







摘要
在这篇文章中,作者研究了图上的一种攻击,GIA图注入攻击。这篇文章的攻击方法并没有修改原图的链路结构(删除或者是添加边)或者是结点属性,而是直接往图上注入(inject)对抗结点。作者提出了拓扑缺陷图注入攻击(TDGIA),首先使用拓扑缺陷边选择策略来选择和注入结点有联系的原始图上的结点。然后使用平滑特征优化方法来获取注入结点的特征。在大型数据集上的实验表明,TDGIA的表现要优于已有的攻击baseline的结果。作者拿自己的攻击方法参加了KDD-CUP2020的比赛,发现使用了TDGIA后GNN模型的性能下降效果是之前最好的攻击方法性能下降效果的2倍。
Introduction
最近几年,图神经网络被用于建模结构化和关系型数据。图神经网络可以用于节点分类,社交推荐和药物设计。对于神经网络的攻击通常是直接修改输入实例的属性/特征,例如直接在图片上添加单个像素的扰动。
早期对于GNN的攻击是GMA(graph modification attack),如图1(a)所示,给定一个输入图,直接修改结点之间的链路(删边或者加边),或者是修改已有结点的属性。但是在真实世界中,很难可以获得修改数据的权限。以引文网络为例,这个网络是每次在论文出版的时候就自动形成这个网络了,所以就很难在之后再去修改某个出版物的引用情况和属性。跟修改原图的链路或者结点属性相比,更简单的是添加新的结点并且将这个结点跟原图中的其他节点产生关联。比如,通过出版虚假的paper,就可以导致最后错误的GNN预测结果。
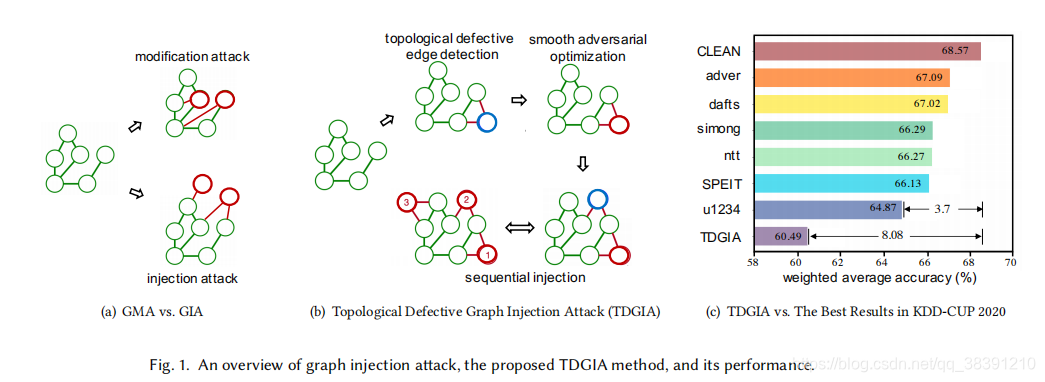 在KDD-CUP2020这个比赛中的GIA任务定义如下:1)黑盒攻击,意味着攻击者不能直接获得目标的GNN模型,也无法得知目标结点的正确标签。2)躲避攻击(Evasion Attack),意味着攻击只能发生在inference也就是推断的阶段。在做GIA攻击的时候会遇到一些GMA不会遇到的问题,例如怎样去连接原有结点和新添加的结点,以及怎样给新添加的结点赋予属性。尽管有很多人都在做这种攻击,但是带来的效果并没有很好。
在KDD-CUP2020这个比赛中的GIA任务定义如下:1)黑盒攻击,意味着攻击者不能直接获得目标的GNN模型,也无法得知目标结点的正确标签。2)躲避攻击(Evasion Attack),意味着攻击只能发生在inference也就是推断的阶段。在做GIA攻击的时候会遇到一些GMA不会遇到的问题,例如怎样去连接原有结点和新添加的结点,以及怎样给新添加的结点赋予属性。尽管有很多人都在做这种攻击,但是带来的效果并没有很好。
TDGIA包括有两个模块:首先是选择出defective edge,并且得到添加的结点的属性,这是GIA的问题步骤。之后会把原图中的脆弱结点给拿出来,这部分结点应该是可以很好的辅助到攻击,然后再序列化的在这些脆弱结点附近添加新的结点。作者设计了一个损失函数,直接优化结点特征这个属性,使得目标GNN模型的表现差。
下面的表格对比了本文方法和前面的方法。NIPA和AFGSM是投毒攻击,意味着在对输入图进行了污染之后需要对模型进行重新训练从而产生新的模型。而本文的TDGIA是规避攻击,意味着模型的权重是一直固定的。而且TDGIA可以攻击大规模的图,而这类图往往是不能被NIPA攻击的。之前的方法只能攻击一些比较弱的防御模型,但是本文的方法可以攻击KDD-CUP2020上最top的防御模型。而且本文的攻击方法是可以攻击整体的模型效果,而不是单个数据。
Contribution
实验结果表明TDGIA的表现要明显优于之前很多的baseline方法。例如,之前KDD-CUP2020最好的攻击方法可以使得目标的GNN模型的表现下降3.7%,但是TDGIA却可以使得这个模型的表现下降8.08%。除此之外,作者还提到,TDGIA方法只添加了少量的结点(1%的目标节点)。而且作者使用了很多的消融实验,发现TDGIA中的每个模块都不可缺少,作用很大。
总而言之,本文有如下几个贡献:
1)本文的攻击是黑盒攻击,而且是规避攻击,一些non-structural-ignorant的GNN模型很容易受到本文方法的攻击。
2)作者使用了TDGIA这种攻击方法可以充分挖掘GNN模型的拓扑属性和脆弱性。
3)通过实验发现,TDGIA的攻击效果要优于其他的baseline模型。
相关工作
(1)神经网络的对抗攻击
最先发现神经网络的脆弱性是在计算机视觉领域。通过在图像上添加微小的不可见的扰动可以直接改变深度神经网络的预测结果。刚开始是提出了FGSM方法可以通过利用目标网络的梯度从而产生扰动。之后对抗攻击也被应用在自然语言处理和语音识别领域。现在对抗攻击已经成为神经网络的主要威胁。
(2)GNN的对抗攻击
之前有人提出了基于强化学习的攻击用于节点分类和图分类任务。这类攻击是直接修改图的结构。之后有人提出了Nettack,这是第一个在属性图上的对抗攻击,这篇文章提出来,只有同时对图上的边和结点属性进行修改才能对GCN这类模型产生攻击的效果。Nettack使用了一个贪心策略来实现攻击,之后又有人提出了投毒攻击,通过使用meta-learning元学习,meta-attack来实现投毒攻击。之后有人提出了GIA,GIA攻击的实用性更高(大概就是直接添加新的结点比修改原图结点属性或者是修改原图的边要更实用一些。)。之后又有人提出了NIPA,直接使用强化学习方法。之后又有人提出了AFGSM可以直接对模型做线性化可以有效的产生扰动。但是这些方法都是投毒攻击,也就是说,它们在往原图中添加完新的结点之后必须对模型做retrain也就是重新训练。(这里才是本文的创新之处吧,本文是规避攻击不需要重新训练。)
所以图对抗攻击的发展趋势是这样的,从GMA(修改原图的结点属性,删边,加边)到GIA(直接添加新的结点,更加实用,可以实施物理攻击)。从投毒攻击到规避攻击(不需要retrain,所以攻击更好实施。)
(3)KDD-CUP2020图对抗攻击和防御方法
KDD-CUP2020引入了GIA场景,并且没有获得目标模型的权限(黑盒攻击),并且在一张超过600000结点,百万链路的图上只能添加500个结点。
对攻击者而言,只能在inference推断的阶段进行攻击,也就是规避攻击。对于防御者而言,他们需要提供鲁棒的GNN模型来防御不同的对抗攻击。
问题定义
广义上讲,图对抗攻击可以分为两种:GMA(graph modification attack)和GIA(graph injection attack)。这篇文章是GIA。
(1)GMA
图对抗攻击最初是在Nettack中提出,刚开始就是GMA。定义了一个邻接矩阵G大小为NN,另一个是D维的节点特征F大小为ND。M就是一个模型可以预测图中的每一个节点的标签。GMA的目的是,通过对原来的图G做修改,从而使得目标节点集中的正确预测的节点数目尽可能的少。(所以这里可以注意到,我们的目标不是针对单个的节点,而是针对图上的所有结点。)整个过程如下所示:
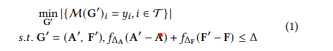
目标是使得被正确预测的节点数目尽可能少,约束条件是要使得对于矩阵G和矩阵F的修改尽可能的小。
(2)GIA
GIA做的事情是,直接往图G上添加NI个新的节点,但是原始的边以及N个节点的特征是没有被改变。
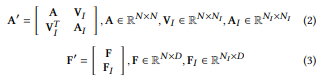
可以看到GIA在添加了NI个新的节点之后,邻接矩阵变成了A‘,节点特征矩阵变成了F’。
整个的损失函数如下,目标变成了使得修改后的图上的正确预测的节点数尽可能的少,约束条件变成了约束添加的节点数NI,NI个节点的度数以及NI个节点构成的特征矩阵FI的大小。
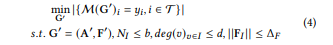
(3)GIA的攻击设置
最近有很多人研究GIA,并且它也作为了KDD-CUP2020比赛的一项任务。因为GIA在现实生活中有很强的应用,所以作者依旧使用了比赛中的设置,那就是黑盒攻击并且是躲避攻击(evasion attack)。
黑盒攻击。在黑盒攻击中,攻击者没有接触到目标模型M的权限,也即是攻击者不知道目标模型的结构,参数以及防御策略。但是攻击者可以接触到原始的属性图G,并且攻击者可以知道训练和验证集中节点的标签,但是这些节点都不应该是被攻击的节点。(??这里是什么意思)
躲避攻击。躲避攻击的意思是,攻击者只能在目标模型做inference的时候实施攻击,此时模型已经结束训练了,所以修改后的数据并不会对模型的训练过程产生影响。
除此之外,KDD-CUP2020的数据集要明显大于现有的图攻击研究的数据集。所以这个任务要更加接近于真实世界,同时也需要更大规模的攻击。
(4)GIA的整个流程
因为本文是黑盒攻击和躲避攻击,所以GIA需要通过代理模型来实施迁移攻击。(所以归根结底还是迁移攻击,那为什么要整的很高级似的??)首先,训练一个代理模型,然后在这个代理模型上实施injection attack,最后将这个攻击迁移到目标模型上。
为了可以很好的应对大规模的数据集,GIA在实施的过程中可以分成两步:首先是要建立新添加的节点和已有的原始节点之间的联系(也就是修改邻接矩阵),然后再对新添加的节点的特征做优化。把整个攻击过程分成这两步可以有效的提高攻击效率,从而可以应用于大规模的图。
攻击的目标模型可以是任意的一个图机器学习模型,本文选用的是图神经网络模型。
图injection attack下的GNN
这部分,作者分析了图神经网络GNN在injection attack下的行为。通过分析这个行为可以设计更加有效的GIA策略。
(1)GNN在GIA攻击下的脆弱性(这部分后面再细看,理论有点难以理解)
GIA的损失函数要求被注入的节点要在边与边之间传播信息,从而可以影响到其他已有的节点。那么,有哪些模型容易受到这些新添加的节点的影响呢?在这个部分,作者研究了GNN模型在受到GIA攻击后的脆弱性。
定义一(特征之间没有空间位置关系):给定一个图,如果对于任意的G‘(G’是G的一个排列组合)来说,如果M (G′)𝜎𝑖 =M (G)𝑖,那么图机器学习模型M的特征之间是没有空间位置关系的。(这里没有看懂,后面再看。。。)
定义二(GIA-attackable):如果存在有两个图G1和G2,它们有相同的节点i,G1是G2的一个子图,并且M(G1)不等于M(G2),那么模型M是GIA-attackable的。(这里也没有理解。。。啥玩意)
一个GIA-attackable的图机器学习模型是这样的,攻击者可以通过往原始图上注入新的节点从而使得图上特定节点的预测会出错。
(2)GNN的拓扑脆弱性
为了更好的研究GNN的注入攻击,作者思考了GNN的拓扑脆弱性。总的来说,GNN在一个节点v上的行为可以看作是一个聚合的过程。
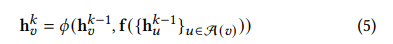
聚合的过程如上图所示,可以看到,其中的f和
ϕ
\phi
ϕ代表的是一个向量函数,A(v)代表的是v的邻居节点。
h
v
k
h_v^k
hvk代表的是节点v在k层的隐含表示。可以看到,A(v)表示的是节点v的直接邻居节点以及在特定step之后可以连接到节点v的所有节点。
A
t
(
v
)
A_t(v)
At(v)可以看作是v节点的t跳跃邻居节点。将
f
t
(
.
)
f_t(.)
ft(.)看作是一个聚合函数。所以上面的聚合函数又可以写成如下形式:
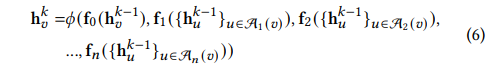
可以看到,当前k层的信息与k-1层的很多节点都有关系。
因为需要通过注入新的节点从而对原始图做干扰,所以
A
t
A_t
At就变成了
A
t
′
A'_t
At′,而且
f
t
f_t
ft也会发生变化,所以对于节点v在第k层的新的嵌入就变成了如下形式:
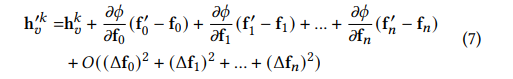
将其中的偏导转换成
p
t
,
k
p_{t,k}
pt,k之后整个的公式就变成了如下形式:
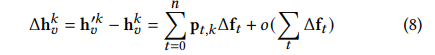
作者假定
f
t
f_t
ft有一个加权平均的形式,那么就可以写成如下形式:
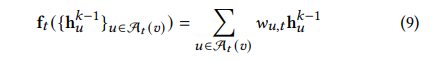
其中的
w
u
,
t
w_{u,t}
wu,t可以看作是节点v的t跳跃邻居节点的拓扑结构。所以,就可以找到GNN在GIA下的拓扑脆弱性,那就是对节点v而言可以添加一个t跳跃节点,从而可以构造
A
t
′
(
v
)
A'_t(v)
At′(v),并且可以对于
f
t
f_t
ft的输出执行一个扰动。可以看到,在添加了节点之后,当前v节点的邻居节点u的表示都会被影响到,所以扰动包括两个部分,左边一项是原始的1跳跃,2跳跃,。。。n跳跃节点的扰动,右边一项是添加进来的这部分节点带来的扰动。
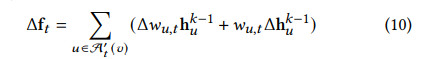
对于节点v执行1跳跃节点注入的过程如下图所示,可以看到,在添加了v节点的1跳跃节点后,可以进而影响到v节点的2跳跃,3跳跃节点,最终影响整个的v节点在下一层k+1的嵌入表示。
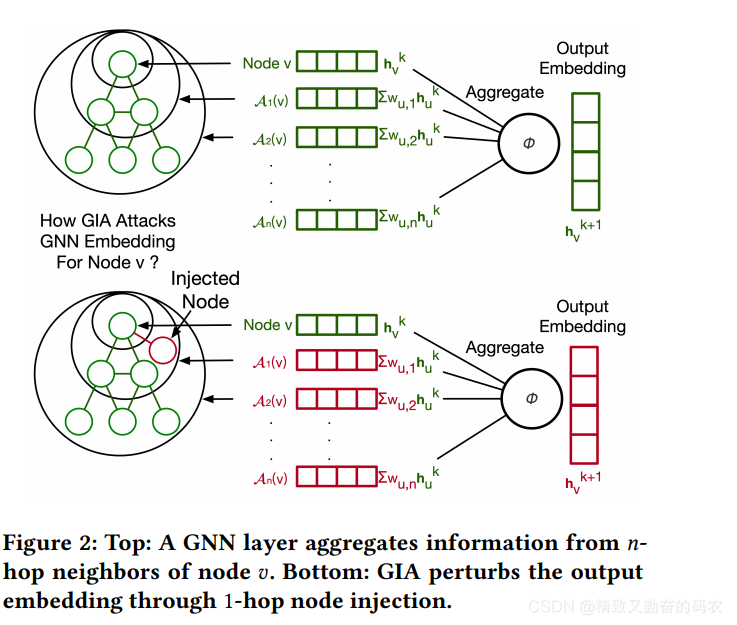
TDGIA框架
作者提出了TDGIA来对图神经网络实施有效的攻击。这个攻击方法在设计的时候是基于前面提到的GNN模型的脆弱性。TDGIA的整个过程如下图所示:
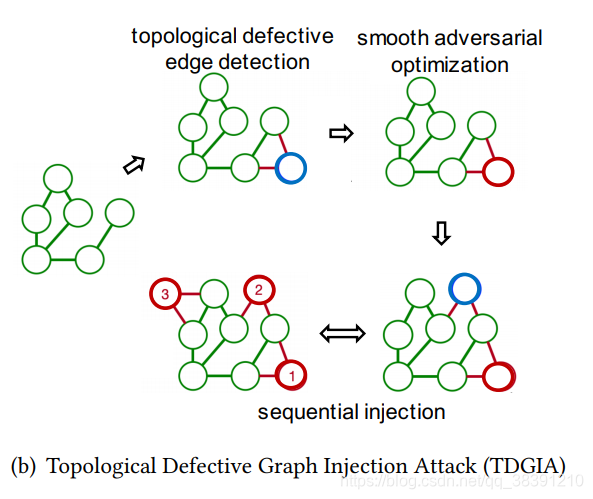
TDGIA包括两个部分:首先是选择拓扑图中的缺陷边,然后再做对抗优化。首先,通过分析原始图中的重要节点的拓扑属性,再这部分边的周边注入新的节点。其次,为了尽可能的使得节点被分类错误,作者之后再对新添加的节点做一个损失函数的优化,从而优化得到新的节点特征。
(1)拓扑图中的缺陷边的选择
由于GNN层的拓扑脆弱性,作者设计了一个选择边的策略来直接得到原始节点和新添加节点之间的缺陷边,从而对于GNN进行攻击。
对于一个节点v而言,TDGIA可以修改它的t跳跃邻居节点
A
t
(
v
)
A_t(v)
At(v)直接转变成
A
t
′
(
v
)
A_t'(v)
At′(v)。对于
A
t
(
v
)
A_t(v)
At(v)中的节点u而言,他们的特征是没有被修改的。对于新添加的节点u而言,这个节点u此时应该是在
A
t
′
(
v
)
A_t'(v)
At′(v)中但是不在
A
t
(
v
)
A_t(v)
At(v)中,他们的特征被初始化为0,此时前面的公式就可以演变成如下公式:
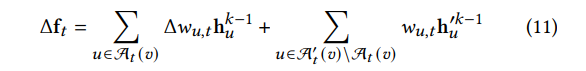
相当于上面公式的加号左边一项是原始的节点的特征,加号右边一项是新添加的节点的特征。
作者首先攻击了一个单层的GNN网络。此时应该要最大化如下公式:
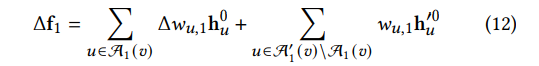
在选择边的阶段,新添加进去的节点的特征还没有被确定。所以,作者的策略是最大化新添加的节点对于当前节点v的t跳跃节点的影响,并且使得
△
f
1
\triangle f_1
△f1这个扰动尽可能的大。
首先研究当前节点v的1跳跃节点(也就是直接连接的节点),在很多的GNN中,是这样的计算形式:
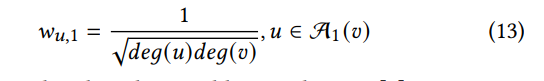
而在其他的基于平均池化的GNN(例如GraphSage)中,是如下的计算形式:
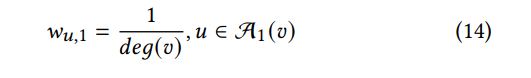
而在TDGIA中,在决定新添加的节点应该跟哪个节点进行连接时,作者使用了前面的13和14这两个权重的结合,从而可以评估节点v的拓扑脆弱性如下所示:
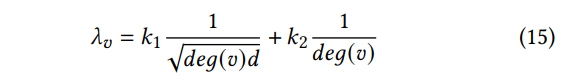
其中的deg(v)表示的是节点v的度,d表示的是新添加节点的度。
λ
v
\lambda _v
λv越大,这个节点就越容易被GIA攻击。在TDGIA中,作者将新添加的节点和已有的节点之间计算一个
λ
v
\lambda _v
λv,从中找到
λ
v
\lambda _v
λv最大对应的节点v从而将这些节点和新添加的节点之间建立连接。
作者同时也强调说,这个方法也可以应用于多层GNN中。
(2)对抗优化
上面已经确定了新添加节点的拓扑缺陷边,之后就是确定新添加节点的特征从而可以使得injected attack带来的影响更大。具体来说,给定了一个模型M后,先得到一个邻接矩阵A‘,然后再对于添加节点的特征
F
I
F_I
FI进行优化从而可以影响到最后模型的预测结果。最后,作者设计了一个光滑(smooth)的对抗优化函数。
smooth的损失函数:再对抗攻击中,可以通过训练一个模型来优化损失函数。例如,可以使用KL散度作为一个损失函数。
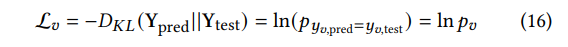
其中的
p
v
p_v
pv是模型M正确分类的概率,但是使用这个损失函数会导致梯度爆炸,因为导数是这样的:
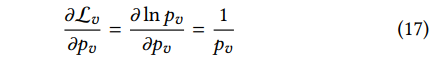
如果
p
v
p_v
pv很小甚至接近于0的话,这个导数就会趋近于无穷大,所以为了避免梯度爆炸问题,作者使用了一个光滑的损失函数如下所示:
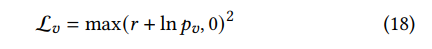
这样的话,导数就变成了如下形式:
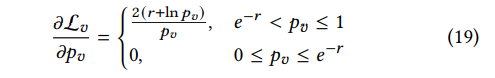
这样的话,当
p
v
p_v
pv趋近于0的时候,整个的导数也是趋近于0,所以这个优化过程就变得很稳定。损失函数的最终目的是找到一个最优的特征
F
I
F_I
FI,所以可以对于所有的目标节点都最小化公式18,损失函数就变成了如下形式:
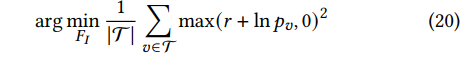
smooth的特征优化:在GIA攻击时,对于新添加节点的特征有一个限制。否则的话,防御者就可以直接通过过滤不正常的特征从而实现防御。在TDGIA中,作者使用一个Clamp函数来限制特征的范围。
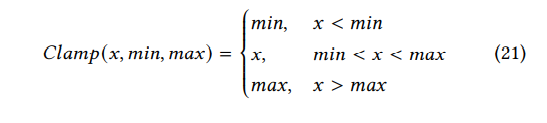
从图上可以看到,就是一个简单的两边取min最小值和max最大值的函数。
但是这个函数可能会使得最后的梯度为0.因为如果一个特征超过了max或者min就会被截断。为了使得TDGIA的优化过程更加的平滑(smooth),作者设计了一个Smoothmap函数如下所示(这里没有搞懂这个Smoothmap函数??):
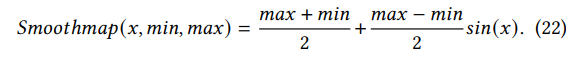
(3)TDGIA的整个攻击过程
除了选择拓扑缺陷边以及平滑对抗优化的过程之外,作者也使用了序列化攻击sequential attack,并且使用到了替代模型。
1)sequential attack
在TDGIA中,作者使用了sequential attack,并且进行节点的注入添加。在攻击的每个batch中,作者都会先添加节点,再选择缺陷边,最后优化节点的特征。就一直重复这三个步骤直到达到攻击的最大预算。
2)替代模型
在黑盒攻击时,攻击者对于被攻击模型的信息一无所知,所以这种攻击只能是替代模型的攻击。具体来说,作者首先训练得到一个替代模型M。然后作者会对TDGIA的攻击过程做优化,从而使得预测结果的准确性尽可能的低。在选择缺陷边的阶段,除了 λ v \lambda _v λv之外,作者也会使用M模型输出的概率以及替代模型预测出来的标签。作者也定义了一个缺陷分数 μ v \mu _v μv。
3)复杂性
给定一个有着T复杂度的基本模型M。在GNN中,这个复杂度T=O(ED),其中的E表示的是边的数目,D表示的是节点输入特征的维度。在边的选择阶段,作者需要对模型M实施一次inference从而得到最后的输出概率
p
v
p_v
pv,所以这部分需要花费O(T)的复杂性,计算
λ
v
\lambda _v
λv需要花费O(E)的复杂性,所以最后的整体复杂性为O(T)。在优化阶段,
△
S
\triangle _S
△S表示的是epoch的次数,B表示的是batch的数目,所以优化过程花费
△
S
B
T
\triangle _S BT
△SBT的复杂度。所以对于TDGIA的整体复杂度为
O
(
△
S
B
T
)
O(\triangle _S BT)
O(△SBT)。
总的来说,TDGIA这个攻击方法的攻击过程为:首先添加新的节点到原始图中,再学习这个节点的特征。整个的算法流程如下:

实验过程
(1)基本实验设置
1)数据集
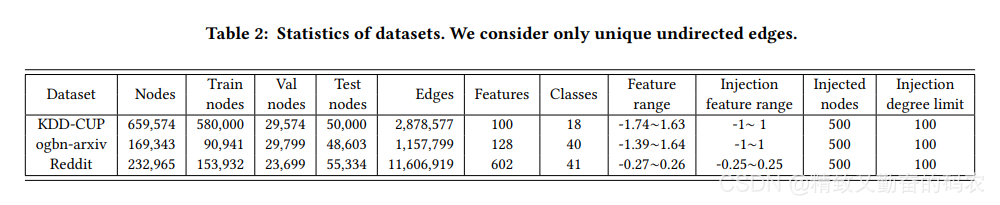
作者在3个大规模的公开数据集上做了实验,包括这几个数据集:KDD-CUP数据集,这是一个大规模的引文数据集,被应用在KDD-CUP2020的图对抗攻击和防御比赛中。ogbn-arxiv数据集,这是一个benchmark的引文数据集。Reddit,这是一个很出名的在线论坛数据集。下面这张表格是这些数据集的一些信息。
2)约束条件
对于每一个数据集而言,都会约束一下新添加节点的数目b=500,以及约束一下度的限制最大为d=100.还有特征的范围也会约束一下。在KDD-CUP数据集中,很多的防御方法都是直接过滤节点的度大于100的所有节点。所以本文实验中是直接将这个数值设置成88。
3)评估指标
为了更好的评估GIA方法,作者考虑使用performance reduction和transfer-ability作为两个评价指标。作者的评价指标是基于在KDD-CUP数据集上的weighted average accuracy。这个指标为每一个防御模型都添加一个权重,例如,越鲁棒的防御模型可以获得越高的权重。这样的话,攻击的时候就可以专注于对所有防御模型的迁移性,从而可以设计出更加通用的攻击方案。(这里很有意思啊,直接对防御模型添加权重。)除了weighted average accuracy之外,作者还得到了对于所有防御模型的平均准确性以及准确性top3的防御模型。三个评价指标如下所示:
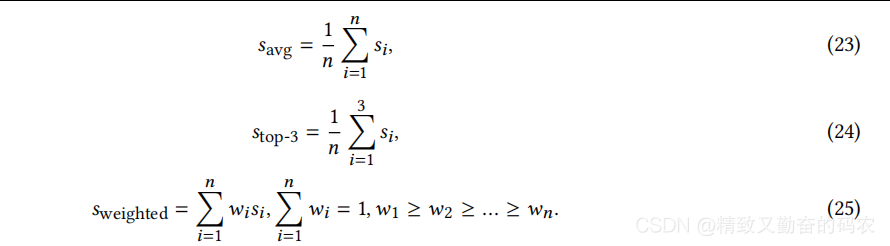 其中的s1到sn表示的是n个不同的防御模型,并且准确性分数是逐渐递减的。对于KDD-CUP数据集而言,作者使用了权重的这个指标也就是公式25。对于ogbn-arxiv和Reddit
其中的s1到sn表示的是n个不同的防御模型,并且准确性分数是逐渐递减的。对于KDD-CUP数据集而言,作者使用了权重的这个指标也就是公式25。对于ogbn-arxiv和Reddit
相关论文
(1)图对抗攻击的综述论文
Adversarial Attacks and Defenses on Graphs














 1471
1471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









