







加载数据
import pandas as pd import numpy as np users = pd.read_excel('./users.xlsx')
groupby指定分组的列可以是单列,也可以是多列
根据班级分组,统计学员的班级的平均年龄
res = users.groupby(by='ORGANIZE_NAME')['age'].mean()
按照ORGANIZE_NAME分组,再按照poo分组,统计学员的班级的平均年龄
res = users.groupby(by=['ORGANIZE_NAME','poo'])['age'].mean()
统计age和USER_ID的均值
res = users.groupby(by=['ORGANIZE_NAME','poo'])[['age','USER_ID']].mean()
agg进行聚合运算
利用agg同时对age求平均值,对USER_ID求最大值
#只需要指定,np.方法名。 print(users.agg({'age':np.mean,'USER_ID':np.max}))
对多个列,进行多个统计方法统计
print(users[['age','USER_ID']].agg([np.mean,np.max]))
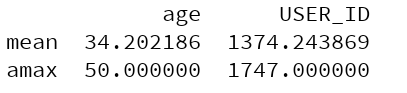
对age求sum,对USER_ID求mean和sum
print(users.agg({'age':np.sum,'USER_ID':[np.mean,np.sum]}))

自定义函数进行计算
apply的使用:给age这列的数值加一
res = users['age'].apply(lambda x:x+1) print(res)def hh(x): return x+1 res = users['age'].apply(hh) print(res)transform的使用:给age这列的数值加一
res = users['age'].transform(lambda x:x+1) print(res)transform的使用:age列+1,USER_ID列加1
res = users[['age','USER_ID']].transform(lambda x:x+1) print(res)注:不能进行跨列计算














 992
992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









