







前言
MLP-Mixer,Google又提出的一种基于感知机的网络。尽管CNN 已经在计算机视觉上取得很好的效果,最近提出来的基于Attention,以Vision Transformer 为首的神经网络已经 “杀疯” CV界,但是Google的大佬们认为CNN 和Attention 也不是必须的,于是就提出了MLP-Mixer,在分类任务上也达到了很好的效果。但是网络的提出却早到了CNN之父LeCun的“教育”。因为网络的第一层(embedding时)却用到了卷积。

LeCun认为,这不过是 一个卷积核为1x1的卷积网络罢了。我在复现过程中,没有找到一个合适的数据集用该网络取得一个很好的效果。所以这里不附上训练的代码了。
| 项目 | 链接 |
|---|---|
| 论文 | 链接 |
(仅torch, 可训练,eval top1 and top5):https://github.com/jiantenggei/torch-classification
博客中给出的就是网络结构的全部代码。
一、MLP-Mixer原理介绍
在介绍MLP -Mixer 之前,先引入一下 ViT 结构,如下图所示:
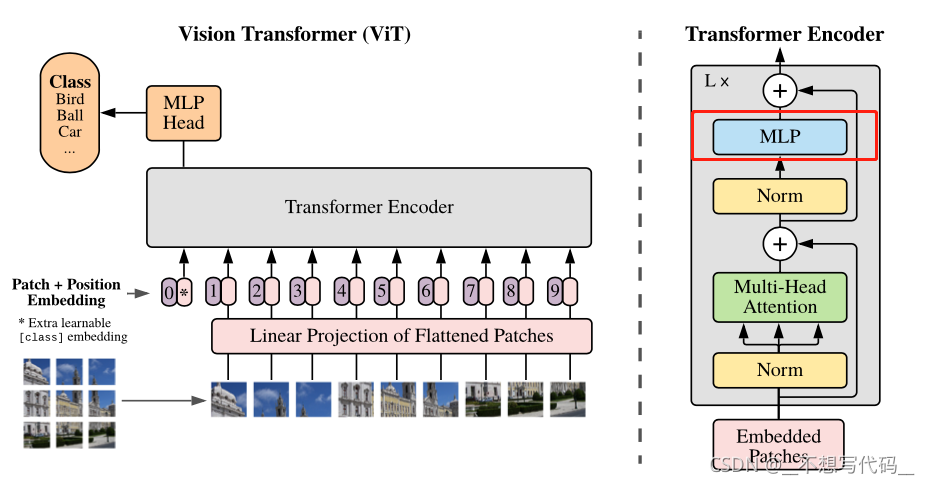
图中Transformer Encoder 的红色方框中的MLP 结构(如下图所示),就是MLP -Mixer的结构。
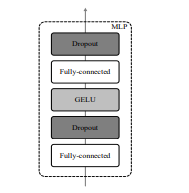
对于MLP -Mixer 的提出,Google方面的大佬只是为了验证MLP 也能做很多事情。
但这篇文章 Do You Even Need Attention? A Stack of Feed-Forward Layers DoesSurprisingly Well on ImageNet 为了探寻ViT中起作用的部分是 Attention 还是MLP, 直接删除到ViT中的Attention部分做实验,发现效果也还行,网络如下图所示。它与本文介绍MLP-Mixer的不同点是,它保留了ViT 中Class Token 部分(粉红色方块) 最后用Class Token 来做预测。
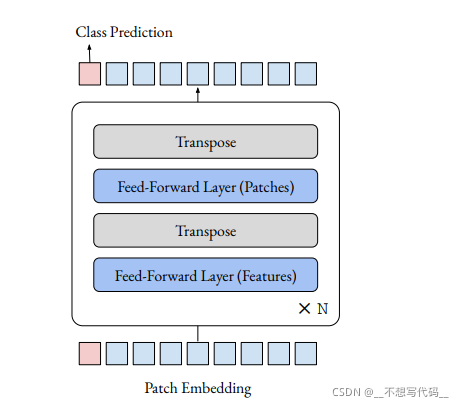
MLP- Mixer 是通过一个全局池化后连接全连接层来做预测。
1.网络结构
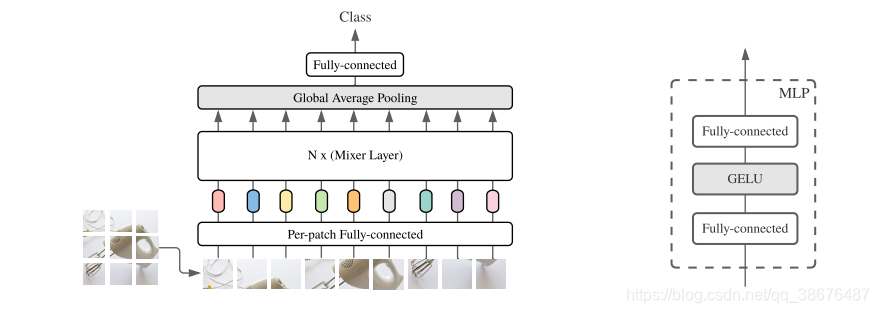
从上图我们可以看出,MLP -Mixer 首先使用图片分成很多个小正方形的patch,每个patch的大小定义为patch_size。论文中实现这一步骤使用的是前面提到的卷积,卷积核的大小和步长均patch_size。论文中给的参数,也是2的幂。
网络不再使用传统的RELU激活函数,而是使用了GELU激活函数。
将图片分成小块后,在将它转换为一维结构。如图:

然后将每一个patch进行转换,如下图所示:
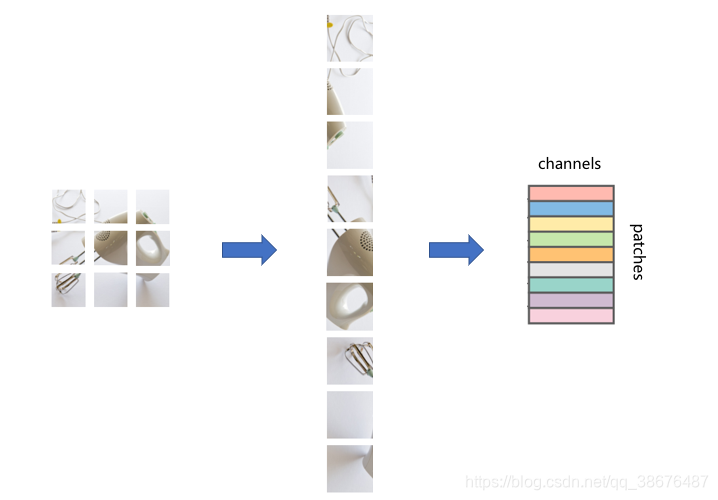
通过这样一种方式呢,就将一张图片转换为了一个大矩阵,就可以输入到Mixer Layer 中进行计算。
2. Mixer Layer
MixerLayer的结构如下图所示:
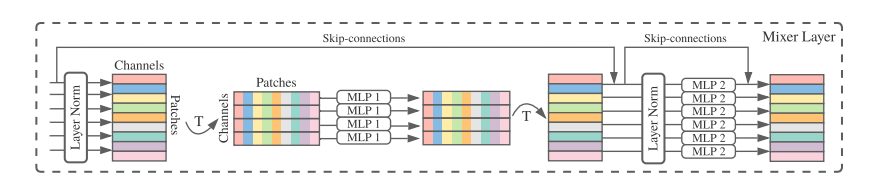
我们看一下论文里给出的公式:

MLP 是两个全连接层的感知机,W1,W2,对应token_mixer中两个全连接的权重,W3,W4则表示channel_mixer两个全连接的权重。σ表示GELU激活函数。那么公示就很简单了,输入X经过Layer Normalize,再乘以W1,再经过激活函数后乘以W2,再加上X。第二个公式也是相同的计算过程。
将前面通过编码得到的矩阵经过Layer Norm 在将矩阵进行旋转(T 表示旋转)连接MLP1,MLP1 就是文章token_mixer 用来寻找像素与像素之间的关系,其中,MLP1中的权值共享。计算完之后,再将矩阵旋转回来,通过Layer Norm 后再接一个channel_mixer 用于寻找通道与通道之间的关系。其中MixerLayer 还启用了ResNet中的跨连结构,跨连结构的作用可以参考[ResNet原理讲解和复现],看到这里,是不是感觉它跟卷积的原理很类似。
从上图可以看出Mixer Layer的输入维度和输出维度相同,并且通过MLP的方式来寻找图片像素与像素,通道与通道的关系。
这就是MLP-MIXER的网络结构了,目前的了解,没有开源的pytorch或者TensorFlow 预训练的权重。官方给出的代码和权重是基于JAX的。
由于需要Patch embedding的网络 对于图片大小的依赖高,所以一般很难使用官方的权重进行迁移学习,如果想使用到自己的任务中,建议使用一个较大的数据集先预训练一下
3.MLP-Mixer模型类型
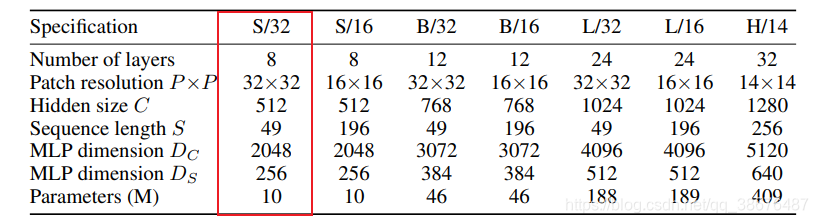
文章中给出的模型参数列表,Patch resolution 就是patch 的长宽。Hidden size 就是映射成前面提到的大矩阵的维度,Squence length 是计算后的结果。
以上图红色部分为例,输入图像大小为224*224,
然后分成的块大小为32*32.
那么 (224*224)\(32*32)=7*7,Squence length 就为 49。Dc和Ds分别表示token_mixer和channel_mixer 中全连接层节点的个数。
这就是MLP-Mixer的全部过程了。
二、网络实现
1.Pytorch复现
实现的难点在于,矩阵旋转,我们使用einops中的Rearrange实现矩阵旋转。还需要使用torchsummary 来查看网络结构。安装:
pip install einops
pip install torchsummary
首先我们来实现MLP 也就是FeedForward:
#定义多层感知机
import torch
import numpy as np
from torch import nn
from einops.layers.torch import Rearrange
from torchsummary import summary
import torch.nn.functional as F
class FeedForward(nn.Module):
def __init__(self,dim,hidden_dim,dropout=0.):
super().__init__()
self.net=nn.Sequential(
#由此可以看出 FeedForward 的输入和输出维度是一致的
nn.Linear(dim,hidden_dim),
#激活函数
nn.GELU(),
#防止过拟合
nn.Dropout(dropout),
#重复上述过程
nn.Linear(hidden_dim,dim),
nn.Dropout(dropout)
)
def forward(self,x):
x=self.net(x)
return x
#测试多层感知机
# mlp=FeedForward(10,20,0.4).to(device)
# summary(mlp,input_size=(10,))
实现过程很简单,就是全连接结构
接着我们来实现Mixer Block,里面包含了 token_mixer 和channel_mixer,还有矩阵转置。
#使用Rearrange 实现旋转
Rearrange('b n d -> b d n') #这里是[batch_size, num_patch, dim] -> [batch_size, dim, num_patch]
实现如下:
class MixerBlock(nn.Module):
def __init__(self,dim,num_patch,token_dim,channel_dim,dropout=0.):
super().__init__()
self.token_mixer=nn.Sequential(
nn.LayerNorm(dim),
Rearrange('b n d -> b d n' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











