







周志华《机器学习》 学习笔记
最近开始学习机器学习,参考书籍西瓜书,做点笔记。
第二章 模型评估与选择
错误率:分类错误的样本数占样本总数的比例,E=a/m。
精度:分类正确的样本数占样本总数的比例,精确度=1-错误率。
过拟合:训练样本学的太好,导致泛化性能下降。
欠拟合:训练样本学的不太好。
测试集与训练集尽量互斥,测试样本尽量不在训练样本中出现。
产生训练集和测试集的方法:
1.留出法;
2.交叉验证法;
3.自助法。
性能度量:衡量模型泛化能力。
均方误差:预测值与实际值差的平方的总和除以样本总数。对于数据分布D,均方误差等于预测值与实际值差的平方乘以概率密度函数的积分。
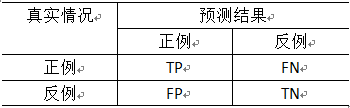
图1.1 分类结果混淆矩阵
查准率:P=TP/(TP+FP),即真实值与预测值均是正例的情况除以预测值均是正例的情况。
查全率:R=TP/(TP+FN),即真实值与预测值均是正例的情况除以真实值均是正例的情况。
P-R曲线:
1.若一个学习器的PR曲线被另一个PR曲线完全包住,则后者性能优于前者;
2.如果发生了交叉,则比较PR去线下的面积大小,但往往不容易估算;
3.选用查准率=查全率的直线找到PR曲线上的平衡点(BEP),平衡点取值越大性能更好;
4.BEP还是过于简化,常用F1度量。F1度量一般式中引入参数β:1>β>0,查准率影响更大;β=1,为标准F1;β>1,查全率影响更大;
ROC曲线纵轴:真正例率;横轴:假正例率。
真正例率:TPR=TP/(TP+FN)。即预测值与测试值均为正例的情况除以真实值为正例的所有情况。
假正例率:FPR=FP/(TN+FP)。即预测值为正例,真实值为反例的情况除以真实值为反例的所有情况。
ROC曲线判断:
1.若一个学习器的ROC曲线被另一个学习器的ROC曲线包住,则后者性能优于前者;
2.若两个曲线发生交叉,判断依据是ROC曲线下的面积,即AUC。
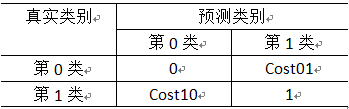
图1.2 二分类代价矩阵
costij表示将第i类样本预测为第j类样本的代价。通常用比值。
代价敏感错误率:代价Cost10情况的总和加上代价Cost01情况的总和除以样本总数。
比较检验以后再补充。第二章开始涉及许多公式,第一次看有点不适应,回过头来复习理一下思路就会比较清晰,还是需要花时间补一下数学特别是概率统计。
如有不正确或者不完整的地方,欢迎补充。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









