










序
最近在复习hadoop知识,自从开始干大数据,已经两年了。
集群现在都有点生疏了,今天来回顾一下。cdh版本的后面给出。先来个hadoop单节点玩玩。
hadoop默认是单节点模式,因此不需多余的配置。
虚拟机已经搭建完成了,有云服务当然更好(我之前用的阿里的还不错)。
没有安装虚拟机的同学请参照这篇(虚拟机版本:centos6.10)
vmware虚拟机安装教程-边搭边写_我要用代码向我喜欢的女孩表白的博客-CSDN博客
下面首先准备的是hadoop2.7
百度网盘地址
链接:https://pan.baidu.com/s/19hMOvfFFFYh8ZjsOGK_VyQ
提取码:oi9v
先给虚拟机装个jdk---太简单了,这个自己弄。(hadoop是java写的所以要依赖jdk环境)
我的jdk也装到hadoop目录下了
解压
首先咱们创建个目录
mkdir /hadoop使用ftp工具上传 hadoop2.7.tar到/hadoop文件夹下

解压文件,解压到/hadoop目录下
tar -zxvf /hadoop/hadoop-2.7.2.tar.gz -c /hadoop
解压完成,进入hadoop目录并且查看是否存在
cd /hadoop/
ll
配置环境变量
进入解压后的hadoop2.7
cd /hadoop/hadoop-2.7.2
pwd
咱们已经看到,咱们的解压目录是 /hadoop/hadoop-2.7.2,记住下一步加入需要 HADOOP_HOME=你的解压目录
接下来, 注入环境变量
vi /etc/profile在最下面加入
export HADOOP_HOME=/hadoop/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin

然后保存退出(记住,如果是在PATH后面新增一定要加个:)
更新环境变量
source /etc/profile咱们看看配成功没
hadoop version
单节点最最基本完成。(现在还不能用)
接下来配置
cd /hadoop/hadoop-2.7.2/etc/hadoop/
ls令人眼花缭乱的场景出现了,咱们帮你选一下,接下来要配置的内容

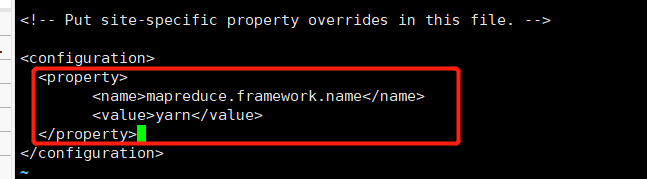
mapred-site.xml
首先咱要把这个mapred-site.xml.template复活
cp mapred-site.xml.template mapred-site.xmlvi mapred-site.xml <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
hdfs.sitem.xml
mkdir -p /home/hadoop/hadoop/tmp/dfs/name
mkdir -p /home/hadoop/hadoop/tmp/dfs/data
vi hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9001</value>
</property>
</configuration>
core-site.xml
这些目录一定要创建好
mkdir -p /home/hadoop/hadoop/tmp
vi core-site.xml<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
</property>
</configuration>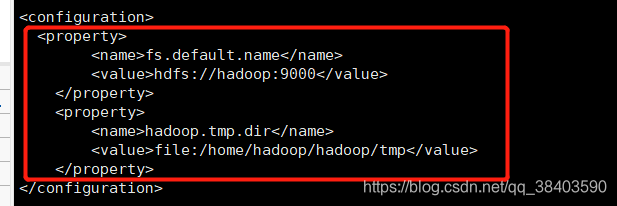
其他2个sh文件
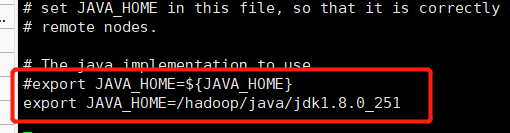
修改hadoop-env.sh(如果不声明JAVA_HOME,在启动时会出现找不到JAVA_HOME 错误)
vi hadoop-env.shexport JAVA_HOME=${JAVA_HOME}
改为
export JAVA_HOME=/hadoop/java/jdk1.8.0_251
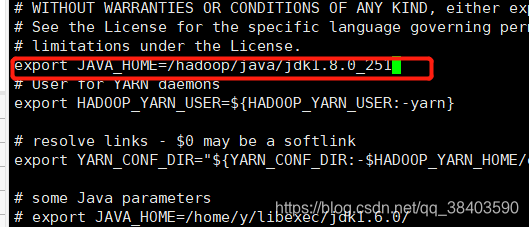
修改yarn-env.sh(如果不声明JAVA_HOME,在启动时会出现找不到JAVA_HOME 错误)vi yarn-env.sh
在脚本前面添加
export JAVA_HOME=/hadoop/java/jdk1.8.0_251
启动dfs
cd /hadoop/hadoop-2.7.2
sbin/start-dfs.sh
报错,他说找不到ssh,咱们可能没有安装它。安装一下
yum install openssh-clients
安装完成
再次尝试
sbin/start-dfs.sh报错(3.0的错误,这是新加的内容,我尝试安装3.0)
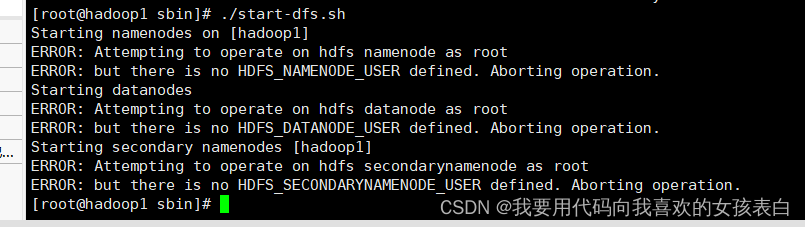
在/etc/profile加入这个即可
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root更新一下source /etc/profile
报错
看日志java.io.IOException: NameNode is not formatted.

格式化namenode
hadoop namenode -format
如果无法启动请保持uid
hadoop3,成功
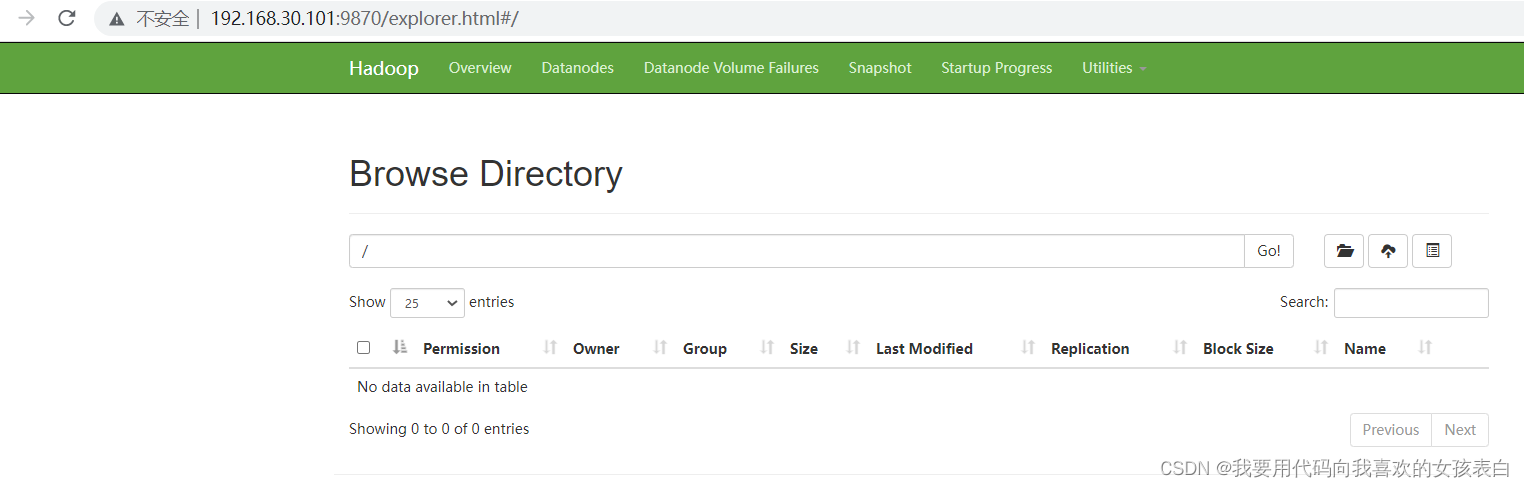
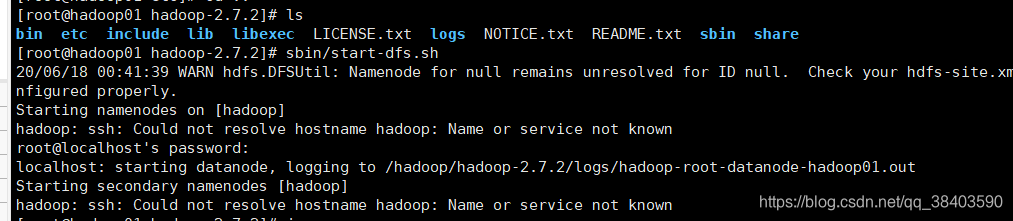
他说名字不一样,我们查看一下咱们的名字
![]()
看看core-site.xml 文件
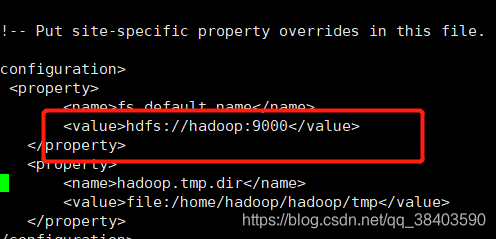
hadoop01和hadoop不一样
改成hadoop01
还是报错,修改host,还是错误
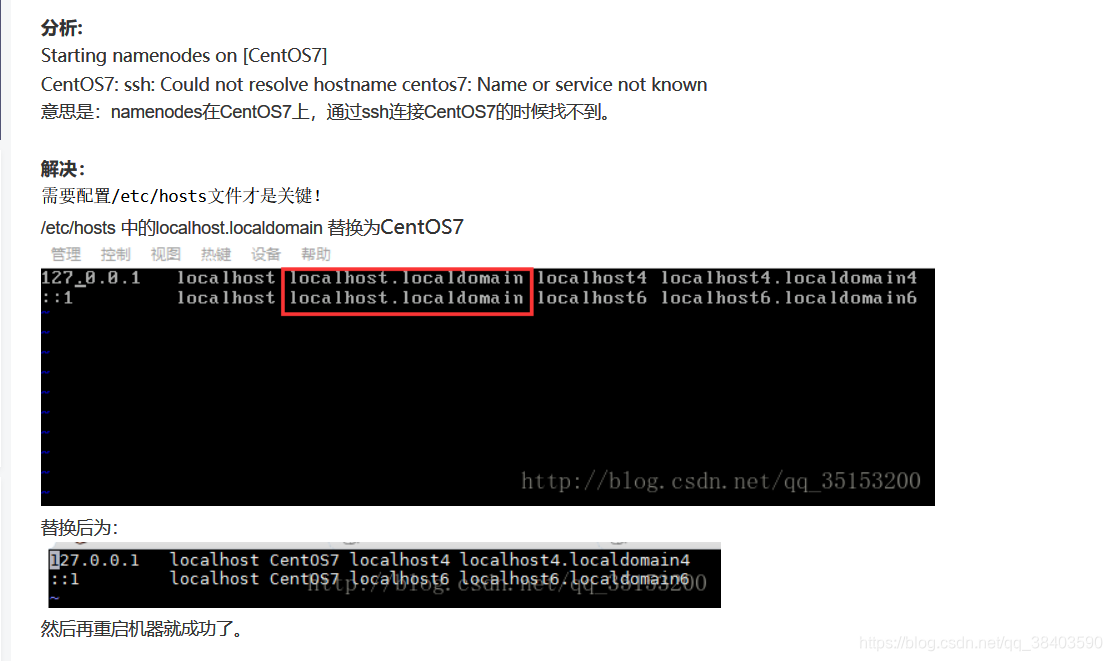
重启,还是错误

尝试关闭防火墙
service iptables stop cat /etc/hosts
添加hosts为主机名字
修改失败,尝试修改其它2个文件

成功,hdfs-site.xml也要设置成与你本机Ip一样就行.hadoop01
nice~
咱们试试50070,完美
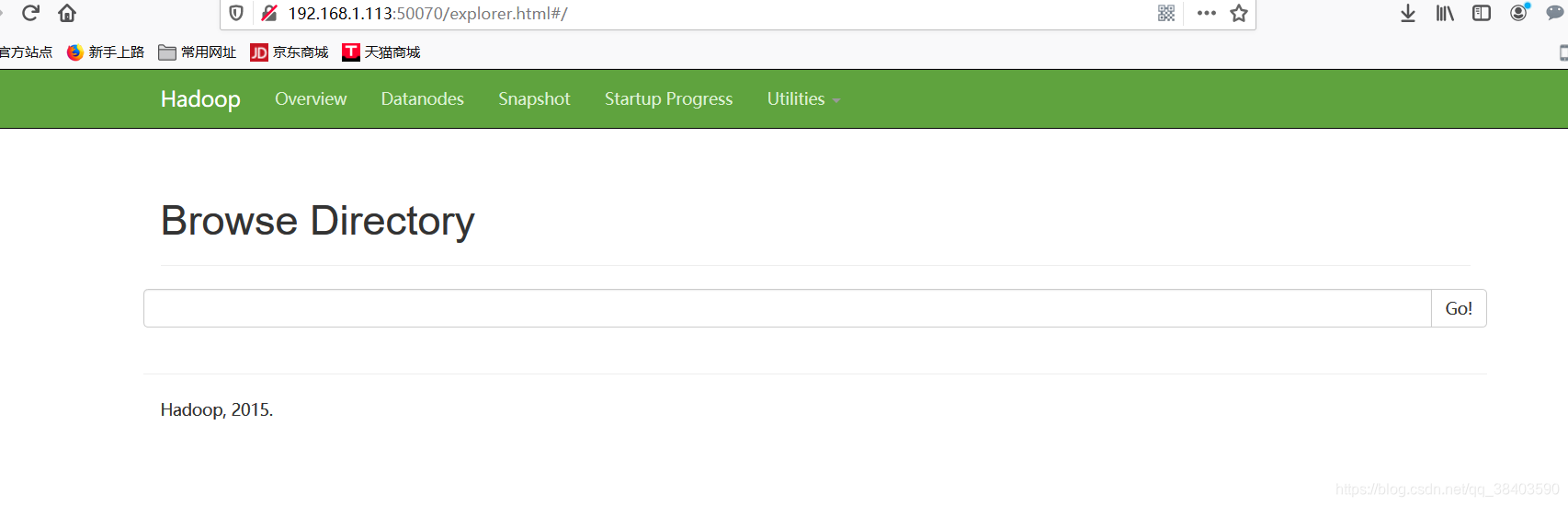
集群模式
基于上面的单节点部署后
记得要先配置免密登录,集群之间心跳是通过ssh(请参考我的另一篇博文的免密登录部分)
cdh集群搭建(6.3)_我要用代码向我喜欢的女孩表白的博客-CSDN博客_cdh集群规划
主机点配置yarn.site
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定 MR shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ResourceManager addr-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_CONNON_HONE,HADOOP_HDFS_HONE,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADO0P_MAPRED_HOME</value>
</property>
</configuration>修改works(里面写好,你配置的主机名,或者ip)
hadoop1
hadoop2
hadoop3
分发到其他节点
ssync(分发脚本) /etc/profile
ssync(分发脚本) /software/hadoop3
在主节点,sbin目录,关闭hdfs
./stop-dfs.sh
然后在启动
./start-dfs.sh
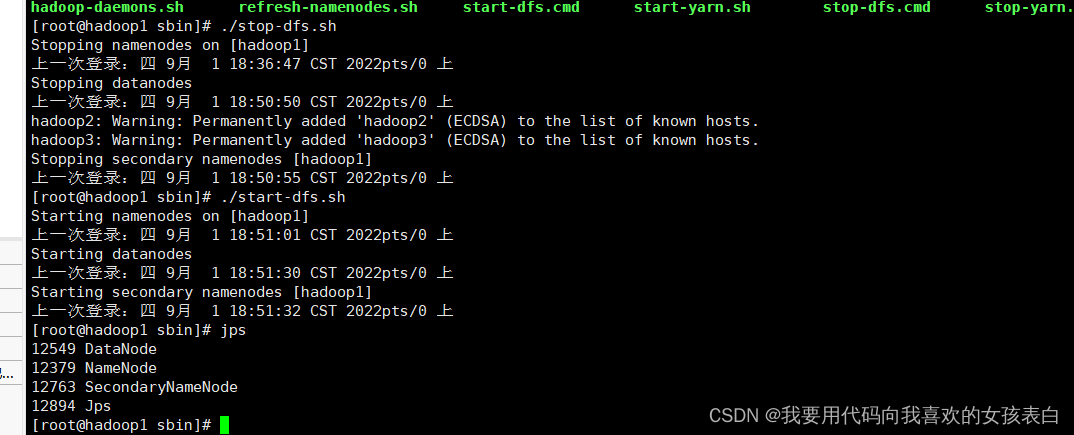
其他节点会自动启动
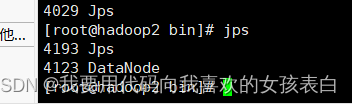
启动yarn
./start-yarn.sh

其他节点会自动其他nodemanager

完成!















 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









