






主要围绕以下三点展开分析:
HashMap 内部实现基本点分析。
容量(capacity)和负载系数(load factor)。
树化 。
首先,我们来一起看看 HashMap 内部的结构,它可以看作是数组(Node<K,V>[] table)和链表结合组成的复合结构,数组被分为一个个桶(bucket),通过哈希值决定了键值对在这个数组的寻址;哈希值相同的键值对,则以链表形式存储,你可以参考下面的示意图。这里需要注意的是,如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),图中的链表就会被改造为树形结构。
HashMap实现原理
首先,我们来一起看看 HashMap 内部的结构,它可以看作是数组(Node<K,V>[] table)和链表结合组成的复合结构,数组被分为一个个桶(bucket),通过哈希值决定了键值对在这个数组的寻址;哈希值相同的键值对,则以链表形式存储,你可以参考下面的示意图。这里需要注意的是,如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),图中的链表就会被改造为树形结构。
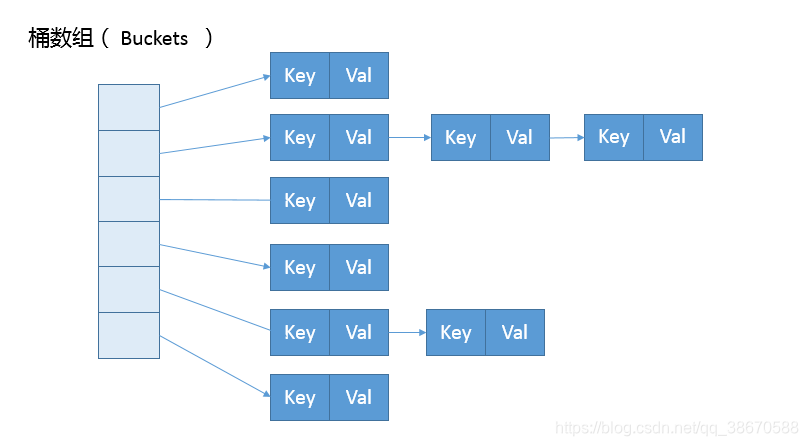
从非拷贝构造函数的实现来看,这个表格(数组)似乎并没有在最初就初始化好,仅仅设置了一些初始值而已。
public HashMap(int initialCapacity, float loadFactor){
// ...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
所以,我们深刻怀疑,HashMap 也许是按照 lazy-load 原则,在首次使用时被初始化(拷贝构造函数除外,我这里仅介绍最通用的场景)。既然如此,我们去看看 put 方法实现,似乎只有一个 putVal 的调用:
public HashMap(int initialCapacity, float loadFactor){
// ...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
所以,我们深刻怀疑,HashMap 也许是按照 lazy-load 原则,在首次使用时被初始化(拷贝构造函数除外,我这里仅介绍最通用的场景)。既然如此,我们去看看 put 方法实现,似乎只有一个 putVal 的调用:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
看来主要的秘密似乎藏在 putVal 里面,到底有什么秘密呢?为了节省空间,我这里只截取了 putVal 比较关键的几部分。
final V putVal(int hash, K key, V value, boolean onlyIfAbent,
boolean evit) {
Node<K,V>[] tab; Node<K,V> p; int , i;
if ((tab = table) == null || (n = tab.length) = 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == ull)
tab[i] = newNode(hash, key, value, nll);
else {
// ...
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for first
treeifyBin(tab, hash);
// ...
}
}
从 putVal 方法最初的几行,我们就可以发现几个有意思的地方:
- 如果表格是 null,resize 方法会负责初始化它,这从 tab = resize() 可以看出。
- resize 方法兼顾两个职责,创建初始存储表格,或者在容量不满足需求的时候,进行扩容(resize)。
- 在放置新的键值对的过程中,如果发生下面条件,就会发生扩容。
if (++size > threshold)
resize();
具体键值对在哈希表中的位置(数组 index)取决于下面的位运算
i = (n - 1) & hash
仔细观察哈希值的源头,我们会发现,它并不是 key 本身的 hashCode,而是来自于 HashMap 内部的另外一个 hash 方法。注意,为什么这里需要将高位数据移位到低位进行异或运算呢?这是因为有些数据计算出的哈希值差异主要在高位,而 HashMap 里的哈希寻址是忽略容量以上的高位的,那么这种处理就可以有效避免类似情况下的哈希碰撞。
static final int hash(Object kye) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>>16;
}
可以看到,putVal 方法本身逻辑非常集中,从初始化、扩容到树化,全部都和它有关,推荐你阅读源码的时候,可以参考上面的主要逻辑。
- 门限值等于(负载因子)x(容量),如果构建 HashMap 的时候没有指定它们,那么就是依据相应的默认常量值。
- 门限通常是以倍数进行调整 (newThr = oldThr << 1),我前面提到,根据 putVal中的逻辑,当元素个数超过门限大小时,则调整 Map 大小。
- 扩容后,需要将老的数组中的元素重新放置到新的数组,这是扩容的一个主要开销来源。
容量、负载因子和树化
容量
前面我们快速梳理了一下 HashMap 从创建到放入键值对的相关逻辑,现在思考一下,为什么我们需要在乎容量和负载因子呢?
这是因为容量和负载系数决定了可用的桶的数量,空桶太多会浪费空间,如果使用的太满则会严重影响操作的性能。极端情况下,假设只有一个桶,那么它就退化成了链表,完全不能提供所谓常数时间存的性能。
既然容量和负载因子这么重要,我们在实践中应该如何选择呢?如果能够知道 HashMap 要存取的键值对数量,可以考虑预先设置合适的容量大小。具体数值我们可以根据扩容发生的条件来做简单预估,根据前面的代码分析,我们知道它需要符合计算条件:
负载因子 * 容量 > 元素数量
负载因子
所以,预先设置的容量需要满足,大于“预估元素数量 / 负载因子”,同时它是 2 的幂数,结论已经非常清晰了。
而对于负载因子,我建议:
- 如果没有特别需求,不要轻易进行更改,因为 JDK 自身的默认负载因子是非常符合通用场景的需求的。
- 如果确实需要调整,建议不要设置超过 0.75 的数值,因为会显著增加冲突,降低 HashMap 的性能。
- 如果使用太小的负载因子,按照上面的公式,预设容量值也进行调整,否则可能会导致更加频繁的扩容,增加无谓的开销,本身访问性能也会受影响。
树化
那么,为什么 HashMap 要树化呢?本质上这是个安全问题。因为在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,我们知道链表查询是线性的,会严重影响存取的性能。而在现实世界,构造哈希冲突的数据并不是非常复杂的事情,恶意代码就可以利用这些数据大量与服务器端交互,导致服务器端 CPU 大量占用,这就构成了哈希碰撞拒绝服务攻击,国内一线互联网公司就发生过类似攻击事件。今天我从 Map 相关的几种实现对比,对各种 Map 进行了分析,讲解了有序集合类型容易混淆的地方,并从源码级别分析了 HashMap 的基本结构,希望对你有所帮助。














 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









