







文章目录
文章:常虹,山世光. 深度学习概述[J].信息技术快报.
Part 1 摘要
深度学习是机器学习的一个新的研究方向,其核心思想在语言模拟人脑的层级抽象结构,通过无监督的方式从大规模数据(声音、文本、图像等)中提取出特征。
文章脉络:深度学习概念、发展历程、模型、训练方法和应用场景。
关键词:深度学习;神经网络;无监督学习;深度置信网络;自动编码器
Part 2 引言
深度学习是相对于SVM、KNN、Gradient Boost等浅层学习算法而言的。深度是指一个流向图(flow graph)从输入到输出所走的最长的路径。例如SVM深度为2,第一层是核输出或是特征空间,第二层是线性混合的分类输出。传统的前馈神经网络深度等于其层次的数目。
本西奥对深度学习的研究表明每个函数都有固定的最小深度,即在运算次序上尽可能并行之后的运行次数。函数深度与运算方法有很大关系。哈斯塔德等人证明如果一个k层网络模型紧致地表示一个函数,那么用k-1层网络模型表示该函数则需要指数倍的计算单元。深层结构可以用少于函数变量和训练数据的计算单元紧致地表示高度变化的函数,这是大多数现有的浅层机器学习方法不可比拟的。所以本西奥等人认为,增加网络结构的深度从统计学的效率来看十分重要。
除了更强大的函数表达能力和泛化能力,深度学习的结果比较自然地体现了底层特征到高层特征的演变。例如,深度模型可以表示“图像块或像素点—>边缘—>部件—>物体”的学习过程,而这个过程与生物的视觉感知系统十分契合。
Part 3 深度学习发展历程
目前深度学模型中可堆叠的学习结构主要是多层神经网络。
| 时间 | 发展 | 特征 | |
|---|---|---|---|
| 二十世纪六十年代 | 神经网络第一次兴起 | ||
| 二十世纪八十年代 | 第二代神经网络利用反向传播(back propagation,BP)方法学习网络参数 | 需要标注数据,可扩展性差,统一陷入局部极小 | |
| 2006-2012年 | 无监督预训练对权值进行初始化+有监督训练微调 2011年,ReLU激活函数被提出, | ReLU激活函数能够有效的抑制梯度消失问题 | |
| 2012-2017年 | CNN发展 ReLU函数在AlexNet中的使用 | 1、首次采用ReLU激活函数,极大增大收敛速度并从根本上解决了梯度消失的问题 2、由于ReLU很好地一直梯度消失问题,AlexNet放弃了“预训练+微调”的方法,完全采用有监督训练,从此深度学习的主流学习方法变为纯粹的有监督学习。 3、扩展了LeNet5结构,添加dropout层减小过拟合,LRN层增强泛化能力/减小过拟合。 4、第一次使用GPU加速运算。 | |
| 2017-现在 | 深度学习目前仍在不断发展中 |
Part 4 深度学习的模型与训练方法
主流深度学习模型
1、卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNNs)是一种有监督学习的深度模型。基本思想是在前层网络的不同位置共享特征映射的权重,利用空间相对关系减少参数数目以提高训练性能。
下图为卷积神经网络抽取图像特征的过程
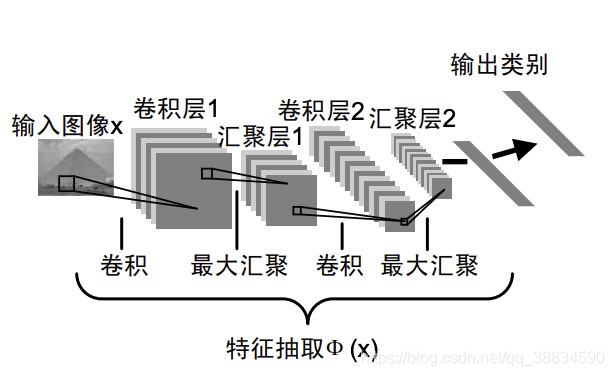
2、受限玻尔兹曼机和深度置信网络
受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)是玻尔兹曼机的一种变形,即去掉原始的玻尔兹曼机中可见节点之间及隐藏节点之间的连接,它是一种基于能量的模型。其中二进制神经元的概率值可以用个激励的向上和向下传播获得,使用对比离散度(contrastive divergence)方法很大程度上提高了模型的训练程度。
受限玻尔兹曼机提供了无监督学习单层网络的方法,如果把隐藏层的层数增加,即得到了深度玻尔兹曼机,如果在靠近可见层的部分采用贝叶斯网络(即有向图模型),而在最原理可见层的部分使用受限玻尔兹曼机,即得到深度置信网络(Deep Belief Networks,DBNs)
下图左侧为受限玻尔兹曼机,右侧为深度置信网络。
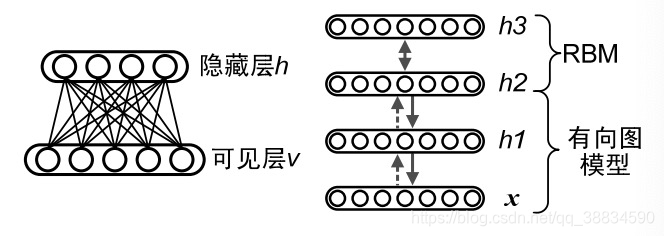
3、自动编码器
自动编码器(Autoencoder,AE)为单层网络结构。与深度执行网络的概率图模型不同,自动编码器通常以重构误差作为优化的目标函数,试图直接学习从输入到输出参数化的映射函数(或特征提取函数)。去噪自动编码器(Denoising Autoencoder,DAE)是自动编码器的一种随机扩展,它的目标是从有噪声的输入数据中重构原始输入,从而实现更鲁棒的特征学习。
多个自动编码器啊可以组成叠加自动编码器(Stacked Autoencoder),并利用深度学习的思想进行训练。
下图左侧为自动编码器,右侧是去噪自动编码器。
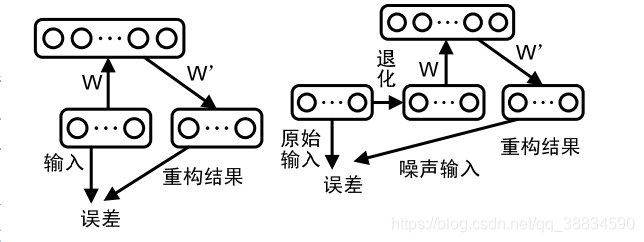
大规模训练方法
前文提到,深度模型的训练过程包括:1)通过无监督学习对每一层网络进行初始化,并将其训练结果作为高一层网络的输入;2)通过监督学习微调整个网络的参数。其中,第一步的初始化是深度学习能取得出色效果的重要因素。深度学习中的优化主要是基于随机梯度下降(Stochastic Gradient Decent,SGD)方法,其参数更新仅在单个训练样本或者一小部分训练样本上进行。虽然随机梯度与传统方法更适用于大规模训练数据,但是这种顺序优化的思想增加了并行化的困难,成为该方法在时间效率上面临的最大瓶颈。
深度学习多数建立在“大数据+复杂模型”的基础上,为了取得更高性能和效率,发掘更复杂的高层次特征,必须提高深度学习方法的可扩展性。目前训练大规模深度模型主要依赖大量的CPU核以及类似云计算的方法,以Jeff Dean和吴恩达为首的研究人员为了训练具有1B参数的大规模深度模型,采用了稀疏、局部感受区域、汇聚(pooling)和局部对比正则化(local contrast normalization)方法,以及模型并行化和异步随机梯度下降(Asynchronous SGD)方法,最近,Coates等人提出基于现成商品高性能计算(Commodity Off-The-Shelf High Performance Computing,COTS HPC)技术的深度学习系统,该系统由无限宽带互联的服务器群组成,训练1B参数仅需3台机器,而且能够扩展到更大的网络规模。
Part 5 深度学习的应用
计算机视觉
在计算机视觉领域深度学习主要应用在数据降维、手写数字识别、模式识别等领域,例如图像识别、图像去噪和修复、运动建模、动作识别、物体跟踪、视觉建模、场景分析等,展现出非常高的有效性。
语音识别
互联网行为分析、文本分析、市场监测、自动控制等。
Part 6 总结与展望
深度学习模拟人脑神经系统构建深层神经网络模型,通过无监督的方式从大量数据中学
习层级特征,在计算机视觉、语音识别等领域取得了巨大的成功。可以说,深度学习让我们
向真正的智能机时代迈进了一步。
基于已有的工作和思考,我们对于深度学习尚未解决的问题和未来的研究方向的看法概
括如下:
- 深度学习尚缺少统计学习理论的有力支持,模型的可表示性、可学习性以及可并行
计算性等基础理论问题有待于深入研究。 - 即使是庞大复杂的深度神经网络,距离模拟真实人脑还差得非常远。我们无法完全
掌握人类大脑的工作原理,但是深度学习的成功使得研究者们更加关注脑神经科学
的研究,相关的研究项目如雨后春笋般涌现,“大神经科学时代”(Era of Big
Neuroscience)已经到来。 - 深度模型对动态数据建模的成效非常有限,其描述时间序列数据动态特性的能力有
待研究。 - 深度学习在模型训练、观测和解释方面需要进一步的工作,例如中间结果的控制、
多层同时训练的方法、深度生成式模型更好的采样方法、模型的解释方法等。 - 传统浅层学习方法的深度扩展是个值得关注的问题。在大数据时代,深度学习可能
并非唯一的选择。一些传统的机器学习方法如何借鉴深度学习的思想解决大数据智
能分析问题,也值得研究。 - 深度模型在特征共享的层面实现了多任务学习的机制,即多个任务之间共享或部分
共享较低层的特征表示,而不同的任务对应的高层特征表示各不相同。我们期望未
来有更高效的多任务深度学习方法和成功的应用出现。














 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









