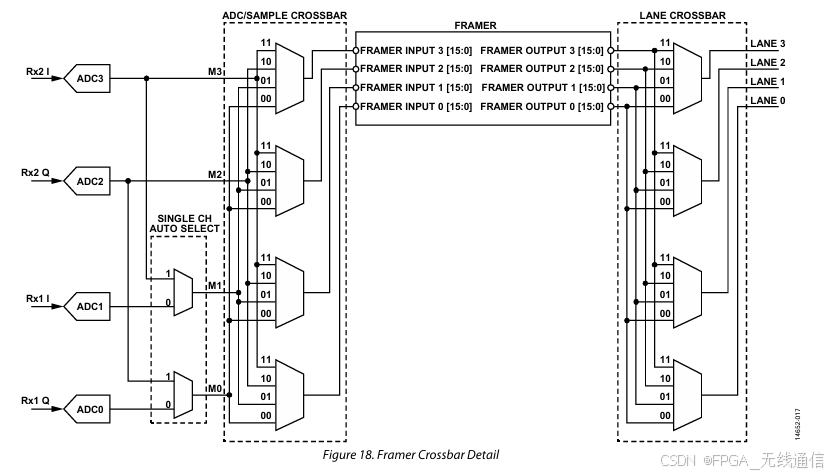
上图,Lane0对应RX1I,在xlinx IP中 Lane0 为32位,而 Rx1I 为16位,所以Rx1I到Lane0的映射关系应该是 2 个16位的 Rx1I 映射到Lane0的32位,且每个16位的高8位即[15:8]先输出,其次为[7:0]; TX相同,Lane0对应2个Tx1I的输出;

Axis_rx_tdata[127:0]对应RX IQ关系:
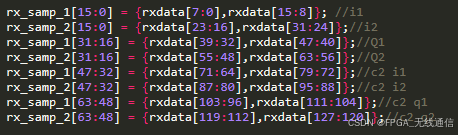
RX1I 两个采样点构成一个32位;此处AXI_Stream的接口时钟为采样率时钟的1/2;
一次出来2个采样点,对应时钟就降低为原来的一半;

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









