







全文检索之Lucene8.7.0
一、全文检索的概述
对非结构化数据进行信息提取,重新组织,使其变得有一定结构,该部分结构化数据就称之为索引。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是一个为应用程序提供索引和搜索功能。

下载解压后,在lucene-8.7.0目录中有三个重要的包:
analysis: Lucene分析器的包 lucene-analyzers-common-8.7.0.jar
core: Lucene核心包 lucene-core-8.7.0.jar
queryparser: Lucene查询分析器的包 lucene-queryparser-8.7.0.jar
highlighter: Lucene高亮显示的包 lucene-highlighter-8.7.0.jar

Lucene的基础类
Document
Document 是用来描述文档的,文档是指要索引和搜索的内容。内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。 一个 Document 对象由多个 Field 对象组成的。
Field
Field对象是用来描述一个文档的某个属性。
Analyzer
一个文档被索引之前,需要对文档内容进行分词处理,这时候就需要Analyzer。Analyzer 类是一个抽象类,有多个实现,Analyzer把分词后的内容交给 IndexWriter 来建立索引。
IndexWriter
IndexWriter是Lucene用来创建索引的一个核心的类,作用是把一个个的 Document 对象加到索引中来。
Directory
Directory代表Lucene的索引的存储的位置,是一个抽象类,它有两个实现,一个是 FSDirectory,表示一个存储在文件系统中的索引的位置。第二个是 RAMDirectory,表示一个存储在内存当中的索引的位置。
Lucene的实现流程
获得原始文档
原始文档是指要索引和搜索的内容,包括互联网上的网页、数据库中的数据、磁盘上的文件等。
创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field(域名和域值都相同)每个文档都有一个唯一的编号,就是文档id。
分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。
创建索引
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
查询索引
查询索引也是搜索的过程,即输入关键字,从索引(index)中进行搜索的过程。根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容。
创建查询
输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法。
执行查询
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。
二、初始化环境
使用上述下载lucene-8.7.0目录中的相关包或者使用Maven坐标引入项目。
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>8.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>8.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.8.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.jianggujin/IKAnalyzer-lucene -->
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
<scope>compile</scope>
</dependency>
</dependencies>
三、索引
创建索引
@Test
public void createIndex() throws Exception {
//1、创建一个Director对象,指定索引库保存的位置。
//1.1把索引库保存在内存中
//Directory directory = new RAMDirectory();
//1.2把索引库保存在磁盘
Directory directory = FSDirectory.open(new File("C:\\Users\\JackChen\\Desktop\\index").toPath());
//2、基于Directory对象创建一个IndexWriter对象
IndexWriterConfig config = new IndexWriterConfig();
//当使用IKAnalyzer分词时,是如下写法。
//IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory, config);
//3、读取磁盘上的文件,对应每个文件创建一个文档对象。
File dir = new File("C:\\Users\\JackChen\\Desktop\\document");
File[] files = dir.listFiles();
for (File f : files) {
//取文件名
String fileName = f.getName();
//文件的路径
String filePath = f.getPath();
//文件的内容
String fileContent = FileUtils.readFileToString(f, "utf-8");
//文件的大小
long fileSize = FileUtils.sizeOf(f);
//创建Field
//参数1:域的名称,参数2:域的内容,参数3:是否存储
Field fieldName = new TextField("name", fileName, Field.Store.YES);
Field fieldPath = new TextField("path", filePath, Field.Store.YES);
Field fieldContent = new TextField("content", fileContent, Field.Store.YES);
Field fieldSize = new TextField("size", fileSize + "", Field.Store.YES);
//创建文档对象
Document document = new Document();
//向文档对象中添加域
document.add(fieldName);
document.add(fieldPath);
document.add(fieldContent);
document.add(fieldSize);
//5、把文档对象写入索引库
indexWriter.addDocument(document);
}
//6、关闭indexwriter对象
indexWriter.close();
}
原始文档

索引库

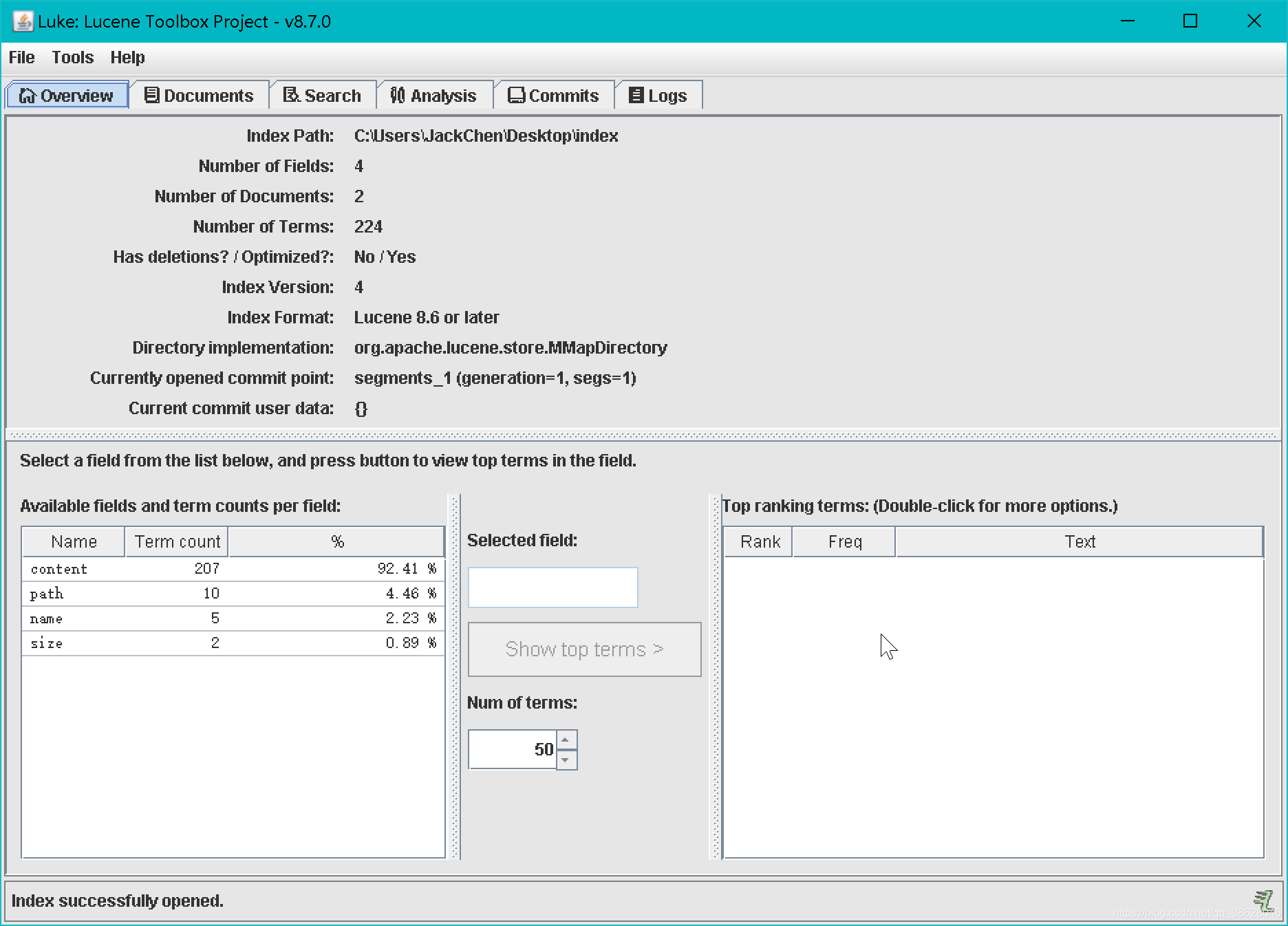
查看索引文件
Luke是查询Lucene索引文件的工具,该工具提供了一些常用的操作,如用Luke的Search可以做查询。
官方下载各个Luke版本:
注意:Lucene与Luke是有版本对应关系,且也与JDK有版本对应关系,详情需要阅读官方说明。
在该项目描述中得知,从Lucene 8.1开始,Luke成为了Apache Lucene的模块!所以在下载的Lucene工具包中就包含了此工具,可以直接使用。


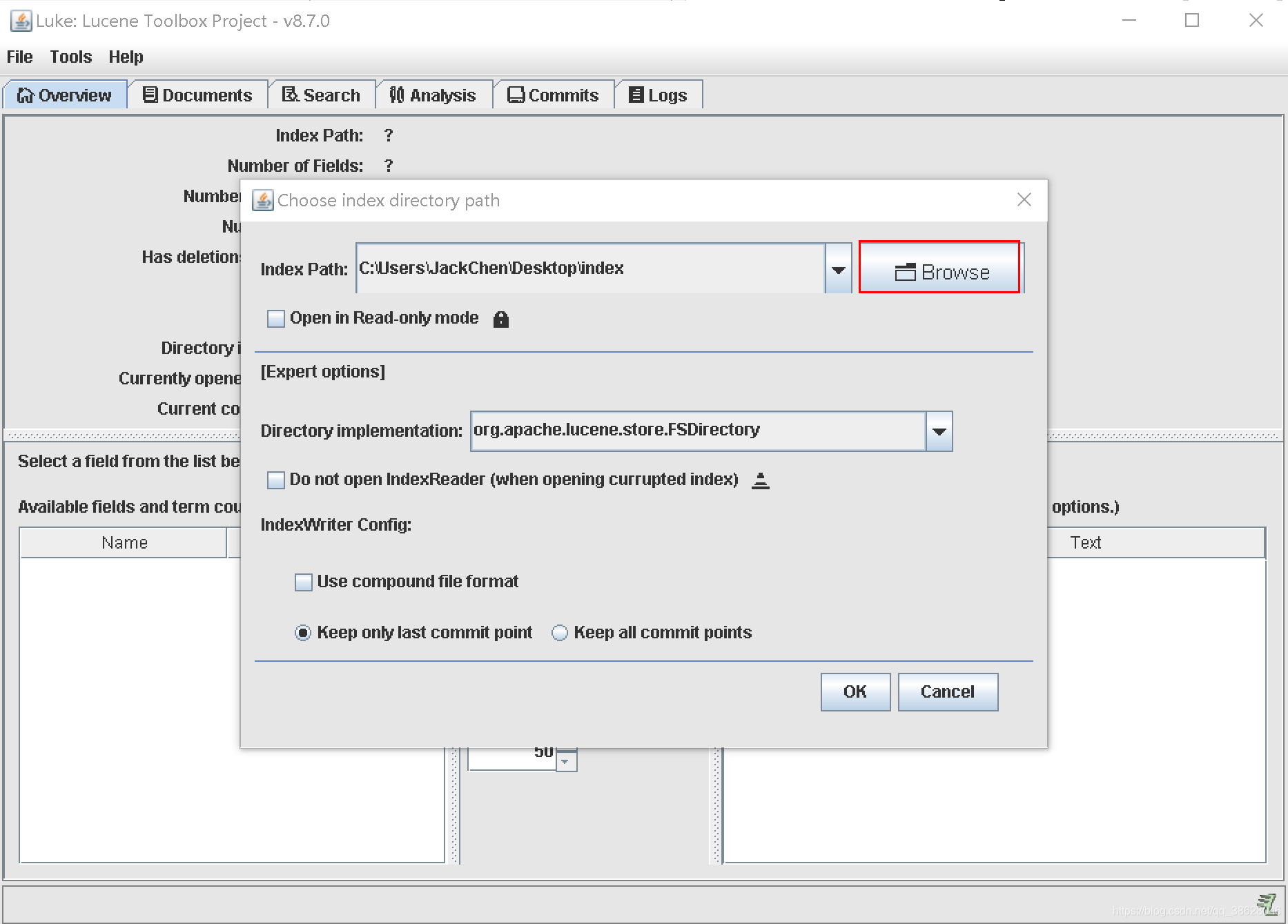
双击luke.bat后选择索引存放位置。
查询索引
@Test
public void searchIndex() throws Exception {
//1、创建一个Director对象,指定索引库的位置
Directory directory = FSDirectory.open(new File("C:\\Users\\JackChen\\Desktop\\index").toPath());
//2、创建一个IndexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
//3、创建一个IndexSearcher对象,构造方法中的参数indexReader对象。
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//4、创建一个Query对象,TermQuery
Query query = new TermQuery(new Term("content", "lucene"));
//5、执行查询,得到一个TopDocs对象
//参数1:查询对象 参数2:查询结果返回的最大记录数
TopDocs topDocs = indexSearcher.search(query, 10);
//6、取查询结果的总记录数
System.out.println("查询总记录数:" + topDocs.totalHits);
//7、取文档列表
ScoreDoc[] scoreDocs = ((TopDocs) topDocs).scoreDocs;
//8、打印文档中的内容
for (ScoreDoc doc : scoreDocs) {
//取文档id
int docId = doc.doc;
//根据id取文档对象
Document document = indexSearcher.doc(docId);
System.out.println(document.get("name"));
System.out.println(document.get("path"));
System.out.println(document.get("content"));
System.out.println(document.get("size"));
}
//9、关闭IndexReader对象
indexReader.close();
}
查询总记录数:2 hits
name: Luke.txt
path: C:\Users\JackChen\Desktop\document\Luke.txt
content: Please see:
Luke become an Apache Lucene module (as of Lucene 8.1)!
This repository is no longer maintained. Please download Lucene binary release package to get the latest Luke (8.1+).
For contributors: Now Luke is a part of Apache Lucene, issues should be opened in the Apache Lucene Jira.
Luke atop Swing.
Luke is the GUI tool for introspecting your Lucene / Solr / Elasticsearch index. It allows:
Browsing your documents, indexed terms and posting lists
Searching in the index
Performing index maintenance: index health checking, index optimization (take a backup before running this!)
Testing your custom Lucene analyzer (Tokenizer/CharFilter/TokenFilter)
size: 683
---------------------------------------------
name: Lucene.txt
path: C:\Users\JackChen\Desktop\document\Lucene.txt
content: Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。
Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。
人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
size: 1054
---------------------------------------------
进程已结束,退出代码0
四、分析器的使用
StandardAnalyzer分析器
Lucene默认使用的是StandardAnalyzer分析器,仅对英文分词友好,对中文分词需使用IKAnalyzer。
@Test
public void standardAnalyzer() throws Exception {
//1.创建一个Analyzer对象,StandardAnalyzer对象
Analyzer analyzer = new StandardAnalyzer();
//2.使用分析器对象的tokenStream方法获得一个TokenStream对象
String text1="Please see: Luke become an Apache Lucene module (as of Lucene 8.1)!";
String text2="Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。";
TokenStream tokenStream = analyzer.tokenStream("", text1);
//3.向TokenStream对象中设置一个引用,相当于数一个指针
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//4.调用TokenStream对象的rest方法。如果不调用抛异常
tokenStream.reset();
//5.使用while循环遍历TokenStream对象
while (tokenStream.incrementToken()) {
System.out.println(charTermAttribute.toString());
}
//6.关闭TokenStream对象
tokenStream.close();
}
当是英文时:
please
see
luke
become
an
apache
lucene
module
as
of
lucene
8.1
进程已结束,退出代码0
当是中文时:
lucene
是
apache
软
件
基
金
会
4
jakarta
项
目
组
的
.....
进程已结束,退出代码0
IKAnalyzer分析器
1。需引入IKAnalyzer分词的依赖包 IKAnalyzer-lucene.jar
<!-- https://mvnrepository.com/artifact/com.jianggujin/IKAnalyzer-lucene -->
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>
2。添加扩展词典hotword.dic,对词整体不分词,可被搜索,
我是扩展词典
3。添加停用词词典ext_stopword.dic,对词整体停用不分词,不可被搜索
我是停用词典
4。添加IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IKAnalyzer扩展配置</comment>
<!--配置扩展字典 -->
<entry key="ext_dict">hotword.dic;</entry>
<!--配置停用词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
5。注意: 文件的格式要为UTF-8
@Test
public void standardAnalyzer() throws Exception {
//1.创建一个Analyzer对象,StandardAnalyzer对象
Analyzer analyzer = new IKAnalyzer();
//2.使用分析器对象的tokenStream方法获得一个TokenStream对象
String text1="Please see: Luke become an Apache Lucene module (as of Lucene 8.1)!";
String text2="Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。";
TokenStream tokenStream = analyzer.tokenStream("", text1);
//3.向TokenStream对象中设置一个引用,相当于数一个指针
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//4.调用TokenStream对象的rest方法。如果不调用抛异常
tokenStream.reset();
//5.使用while循环遍历TokenStream对象
while (tokenStream.incrementToken()) {
System.out.println(charTermAttribute.toString());
}
//6.关闭TokenStream对象
tokenStream.close();
}
当是英文时:
加载扩展词典:hotword.dic
加载扩展停止词典:stopword.dic
我是扩展词典
我
是
扩展
词典
我
是
停用
用词
词典
please
see
luke
become
apache
lucene
module
lucene
8.1
进程已结束,退出代码0
当是中文时:
加载扩展词典:hotword.dic
加载扩展停止词典:stopword.dic
我是扩展词典
我
是
扩展
词典
我
是
停用
用词
词典
lucene
是
apache
软件
基金会
基金
....
进程已结束,退出代码0
五 、索引库的维护
Field域有如下属性:
Analyzed是否分析:对域的内容进行分词处理。前提是要对域的内容进行查询。
Indexed是否索引:将Field分析后的词或整个Field值进行索引,只有索引才可以搜索到。
Stored是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取。
| Field域 | 数据类型 | Analyzed | Indexed | Stored | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | False | True | True 或False | 构建一个字符串Field,不进行分析,将整个串存储在索引中 |
| LongPoint(String name, long… point) | Long型 | True | True | False | 可以使用LongPoint、IntPoint等类型存储数值类型的数据。让数值类型可以进行索引。但不能存储数据,如果想存储数据需要使用StoredField。 |
| StoredField(FieldName, FieldValue) | 支持多种类型 | False | False | True | 用来构建不同类型Field不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO)或TextField(FieldName, reader) | 字符串或流 | True | True | True 或False | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
添加索引库
@Test
public void addDocument() throws Exception {
//1.创建一个Director对象,指定索引库保存的位置。
//把索引库保存在内存中
//Directory directory = new RAMDirectory();
//把索引库保存在磁盘
Directory directory = FSDirectory.open(new File("C:\\Users\\JackChen\\Desktop\\index").toPath());
//2.基于Directory对象创建一个IndexWriter对象,默认使用StandardAnalyzer分析器
//IndexWriterConfig config = new IndexWriterConfig();
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory, config);
//3.创建一个Document对象
Document document = new Document();
//向document对象中添加域
document.add(new TextField("name", "lucene", Field.Store.YES));
document.add(new TextField("content", "content", Field.Store.NO));
//不需要创建索引使用StoreField存储
document.add(new StoredField("path", "path"));
///LongPoint创建索引
document.add(new LongPoint("size", 10));
//StoreField存储数据
document.add(new StoredField("size", 100));
//4.把文档写入索引库
indexWriter.addDocument(document);
//5.关闭索引库
indexWriter.close();
}
删除索引库
@Test
public void deleteAllDocument() throws Exception {
//1.创建一个Director对象,指定索引库保存的位置。
//把索引库保存在内存中
//Directory directory = new RAMDirectory();
//把索引库保存在磁盘
Directory directory = FSDirectory.open(new File("C:\\Users\\JackChen\\Desktop\\index").toPath());
//2.基于Directory对象创建一个IndexWriter对象,默认使用StandardAnalyzer分析器
//IndexWriterConfig config = new IndexWriterConfig();
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory, config);
//3.删除文档
//3.1删除全部文档
// indexWriter.deleteAll();
//3.2根据关键词删除文档
//indexWriter.deleteDocuments(new Term("name", "lucene"));
//3.3根据查询条件删除文档
//创建一个查询条件
Query query = new TermQuery(new Term("name", "lucene"));
//根据查询条件删除
indexWriter.deleteDocuments(query);
//4.关闭索引库
indexWriter.close();
}
修改索引库
@Test
public void updateDocument() throws Exception {
//1.创建一个Director对象,指定索引库保存的位置。
//把索引库保存在内存中
//Directory directory = new RAMDirectory();
//把索引库保存在磁盘
Directory directory = FSDirectory.open(new File("C:\\Users\\JackChen\\Desktop\\index").toPath());
//2.基于Directory对象创建一个IndexWriter对象,默认使用StandardAnalyzer分析器
//IndexWriterConfig config = new IndexWriterConfig();
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory, config);
//创建一个新的文档对象
Document document = new Document();
//向document对象中添加域
document.add(new TextField("name", "lucene2", Field.Store.YES));
document.add(new TextField("content", "content2", Field.Store.NO));
//不需要创建索引使用StoreField存储
document.add(new StoredField("path", "path2"));
///LongPoint创建索引
document.add(new LongPoint("size", 10));
//StoreField存储数据
document.add(new StoredField("size", 100));
//更新操作
indexWriter.updateDocument(new Term("name", "lucene"), document);
//关闭索引库
indexWriter.close();
}
六、索引库的查询
TermQuery查询
TermQuery,通过创建Query,指定Field域查询,由于TermQuery不使用分析器,所以适合匹配不分词的Field域查询。
@Test
public void testTermQuery() throws Exception {
//创建IndexReader对象,指定索引库保存的位置。
IndexReader indexReader = DirectoryReader.open(FSDirectory.open(new File("C:\\Users\\JackChen\\Desktop\\index").toPath()));
//创建IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//创建一个Query对象
//1.指定域的范围查询
Query query = LongPoint.newRangeQuery("size", 0l, 100l);
//2.指定Field域的关键词查询
//Query query =new TermQuery( new Term("name", "lucene.txt"));
//执行查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("查询总记录数:" + topDocs.totalHits);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历查询结果
for (ScoreDoc doc:scoreDocs){
//取文档id
int docId = doc.doc;
//根据id取文档对象
Document document = indexSearcher.doc(docId);
System.out.println(document.get("name"));
System.out.println(document.get("content"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
}
indexReader.close();
}
范围查询
查询总记录数:1 hits
----------开始------------
lucene2
null
path2
100
----------结束------------
Process finished with exit code 0
指定Field域的关键词查询
查询总记录数:1 hits
----------开始------------
Lucene.txt
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
C:\Users\JackChen\Desktop\document\Lucene.txt
1054
----------结束------------
Process finished with exit code 0
Queryparser查询
Queryparser,通过创建Query,指定Field域查询,由于Queryparser使用分析器,所以推荐创建索引时使用的分析器和查询索引时使用的分析器要一致,此时就会用到lucene-queryparser-8.7.0.jar该依赖包。
@Test
public void testQueryParser() throws Exception {
//创建IndexReader对象,指定索引库保存的位置。
IndexReader indexReader = DirectoryReader.open(FSDirectory.open(new File("C:\\Users\\JackChen\\Desktop\\index").toPath()));
//创建IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//创建QueryPaser对象,两个参数
QueryParser queryParser = new QueryParser("name", new IKAnalyzer());
//使用QueryPaser对象创建一个Query对象,参数1:默认搜索域,参数2:分析器对象
Query query = queryParser.parse("lucene.txt");
//执行查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("总记录数:" + topDocs.totalHits);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历查询结果
for (ScoreDoc doc:scoreDocs){
//取文档id
int docId = doc.doc;
//根据id取文档对象
Document document = indexSearcher.doc(docId);
System.out.println(document.get("name"));
System.out.println(document.get("content"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
}
indexReader.close();
}
加载扩展词典:hotword.dic
加载扩展停止词典:stopword.dic
总记录数:3 hits
----------开始------------
Lucene.txt
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
C:\Users\JackChen\Desktop\document\Lucene.txt
1054
----------结束------------
----------开始------------
lucene2
null
path2
100
----------结束------------
----------开始------------
Luke.txt
Please see:
Luke become an Apache Lucene module (as of Lucene 8.1)!
This repository is no longer maintained. Please download Lucene binary release package to get the latest Luke (8.1+).
C:\Users\JackChen\Desktop\document\Luke.txt
683
----------结束------------
Process finished with exit code 0
Highlighter查询
Highlighter让搜索出来的内容通过设置关键字让其变为高亮。
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-highlighter -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>8.7.0</version>
</dependency>
@Test
public void testHighlighter() throws Exception {
//创建IndexReader对象,指定索引库保存的位置。
IndexReader indexReader = DirectoryReader.open(FSDirectory.open(new File("C:\\Users\\JackChen\\Desktop\\index").toPath()));
//创建IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//创建QueryPaser对象,两个参数
QueryParser queryParser = new QueryParser("name", new IKAnalyzer());
//使用QueryPaser对象创建一个Query对象,参数1:默认搜索域,参数2:分析器对象
Query query = queryParser.parse("lucene.txt");
//格式化对象,设置前缀和后缀
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
//关键词对象
QueryScorer scorer = new QueryScorer(query);
//高亮对象
Highlighter highlighter = new Highlighter(formatter, scorer);
//执行查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("总记录数:" + topDocs.totalHits);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历查询结果
for (ScoreDoc doc:scoreDocs){
System.out.println("----------开始------------");
//取文档id
int docId = doc.doc;
//根据id取文档对象
Document document = indexSearcher.doc(docId);
//设置内容高亮
String highlighterContent = highlighter.getBestFragment(new StandardAnalyzer(),"name",document.get("name"));
System.out.println(highlighterContent);
document.getField("content");
System.out.println(document.get("name"));
System.out.println(document.get("content"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
System.out.println("----------结束------------");
}
indexReader.close();
}
加载扩展词典:hotword.dic
加载扩展停止词典:stopword.dic
总记录数:1 hits
----------开始------------
<font color='red'>Lucene.txt</font>
Lucene.txt
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎...
C:\Users\JackChen\Desktop\document\Lucene.txt
1054
----------结束------------
Process finished with exit code 0
















 709
709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











