







LSnet:Location-Sensitive Visual Recognition with Cross-IOU Loss主要源码解读 1
写在前面
照例。每次写博文的时候来个介绍。LSnet是目标检测中基于anchor-free的检测方法。单单读论文并不能领悟其中一些特定的代码设计之巧妙。遂写下这篇博文以记之~
论文链接: Location-Sensitive Visual Recognition with Cross-IOU Loss
代码链接: Github
一、框架搭建
主体代码采用mmdection开源目标检测模型实现。
这里不去细讲,建议掌握一些开源模型的使用方法以备后用。(例如,dectron2这种)。
同样,CSDN上面也有很多博主关于mmdection的解读,建议了解一下,在很大程度上会减少阅读障碍。
其中最需要注意的地方,全框架通篇采用了Registry注册器,也就是一种装饰器,效果类似于全局变量,全局调用,这个Registry源于registry类,不只是在mmdection中,其他类似的框架中也用到了这种全局调用的方法,主要作用就是方便各种模块的搭建。
模块主体示意图:
其中,Backbone可以是Resnet、Res2net、ResnetXt等结构,neck典型例如FPN、RPN等。
Backbone和neck结构相对固定,没有太多选择(大神当我没说,重新设计个Backbone一样顶呱呱)。最主要就是Head的设计了,对于目标检测来说,输出目标矩形框坐标;语义分割和实力分割:输出多个目标点的坐标;类似的还有姿态估计,道理同样如此。
二、网络主体解读
1、extrace_features
本篇论文LSnet最佳实验则是采用了Res2Net101+FPN的结构。这样就把前期的extrace_features定了下来。主要代码在lscpvnet.py(目标检测用)和lsnet.py(目标检测+语义分割+姿态估计共用)
这两个文件中。
2、lsnet.py解读
主要包含的类及内部函数:
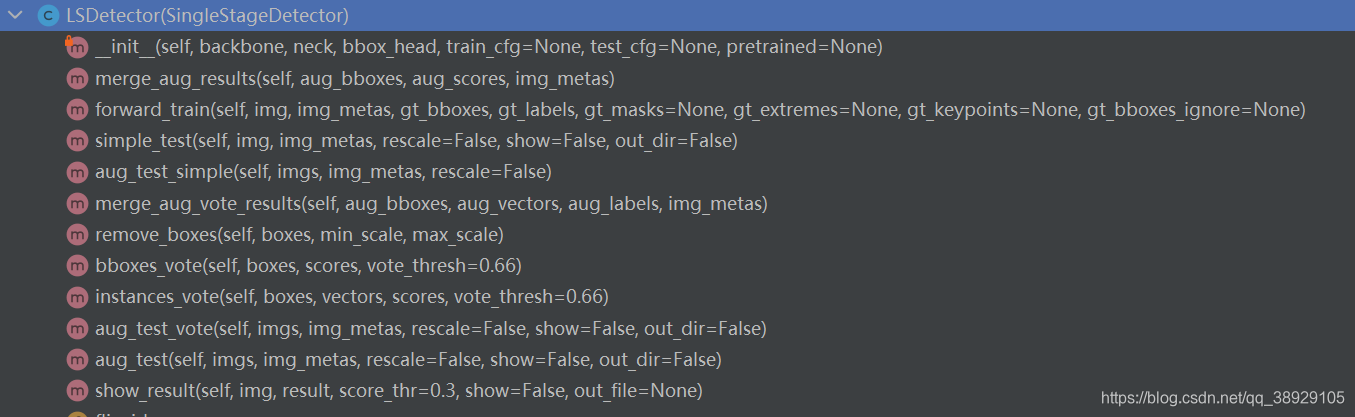
构造函数:
@DETECTORS.register_module()
# 将LSCPVDetector类对象作为Registry类的实例化对象DETECTORS
# 中register_module方法的参数传入
class LSCPVDetector(SingleStageDetector):
def __init__(self,
backbone,
neck,
bbox_head,
train_cfg=None,
test_cfg=None,
pretrained=None):
super(LSCPVDetector, self).__init__(backbone, neck, bbox_head, train_cfg,
test_cfg, pretrained)
# 调用LSCPVDetector的父类构造函数
其中,最重要的是训练过程中的 foward_train,测试时用到的 simple_test 以及可视化时的 show_result 这三个函数。
2.1 forward_train 函数
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_masks = None,
gt_extremes = None,
gt_keypoints = None,
gt_bboxes_ignore=None):
x = self.extract_feat(img) # 这个和之前一样的套路 img -> |backbone+neck| -> base_feature
# 将特征和标签传入,求损失值
losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes, gt_extremes, gt_keypoints,
gt_masks, gt_labels, gt_bboxes_ignore)
return losses
2.2 simple_test 函数
def simple_test(self, img, img_metas, rescale=False, show=False, out_dir=False):
x = self.extract_feat(img) # 这个和之前一样的套路 img -> |backbone+neck| -> base_feature
outs = self.bbox_head(x) # 传入 lsnet_head的 forward部分 得到第二阶段的输出
bbox_list = self.bbox_head.get_bboxes( # 根据输出 产生 bbox 的条件
*outs, img_metas, rescale=rescale)
if self.bbox_head.task == 'bbox':
bbox_results = [
bbox_extreme2result(det_bboxes, det_extremes, det_labels, self.bbox_head.num_classes)
for det_bboxes, det_extremes, det_labels in bbox_list
]
elif self.bbox_head.task == 'segm':
bbox_results = [ # 得出矩形框
bbox_poly2result(det_bboxes, det_polygons, det_labels,
self.bbox_head.num_classes,
self.bbox_head.num_vectors)
for det_bboxes, det_polygons, det_labels in bbox_list
]
elif self.bbox_head.task == 'pose_bbox' or self.bbox_head.task == 'pose_kbox':
if show or out_dir:
bbox_results = [
bbox_poly2result(det_bboxes, det_kps, det_labels,
self.bbox_head.num_classes,
self.bbox_head.num_vectors)
for det_bboxes, det_kps, det_labels in bbox_list
]
else:
for det_bboxes, det_kps, det_labels in bbox_list:
bbox_w, bbox_h = det_bboxes[:, 2] - det_bboxes[:, 0], det_bboxes[:, 3] - det_bboxes[:, 1]
areas = bbox_w*bbox_h
pos_inds = areas > 1024
det_bboxes = det_bboxes[pos_inds]
det_kps = det_kps[pos_inds]
det_labels = det_labels[pos_inds]
bbox_results = [
bbox_poly2result(det_bboxes, det_kps, det_labels,
self.bbox_head.num_classes,
self.bbox_head.num_vectors)
]
return bbox_results[0]
2.3 show_result 函数
def show_result(self,
img,
result,
score_thr=0.3,
show=False,
out_file=None):
img = mmcv.imread(img) # 读入数据集或本地图片
img = img.copy() # 复制
bbox_result, vector_result = result[0], result[1]
bboxes = np.vstack(bbox_result) # 按垂直方向(行顺序)堆叠数组构成一个新的数组
vectors = np.vstack(vector_result) # 按垂直方向(行顺序)堆叠数组构成一个新的数组
labels = [
np.full(bbox.shape[0], i, dtype=np.int32)
for i, bbox in enumerate(bbox_result)
] # 初步标签赋值
labels = np.concatenate(labels)
# if out_file specified, do not show image in window
if show: # 这句话不管用,
warnings.warn('show is not supported, please use show-dir')
return img
if self.bbox_head.task == 'bbox':
mmcv.imshow_extremes(img, bboxes, vectors, labels, class_names=self.CLASSES,
score_thr=score_thr, out_file=out_file)
elif self.bbox_head.task == 'segm': # 绘制多边形
mmcv.imshow_polygons(img, bboxes, vectors, labels, class_names=self.CLASSES,
score_thr=score_thr, out_file=out_file)
elif 'pose' in self.bbox_head.task:
mmcv.imshow_pose(img, bboxes, vectors, labels, class_names=self.CLASSES,
3、lscpvnet.py解读
还是和上面那个lsnet.py类似,不过这里只有两个函数,并无可视化相关的函数。
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
gt_sem_map=None,
gt_sem_weights=None,
gt_extremes=None): # 重写父类的 forward_train的方法
x = self.extract_feat(img) # img -> |backbone+neck| -> base_feature
outs = self.bbox_head(x)
loss_inputs = outs + (gt_bboxes, gt_extremes, gt_sem_map, gt_sem_weights, gt_labels, img_metas)
losses = self.bbox_head.loss(
*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
return losses
def simple_test(self, img, img_metas, rescale=False, show=False, out_dir=False):
"""Test function without test time augmentation
Args:
imgs (list[torch.Tensor]): List of multiple images
img_metas (list[dict]): List of image information.
rescale (bool, optional): Whether to rescale the results.
Defaults to False.
Returns:
np.ndarray: proposals
"""
x = self.extract_feat(img)
outs = self.bbox_head(x)
bbox_list = self.bbox_head.get_bboxes(
*outs, img_metas, rescale=rescale)
# 根据极值点 取出对应的bbox
bbox_results = [
bbox2result(det_bboxes, det_labels, self.bbox_head.num_classes)
for det_bboxes, det_labels in bbox_list
]
return bbox_results[0]
未完待续
下一篇:lsnet_head.py文件,敬请期待~















 1590
1590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











