







正则表达式的使用,可以通过简单的办法来实现强大的功能。下面先给出一个简单的示例:
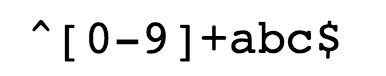
^ 为匹配输入字符串的开始位置。
[0-9]+匹配多个数字, [0-9] 匹配单个数字(数字出现一次),+ 匹配一个或者多个(表示数字0~9出现一次或者多次。)
abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置。
var pattern = /[0-9]+abc/g,
str = '123abcdd';
console.log(pattern.test(str));//123abcvar pattern = /^[0-9]+abc$/g,
str = '123abcdd';
console.log(pattern.test(str));//NULL
-
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 号代表前面的字符必须至少出现一次(1次或多次)。
-
runoo*b,可以匹配 runob、runoob、runoooooob 等,* 号代表字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。
-
colou?r 可以匹配 color 或者 colour,? 问号代表前面的字符最多只可以出现一次(0次、或1次)。
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
*、+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
例如,您可能搜索 HTML 文档,以查找括在 H1 标记内的章节标题。该文本在您的文档中如下:
<H1>Chapter 1 - 介绍正则表达式</H1>贪婪:下面的表达式匹配从开始小于符号 (<) 到关闭 H1 标记的大于符号 (>) 之间的所有内容。
/<.*>/非贪婪:如果您只需要匹配开始和结束 H1 标签,下面的非贪婪表达式只匹配 <H1>。
/<.*?>/如果只想匹配开始的 H1 标签,表达式则是:
/<\w+?>/通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从"贪心"表达式转换为"非贪心"表达式或者最小匹配。
待续。。。
参考链接:http://www.runoob.com/regexp/regexp-syntax.html

















 2853
2853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









