










最近看到一篇关于poi的论文,把poi各个类别通过邻接关系利用Word-embedding训练成了词向量,这样原本属于不同大类下的子类但是功能很相近的类别就在词向量空间里显得比较近,更符合实际情况。相比于之前的分开看各种poi类别比例,这样可以更好地表达出城市内的poi配置情况。
论文提要
Liu K, Yin L, Lu F, et al. Visualizing and exploring POI configurations of urban regions on POI-type semantic space[J]. Cities, 2020, 99: 102610.
主要技术路线如下:
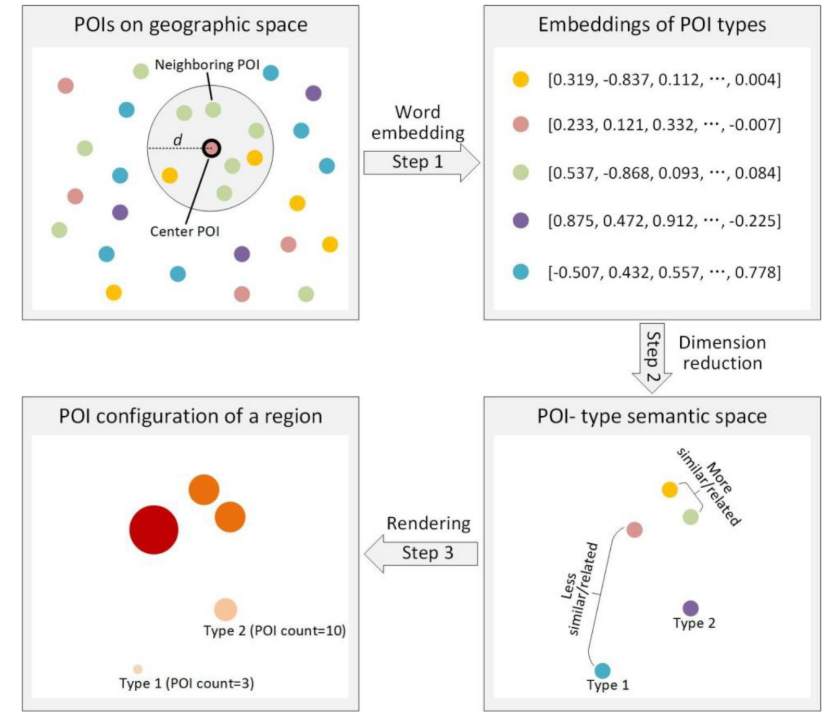
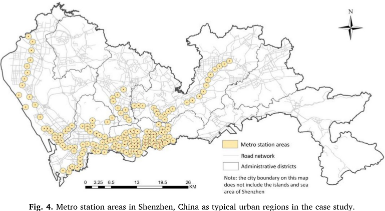
- 选择深圳市地铁站700m范围内poi作为研究数据
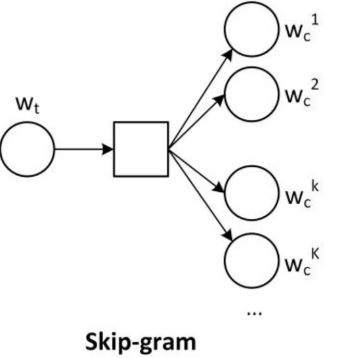
- 参考Skip-gram模型(Word-embedding)的一种,把每个poi类别当做输入(one-hot编码处理),并给定一个阈值范围(500m),统计范围内的所有poi比例,作为输出
- 根据各类别的词向量进行分析
他们还做了一个下面这样的交互页面,http://hpcc.siat.ac.cn/liuk/POI_configuration_en/index.html
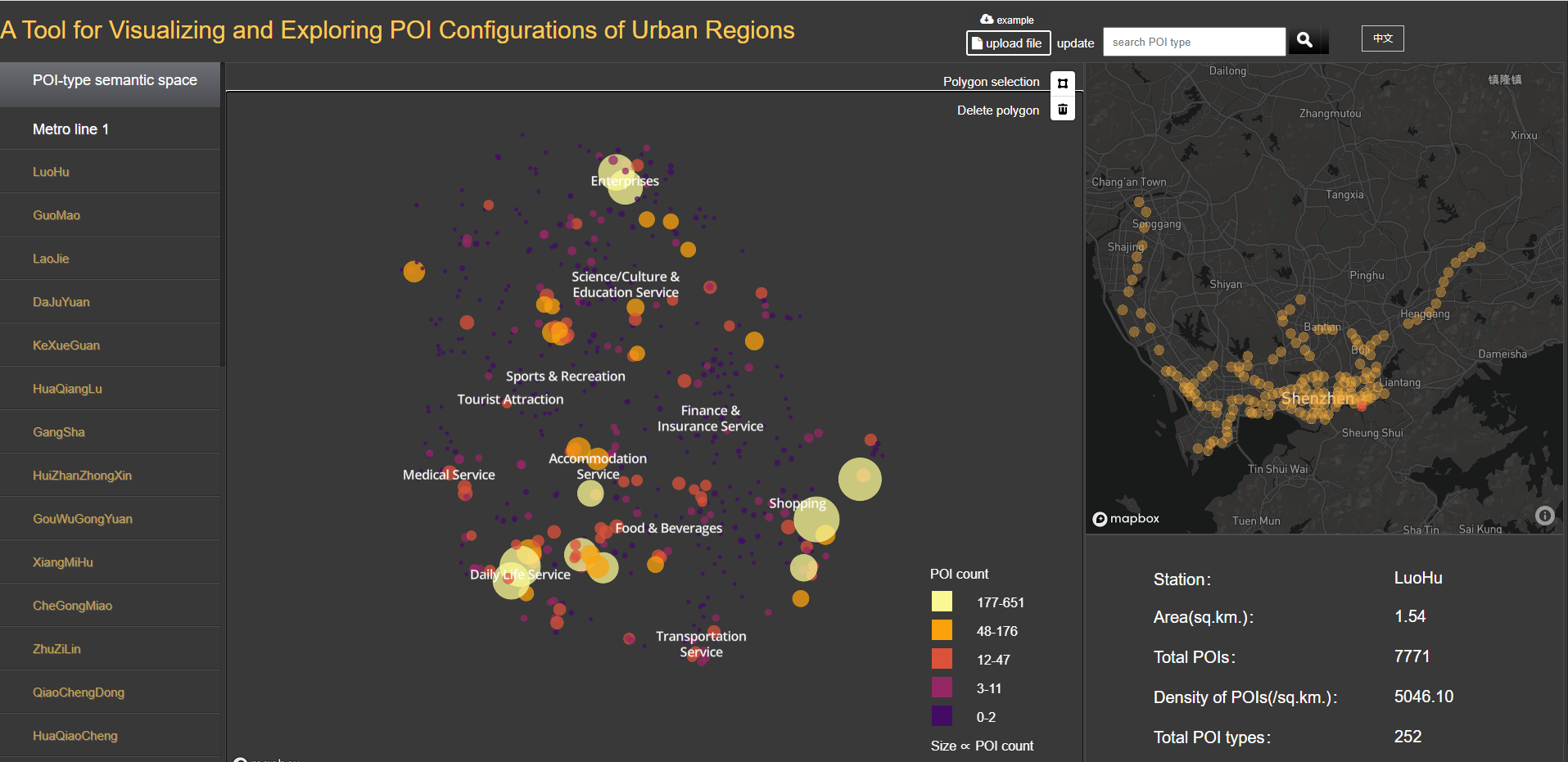
简单复现
ok,介绍就到这里,我们拿上海的poi数据简单复现一下
- step1 筛选上海地铁站700m内poi数据
这里是通过geopandas对每个地铁站建立缓冲区,然后利用sjoin与各个poi点做相交,判断是否在缓冲区内,这里注意做缓冲区需要先把地理坐标系这种转换为平面坐标系,做完缓冲区我们再换回去
#读取poi数据
data=pd.read_csv(r"E:\data\上海市_201812_WGS84_poi_type.csv")
data['geometry']=data.apply(lambda x: geometry.Point(x.ln,x.lat),axis=1)
data=geopandas.GeoDataFrame(data)
data.crs = pyproj.CRS.from_user_input('EPSG:4326')
#读取上海地铁站数据
urban=pd.read_csv("E:/data/shanghai_urban.csv")
urban['geometry']=urban.apply(lambda x: geometry.Point(x.lon,x.lat),axis=1)
urban=geopandas.GeoDataFrame(urban)
urban.crs = pyproj.CRS.from_user_input('EPSG:4326')
#设置缓冲区范围
distance=700
urban=urban.to_crs(crs="EPSG:2385")
urban['geometry']=urban.buffer(distance)
urban.set_geometry('geometry',inplace=True)
#设置完缓冲区后再换回来
urban=urban.to_crs(crs="EPSG:4326")
#判断是否与地铁接驳范围相交
result=geopandas.sjoin(data,urban,how="left", op='intersects')
result.to_csv('result.csv')
result.set_geometry('geometry',inplace=True)
##保存接驳距离内poi数据
urban_in=result[pd.notna(result['name_right'])]
urban_in.to_csv(r'E:\data\shanghai_poi_within_urban.csv')
这里统计下来,上海poi在轨道站700m范围内的占61.85%
- step2 筛选每个poi点周围500m内的poi数据,统计比例
此时数据里有141类poi了,这里我们应该对每一个poi点都做500m的缓冲区,找到落在该缓冲区内的141个子类的比例
这一步的话相当于是做99万+的缓冲区实在搞不动,要么多做几次很费时间,要么做一次又没内存,反正只是为了试验一下,就把每一类抽了1%,最后得到9962条数据
data=pd.read_csv(r"E:\data\shanghai_poi_within_urban.csv")
type_list=data['type_id'].unique().tolist()
def sample_data(type_id):
con=data['type_id']==type_id
tempdata=data.loc[con,:].copy()
outdata=tempdata.sample(frac=0.01,random_state=1)
return outdata
result_list=[]
for i in range(0,len(type_list)):
result_list.append(sample_data(type_list[i]))
result=pd.concat(result_list,axis=0)
result.to_csv(r'shanghai_poi_within_urban_sample.csv')
接着对经过抽样的数据中每一个poi点都做500m的缓冲区,这里做缓冲区同step 1,不再赘述
得到下图结果
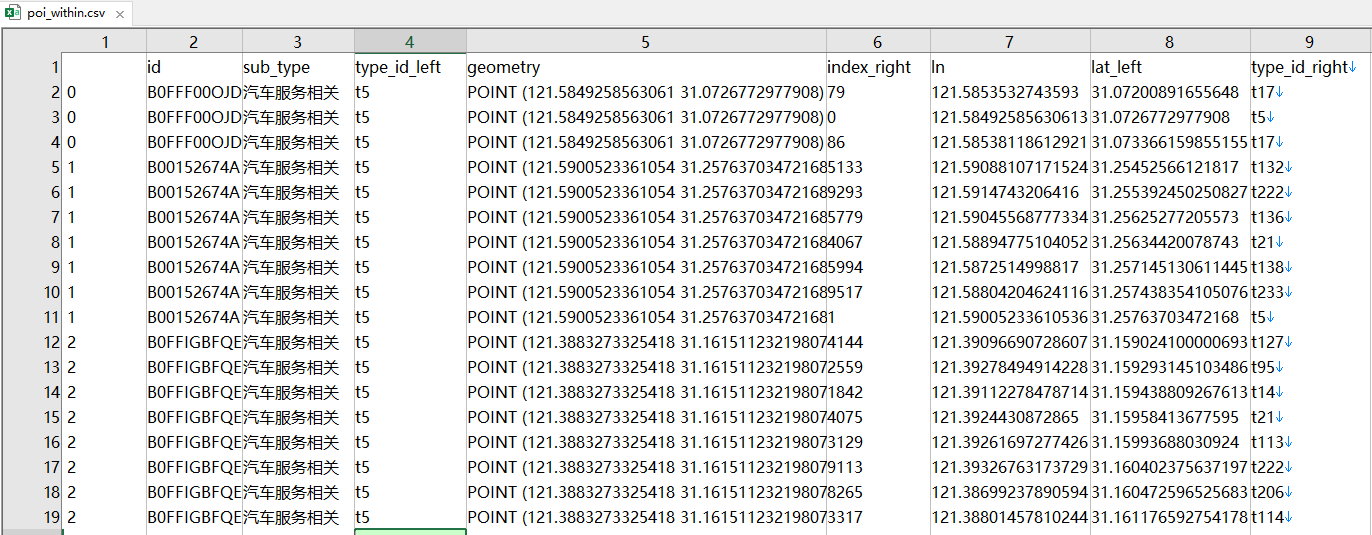
然后统计不同类别的数目
table=pd.pivot_table(data=data,index=['id'],values=['index_right'],columns=['type_id_right'],aggfunc='count')
table=table.reset_index()
table=table.fillna(value=0)
转换成比例
data=pd.read_excel(r'C:\users\fff507\Desktop\data_poi_processed.xlsx')
data_value=data.iloc[:,1:].values
df1=pd.DataFrame(data_value)
df2=df1.sum(axis=1)# 按行相加
new_data=df1.div(df2, axis='rows')
- step3 利用skip-gram训练,得到各类别对应的词向量
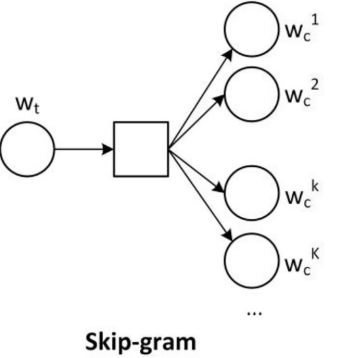
把中心词的onehot编码当做输入,上下文里的词出现的概率做输出,以此来进行训练,其实真正想要的是中间的隐藏层权重,也就是我们想要的对应于每个词的词向量。
我们这个背景里,中心词类似于每一个poi,上下文类似于缓冲区内的poi
基本原理其实也很简单,核心就是两个矩阵,看一下下面我画的图,就是W1,W2的问题,他们也是我们最终想要的
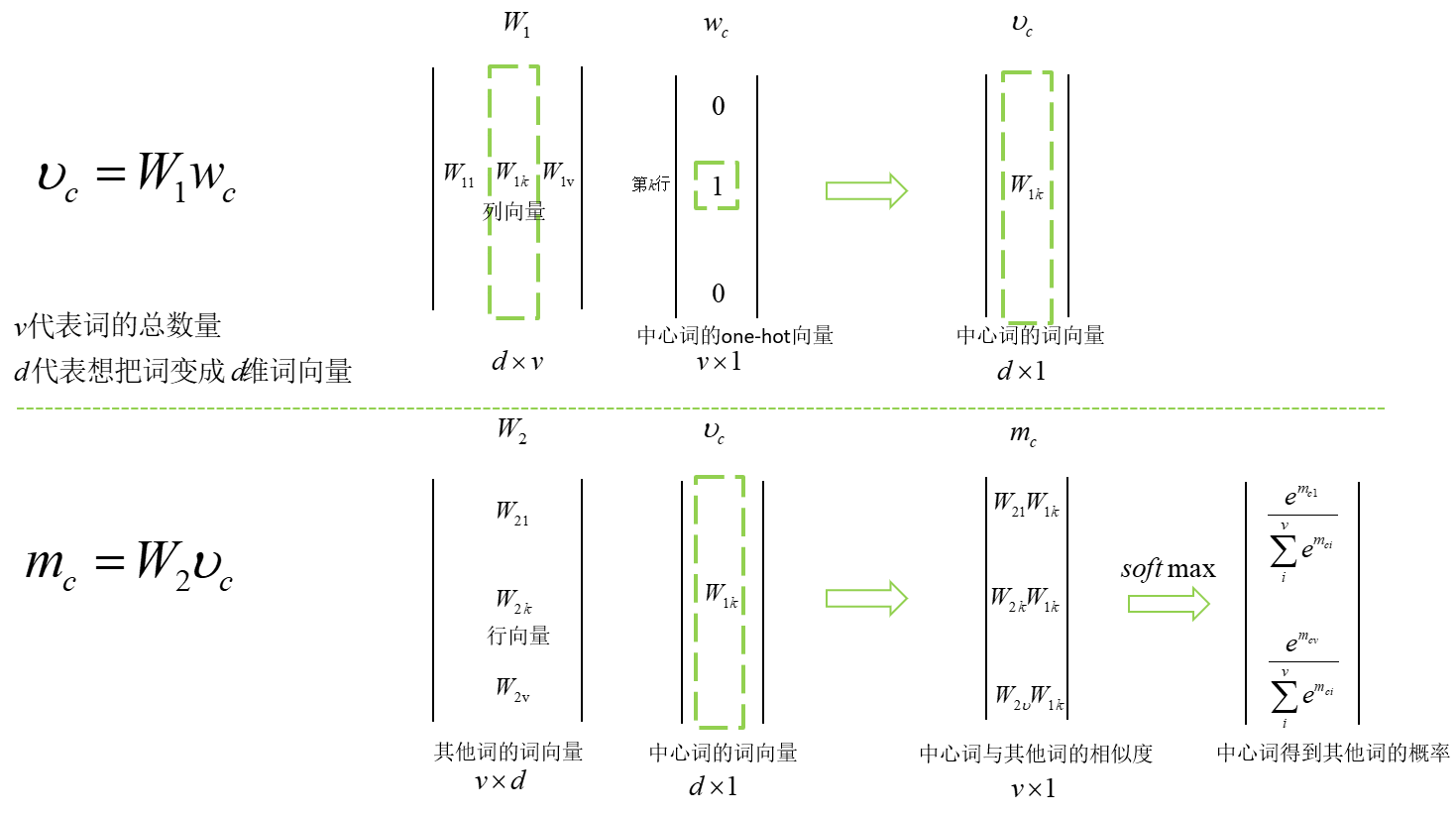
| 小周亲手画的 |
|---|
那么输入就是某个poi的one-hot编码,输出就是对应于141类的概率
但其实我们想要的是中间隐藏层的权重,W1,W2
我直接按照上图原理搞了个最简单的
def weight_variable(shape,name_w):
initial = tf.truncated_normal(shape, stddev=0.1,name=name_w)
return tf.Variable(initial)
X = tf.placeholder(tf.float32, [None, input_size],name='x')
W1 = weight_variable([input_size,embedding_size],name_w='W1')
v_c= tf.matmul(X, W1)
W2= weight_variable([embedding_size,input_size],name_w='W2')
M=tf.matmul(v_c, W2)
Y = tf.placeholder(tf.float32, [None,output_size],name='y')
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=M, labels=Y))
train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
correct_prediction = tf.equal(tf.argmax(M, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
saver = tf.train.Saver(tf.global_variables())
最后测试集准确率在75.78%,141类也不算很差吧
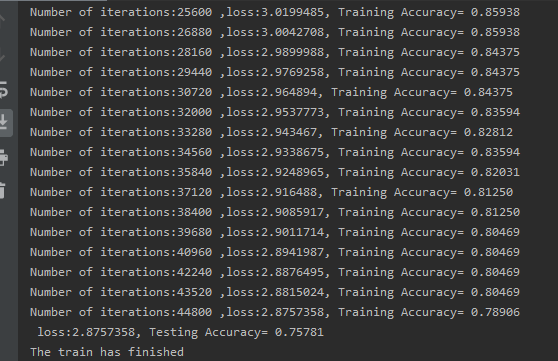
获取W1矩阵,也即词向量矩阵(141*50)
这个我看了有人说W1和W2都可以本质是一样的,也有人说应该取W1,官方取得是W1,我们这里也取W1好了
from tensorflow.python import pywrap_tensorflow
#首先,使用tensorflow自带的python打包库读取模型
model_reader = pywrap_tensorflow.NewCheckpointReader(r"model_emb/model.ckpt")
#然后,使reader变换成类似于dict形式的数据
var_dict = model_reader.get_variable_to_shape_map()
W1=model_reader.get_tensor('W1')#141*50
- step4 降维后做一些可视化分析
# 降维到二维
pca = PCA(n_components=2)
pca.fit(W)
# 输出特征值
print(pca.explained_variance_)
#输出特征向量
print(pca.components_)
# 降维后的数据
W_new = pca.transform(W)
result=pd.DataFrame(W_new)
result.to_excel('poi_2d_wight.xlsx',index=False)
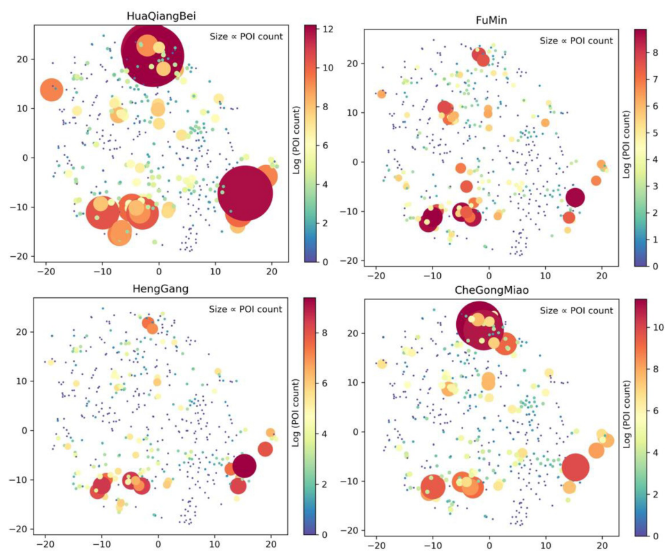
由于内存限制本文只是实验性的拿差不多1w(1%)试验,难免有偏差结果看起来有些应该在一起的没有在一起(比如公交站和地铁站),不过看这个论文里的结果挺好的
ok,我们挑几个地铁站来看看poi配置区别
那就挑黄渡理工,同济,交大,复旦吧

| 周边poi配置 |
|---|
下面这个当图例
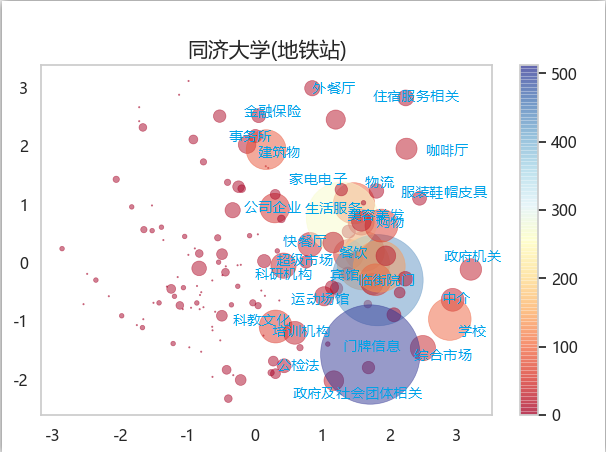
| 我是图例 |
|---|
黄渡理工独树一帜,而同济和交大地铁站周边分布最为相似,都有较多的生活服务,科教文化,培训结构,复旦大学地铁站是18号线在建,所以相对偏少,但是在事务所那里复旦大学地铁站周围高于其他。
















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











