






关于爬取吉他堂的吉他谱----Python爬虫
吉他爱好者大多数会在一些吉他谱的网站找自己喜欢的歌曲吉他谱或者自己想学的歌的吉他谱,今天我也趁着学校布置的作业,自己为自己或者为一些经常在网站上找吉他谱的吉他爱好者写了一个关于爬取 吉他堂中的吉他谱,如果你是大面积的获取歌曲的吉他谱,这个爬虫一定会为我们节省了很多不必要浪费的时间。第一次写博客~可能写的不是很好,请多多指教!
1. 功能过程的介绍
随便在吉他堂打开一首歌的地址
比如地址为:https://www.jitatang.com/tianfen.html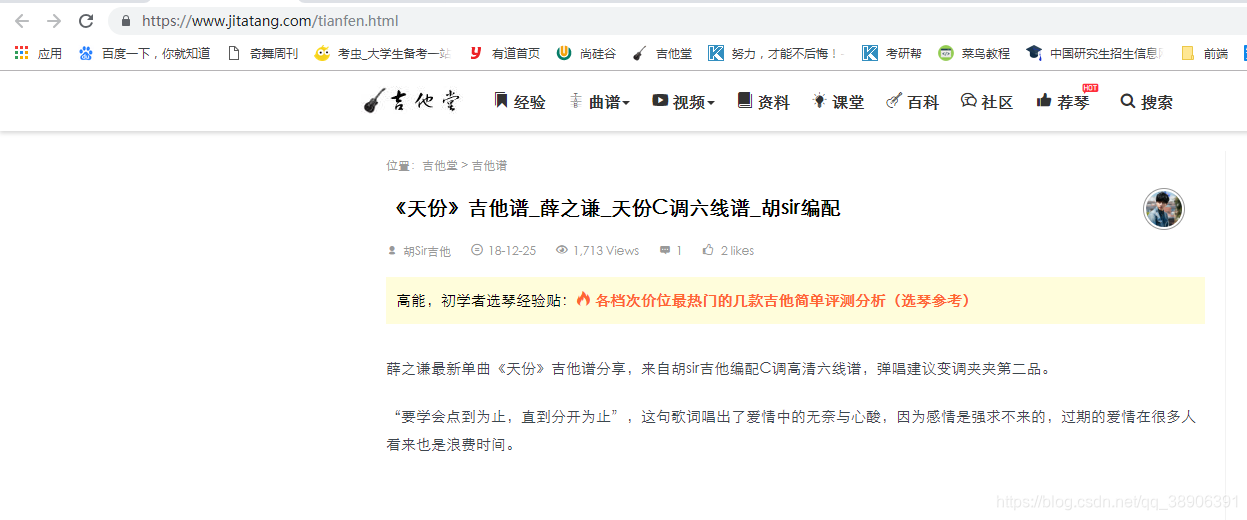
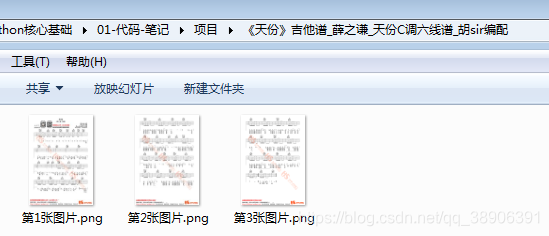
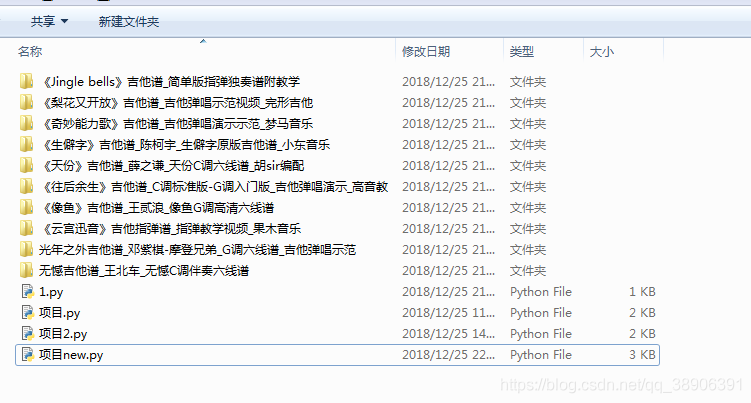
得到这个网站的相应吉他谱图片

通过爬虫代码,得到了相应的图片
2.代码介绍
在实现这过程中我一共创建了5个方法。
mkdir 方法创建相应吉他谱的文件夹
// An highlighted block
def mkdir(path):
folder = os.path.exists(path)
if not folder:
os.makedirs(path)
else:
pass
getUrl 方法得到在吉他堂主界面下面的每首歌的吉他谱地址
// An highlighted block
def getUrl(url):
page = requests.get(url)
html = page.text
soup = BeautifulSoup(html,"html.parser")
data = soup.find_all("div", attrs={'class':'post_loop4_thumb'})
for i in range(len(data)):
url = str(data[i].find_all("a")[0].get('href'))
print(url,"开始读取...")
driver = webdriver.Chrome()
driver.get(url)
getImg(driver.page_source)
print(url,"读取完毕...")
driver.close()
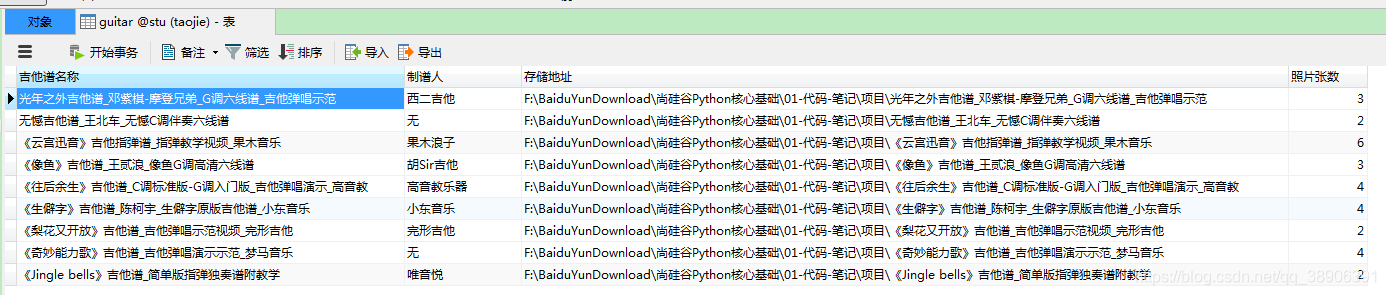
mysql 方法实现了通过爬取得到的吉他谱信息存入相应的数据中
// An highlighted block
def mysql():
mycursor = mydb.cursor()
sql = "CREATE TABLE if not exists guitar (吉他谱名称 VARCHAR(255),制谱人 VARCHAR(255),存储地址 VARCHAR(500), 照片张数 int(12))"
mycursor.execute(sql)
sql = "insert into guitar (吉他谱名称,制谱人,存储地址,照片张数) values (%s,%s,%s,%s)"
mycursor.executemany(sql, guitarlist)
mydb.commit()
getImg 方法通过传入每首歌的吉他谱地址进行相应的判断,从而在相应的文件夹中下载吉他谱图片
// An highlighted block
def getImg(url):
soup = BeautifulSoup(url,"html.parser")
data = soup.find_all("div", attrs={'class':'single_content'})
if len(data) > 0:
a = ()
data1 = soup.find_all("h1", attrs={'class':'single_title'})
data2 = soup.find_all("div", attrs={'class':'sialtext_author'})
title = str(data1[0].string)
if len(data2[0].find_all("a")) == 1:
author = str(data2[0].find_all("a")[0].string)
else:
author = '无'
title = title.replace('/','-')
path = os.getcwd()+'\\'+title
a = a + (title,) + (author,) + (path,)
mkdir(title)
path = title +"/"
p = data[0].find_all("p")
count = 0
for i in range(len(p)):
if len(p[i].find_all("img")) > 0:
count = count + 1
file_name = path+'第'+str(count)+'张图片.png'
print('准备爬取第',count,'张.png')
url2 = p[i].find_all("img")[0].get('src')
print(url2)
page = requests.get(url2)
if page.status_code == 200:
with open(file_name,"wb") as fw:
fw.write(page.content)
print(file_name,'已完成')
a = a + (count,)
guitarlist.append(a)
else:
print("未找到图片!")
main 方法 传入吉他堂的地址执行相应的方法
// An highlighted block
def main():
getUrl('https://www.jitatang.com')
mysql()
3.源代码
// An highlighted block
import requests
import re
import os
import mysql.connector
from selenium import webdriver
from bs4 import BeautifulSoup
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database="stu",
port="3306",
charset="utf8"
)
guitarlist=[]
def mkdir(path):
folder = os.path.exists(path)
if not folder:
os.makedirs(path)
else:
pass
def getImg(url):
soup = BeautifulSoup(url,"html.parser")
data = soup.find_all("div", attrs={'class':'single_content'})
if len(data) > 0:
a = ()
data1 = soup.find_all("h1", attrs={'class':'single_title'})
data2 = soup.find_all("div", attrs={'class':'sialtext_author'})
title = str(data1[0].string)
if len(data2[0].find_all("a")) == 1:
author = str(data2[0].find_all("a")[0].string)
else:
author = '无'
title = title.replace('/','-')
path = os.getcwd()+'\\'+title
a = a + (title,) + (author,) + (path,)
mkdir(title)
path = title +"/"
p = data[0].find_all("p")
count = 0
for i in range(len(p)):
if len(p[i].find_all("img")) > 0:
count = count + 1
file_name = path+'第'+str(count)+'张图片.png'
print('准备爬取第',count,'张.png')
url2 = p[i].find_all("img")[0].get('src')
print(url2)
page = requests.get(url2)
if page.status_code == 200:
with open(file_name,"wb") as fw:
fw.write(page.content)
print(file_name,'已完成')
a = a + (count,)
guitarlist.append(a)
else:
print("未找到图片!")
def getUrl(url):
page = requests.get(url)
html = page.text
soup = BeautifulSoup(html,"html.parser")
data = soup.find_all("div", attrs={'class':'post_loop4_thumb'})
for i in range(len(data)):
url = str(data[i].find_all("a")[0].get('href'))
print(url,"开始读取...")
driver = webdriver.Chrome()
driver.get(url)
getImg(driver.page_source)
print(url,"读取完毕...")
driver.close()
def mysql():
mycursor = mydb.cursor()
sql = "CREATE TABLE if not exists guitar (吉他谱名称 VARCHAR(255),制谱人 VARCHAR(255),存储地址 VARCHAR(500), 照片张数 int(12))"
mycursor.execute(sql)
sql = "insert into guitar (吉他谱名称,制谱人,存储地址,照片张数) values (%s,%s,%s,%s)"
mycursor.executemany(sql, guitarlist)
mydb.commit()
def main():
getUrl('https://www.jitatang.com')
mysql()
main()
# print(guitarlist)
input("已经处理完毕!输入任何字符及可退出~~")
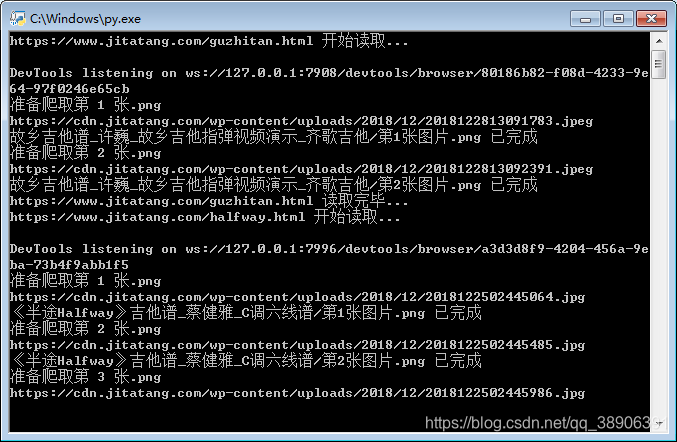
4.运行结果展示















 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









