







文章概述:
将excel中的数据存储到以该excel名称的模型中。
做法概述:
1、自定义一个注解标记资源所对应的模型。
2、借助spring自动扫描这么被标记的bean。
3、根据bean的名称找到默认目录下的资源文件(excel文件)。
4、通过java的反射机制将资源文件中的数据存储到对应的模型中。
具体做法如下:
一、扫描@Resource标记的类。
我模拟spring中componentScan和Component的做法 创建自己的Resource和ResourceScan注解
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Resource {
boolean registerBean() default false;
}
import java.lang.annotation.Retention;
import java.lang.annotation.Target;
import org.springframework.context.annotation.ComponentScan.Filter;
import org.springframework.context.annotation.Import;
import java.lang.annotation.ElementType;
import java.lang.annotation.RetentionPolicy;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Import(ResourceRegistrar.class)
public @interface ReasourceScan {
/**
* @return
*/
String[] value() default {};
/**
* 扫描包
*
* @return
*/
String[] basePackages() default {};
/**
* 扫描的基类
*
* @return
*/
Class<?>[] basePackageClasses() default {};
/**
* 包含过滤器
*
* @return
*/
Filter[] includeFilters() default {};
/**
* 排斥过滤器
*
* @return
*/
Filter[] excludeFilters() default {};
}ResourceScan注解具体怎么扫描是根据 在其注解上import的类ResourceRegistrar来实现的。
public class ResourceRegistrar implements ImportBeanDefinitionRegistrar ImportBeanDefinitionRegistrar:手动注册bean到容器中 ,实现类通过重新父类的registerBeanDefinitions方法来实现自定义注册
/**
* AnnotationMetadata:当前类的注解信息
* BeanDefinitionRegistry:BeanDefinition注册类;
* 把所有需要添加到容器中的bean;调用
* BeanDefinitionRegistry.registerBeanDefinition手工注册进来
*/
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
AnnotationAttributes annAttr = AnnotationAttributes.fromMap(importingClassMetadata.getAnnotationAttributes(ReasourceScan.class.getName()));
//是否在ResourceScan注解上设置扫描地址,如果没有则扫描该注解标记类所在的的包路径下的类
String[] basePackages = annAttr.getStringArray("value");
if (ObjectUtils.isEmpty(basePackages)) {
basePackages = annAttr.getStringArray("basePackages");
}
if (ObjectUtils.isEmpty(basePackages)) {
basePackages = getPackagesFromClasses(annAttr.getClassArray("basePackageClasses"));
}
if (ObjectUtils.isEmpty(basePackages)) {
basePackages = new String[] {ClassUtils.getPackageName(importingClassMetadata.getClassName())};
}
List<TypeFilter> includeFilters = extractTypeFilters(annAttr.getAnnotationArray("includeFilters"));
//ReasourceTypeFilter 自定义的过滤器 来筛选符合要求的bean
includeFilters.add(new ReasourceTypeFilter());
List<TypeFilter> excludeFilters = extractTypeFilters(annAttr.getAnnotationArray("excludeFilters"));
List<Class<?>> candidates = scanPackages(basePackages, includeFilters, excludeFilters);
if (candidates.isEmpty()) {
LOGGER.info("扫描指定HSF基础包[{}]时未发现复合条件的基础类", basePackages.toString());
return;
}
//注册后处理器,为对象注入环境配置信息
registerHsfBeanPostProcessor(registry);
//注册bean
registerBeanDefinitions(candidates, registry);
}ReasourceTypeFilter 过滤器如下:
public class ReasourceTypeFilter extends AbstractClassTestingTypeFilter {
private static final Logger LOGGER = LoggerFactory.getLogger(ReasourceTypeFilter.class);
@Override
protected boolean match(ClassMetadata metadata) {
Class<?> clazz = transformToClass(metadata.getClassName());
if (clazz == null || !clazz.isAnnotationPresent(Resource.class)) {
return false;
}
//匹配被Resource注解标记的类
Resource Resource = clazz.getAnnotation(Resource.class);
if (Resource.registerBean() && isAnnotatedBySpring(clazz)) {
throw new IllegalStateException("类{" + clazz.getName() + "}已经标识了Spring组件注解,不能再指定[registerBean = true]");
}
return !metadata.isAbstract() && !clazz.isInterface() && !clazz.isAnnotation() && !clazz.isEnum()
&& !clazz.isMemberClass() && !clazz.getName().contains("$");
}
/**
* @param className
* @return
*/
private Class<?> transformToClass(String className) {
Class<?> clazz = null;
try {
clazz = ClassUtils.forName(className, this.getClass().getClassLoader());
} catch (ClassNotFoundException e) {
LOGGER.info("未找到指定基础类{}", className);
}
return clazz;
}
/**
* @param clazz
* @return
*/
private boolean isAnnotatedBySpring(Class<?> clazz) {
return clazz.isAnnotationPresent(Component.class) || clazz.isAnnotationPresent(Configuration.class)
|| clazz.isAnnotationPresent(Service.class) || clazz.isAnnotationPresent(Repository.class)
|| clazz.isAnnotationPresent(Controller.class);
}
}
包扫描如下:
private List<Class<?>> scanPackages(String[] basePackages, List<TypeFilter> includeFilters, List<TypeFilter> excludeFilters) {
List<Class<?>> candidates = new ArrayList<Class<?>>();
for (String pkg : basePackages) {
try {
candidates.addAll(findCandidateClasses(pkg, includeFilters, excludeFilters));
} catch (IOException e) {
LOGGER.error("扫描指定基础包[{}]时出现异常", pkg);
continue;
}
}
return candidates;
}findCandidateClasses 如下:
private List<Class<?>> findCandidateClasses(String basePackage, List<TypeFilter> includeFilters, List<TypeFilter> excludeFilters) throws IOException {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("开始扫描指定包{}下的所有类" + basePackage);
}
List<Class<?>> candidates = new ArrayList<Class<?>>();
//ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX = "classpath*:";
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + replaceDotByDelimiter(basePackage) + '/' + RESOURCE_PATTERN;
ResourceLoader resourceLoader = new DefaultResourceLoader();
MetadataReaderFactory readerFactory = new SimpleMetadataReaderFactory(resourceLoader);
org.springframework.core.io.Resource[] resources = (org.springframework.core.io.Resource[]) ResourcePatternUtils.getResourcePatternResolver(resourceLoader).getResources(packageSearchPath);
for (org.springframework.core.io.Resource resource : resources) {
MetadataReader reader = readerFactory.getMetadataReader(resource);
//根据条件筛选bean
if (isCandidateResource(reader, readerFactory, includeFilters, excludeFilters)) {
Class<?> candidateClass = transform(reader.getClassMetadata().getClassName());
if (candidateClass != null) {
candidates.add(candidateClass);
LOGGER.debug("扫描到符合要求基础类:{}" + candidateClass.getName());
}
}
}
return candidates;
}isCandidateResource 匹配方法如下,最终调用之前向exclude或include中传入的filter来进行判断。
protected boolean isCandidateResource(MetadataReader reader, MetadataReaderFactory readerFactory, List<TypeFilter> includeFilters,
List<TypeFilter> excludeFilters) throws IOException {
//满足任意exclude中的条件即为不匹配
for (TypeFilter tf : excludeFilters) {
if (tf.match(reader, readerFactory)) {
return false;
}
}
//满足任意include中的条件即为匹配
for (TypeFilter tf : includeFilters) {
if (tf.match(reader, readerFactory)) {
return true;
}
}
return false;
}二、将找到的被标记的bean注册到spring容器中。
这里我们设计的后处理实现类是实现了BeanPostProcessor的功能而不是beanFactoryPostProcessor。下面的链接是具体的原因
BeanFactoryPostProcessor与beanPostProcessor
我在尝试时确实出现了链接中所说的陷阱一,
@Component
//BeanDefinitionRegistryPostProcessor 是BeanFactoryPostProcessor 子类
class AnnotationScannerConfigurer implements BeanDefinitionRegistryPostProcessor {
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry beanDefinitionRegistry) {
}
public void postProcessBeanFactory(ConfigurableListableBeanFactory postProcessBeanFactory) throws BeansException {
System.out.println("- = - = ");
Map<String, Object> map=postProcessBeanFactory.getBeansWithAnnotation(Resource.class);
for (String key : map.keySet()) {
System.out.println("beanName= "+ key );
}
}
}//InstantiationAwareBeanPostProcessorAdapter 是BeanPostProcessor的子类
public class ResourceBeanPostProcessor extends InstantiationAwareBeanPostProcessorAdapter implements InitializingBean, BeanFactoryAware {
private static final String suffix =".xls";
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("before" + bean.getClass().isAnnotationPresent(Resource.class));
if(bean.getClass().isAnnotationPresent(Resource.class)) {
System.out.println("bean :" + bean + " beanName :" +beanName);
List<Object> excelReader = excelReader(bean);
for (Object object : excelReader) {
if(object instanceof CommonReasource) {
System.out.println((CommonReasource) object);
}
}
}
return beanName;
}同时实现两个后查看结果发现 前者可以找到被标记的bean但是后者却找不到了。所以我这里实现BeanPostProcessor来完成bean的处理。
三、excel文件解析以及数据传入
excelReader 是进行excel文件的解析的过程,具体如下:
public List<Object> excelReader(Object bean) {
List<Object> beanList = new ArrayList<Object>();
try {
InputStream is = ClassLoader.getSystemResourceAsStream(bean.getClass().getSimpleName() + suffix);
Workbook wb = new HSSFWorkbook(is);
Sheet sheet = wb.getSheetAt(0);
int rowNum = sheet.getPhysicalNumberOfRows();
System.out.println("( 行 :" + rowNum+ ")");
if(rowNum <= 2) {
return beanList;
}
Row clientRow = sheet.getRow(0);
if(!"Client".equals((String)getCellFormatValue(clientRow.getCell(0)))) {
return null;
}
int colNum = clientRow.getPhysicalNumberOfCells();
System.out.println("( 列 :" + colNum+ ")");
//todo 将每一行数据放入到model中
//获取属性名称
ParmTypeOf[] clientArr = new ParmTypeOf[colNum];
for(int i = 1; i < colNum; i++) {
ParmTypeOf typeOf = new ParmTypeOf();
Cell cell = clientRow.getCell(i);
typeOf.setName((String)getCellFormatValue(cell));
clientArr[i] = typeOf;
}
//获取属性类型
Row typeRow = sheet.getRow(1);
if(!"Type".equals((String)getCellFormatValue(typeRow.getCell(0)))) {
return null;
}
for(int i = 1; i < colNum; i++) {
ParmTypeOf typeOf = clientArr[i];
Cell cell = typeRow.getCell(i);
typeOf.setType((String)getCellFormatValue(cell));
}
//获取“Start”标记的数据起始位置
int startIndex = 0;
for(int i =2; i < rowNum; i++) {
Row tempRow = sheet.getRow(i);
if("Start".equals((String)getCellFormatValue(tempRow.getCell(0)))) {
startIndex = i;
break;
}
}
if(startIndex == 0) {
return null;
}
//将每一行数据保存到model
for(int i = startIndex; i < rowNum; i++) {
//每次创建新的model
Object tempObject = bean.getClass().newInstance();
Row tempRow = sheet.getRow(i);
// 如果该行第一个单元格是End 则表示是最后一个数据
if("End".equals((String)getCellFormatValue(tempRow.getCell(0)))) {
i= rowNum;
}
for(int j = 1; j < colNum; j++) {
try {
//如果表中该字段不是model中的字段 即object中不存在该字段则抛异常 NoSuchFieldException,进行表中下一个字段判断
tempObject.getClass().getDeclaredField(clientArr[j].getName());
//获取字段的写入方法
PropertyDescriptor descriptor = new PropertyDescriptor(clientArr[j].getName(), tempObject.getClass());
Method method = descriptor.getWriteMethod();
method.invoke(tempObject,clientArr[j].nameChangeByType((String)getCellFormatValue(tempRow.getCell(j))));
} catch (NoSuchFieldException e) {
continue;
} catch (Exception e) {
e.printStackTrace();
}
}
beanList.add(tempObject);
}
} catch (Exception e1) {
e1.printStackTrace();
}
return beanList;
}明确excel组成以及结构设计。
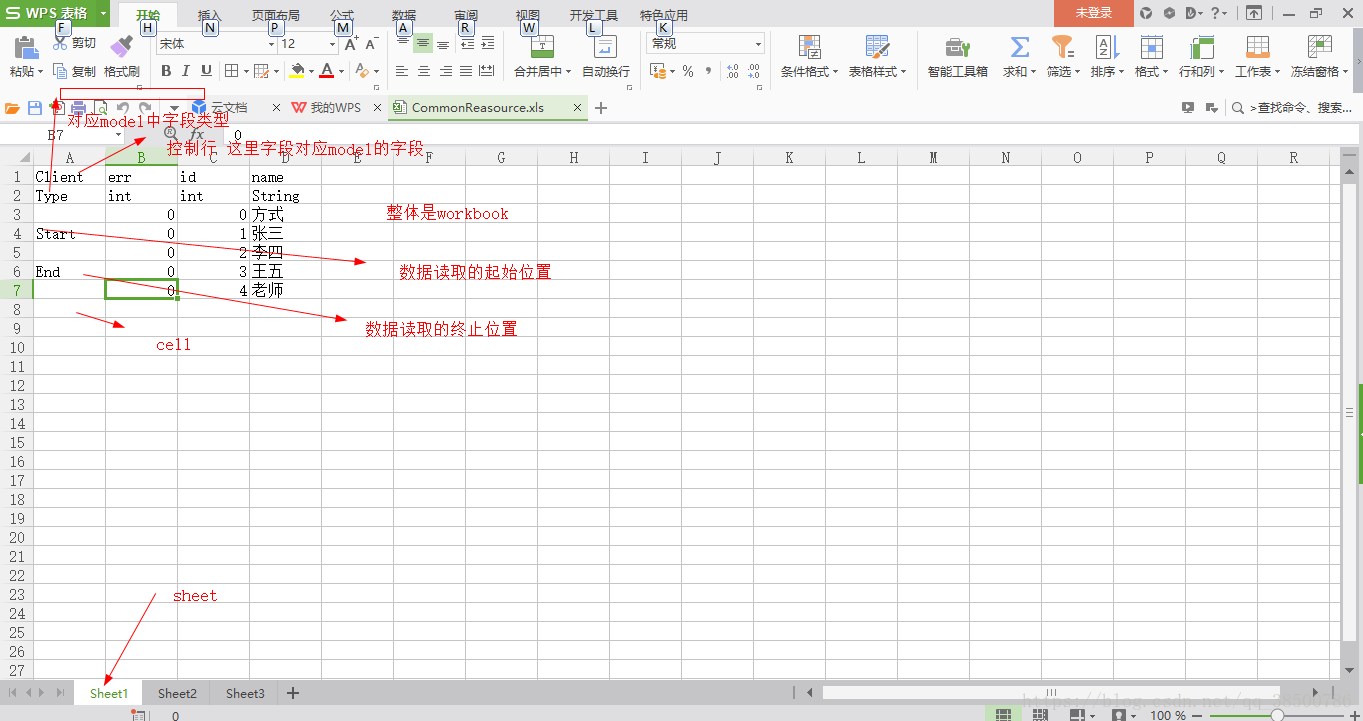
下面这个方法是判断excel中单元格类型。
public static Object getCellFormatValue(Cell cell){
Object cellValue = null;
if(cell!=null){
//判断cell类型
switch(cell.getCellTypeEnum()){
case NUMERIC:{
cellValue = String.valueOf(cell.getNumericCellValue());
break;
}
case FORMULA:{
//判断cell是否为日期格式
if(DateUtil.isCellDateFormatted(cell)){
//转换为日期格式YYYY-mm-dd
cellValue = cell.getDateCellValue();
}else{
//数字
cellValue = (int) cell.getNumericCellValue();
}
break;
}
case STRING:{
cellValue = cell.getRichStringCellValue().getString();
break;
}
default:
cellValue = "";
}
}else{
cellValue = "";
}
return cellValue;
}这个类存储从excel中读取的字段名称和字段类型。
public class ParmTypeOf {
//字段名称
private String name;
//字段类型
private String type;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
// excel传过来的数字可能是3.0这个字符串样式 java进行int转换时会出错,所以这里简单处理了一下
public Object nameChangeByType(String value) {
if(type.equals("int") || type.equals("Integer")) {
if(value.indexOf(".") != -1) {
value = value.substring(0, value.indexOf("."));
}
return Integer.valueOf(value);
}
return value;
}
}













 2015
2015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









