







一.groupingBy()的源码
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream)
三个参数
第一个参数:分组按照什么分类
第二个参数:分组最后用什么容器保存返回(默认是HashMap::new)
第三个参数:按照第一个参数分类后,对应的分类的结果如何收集(默认是Collectors.toList)
二、分别用HashMap,LinkedHashMap,TreeMap来存储分组后的数据
1.例子
@Test
public void groupBy(){
ResultDTO<List<PackageProcessFailRecordDTO>> listResultDTO = packageProcessFailRecordQueryService.queryByParam(PackageProcessFailRecordQueryRequest.builder()
.status(CommonStatusEnum.NOT_EFFECTIVE.getIndex())
.retryTimes(Sets.newHashSet(0, 1, 2))
.build());
List<PackageProcessFailRecordDTO> packageProcessFailRecordDTOs = listResultDTO.getModel();
Map<Integer, List<PackageProcessFailRecordDTO>> listMap2 = packageProcessFailRecordDTOs.stream().collect(Collectors.groupingBy(o -> o.getOperationType()));
for (Map.Entry<Integer, List<PackageProcessFailRecordDTO>> entry : listMap2.entrySet()) {
log.info("----hashMap------" + entry.getKey());
}
Map<Integer, List<PackageProcessFailRecordDTO>> listMap = packageProcessFailRecordDTOs.stream().collect(Collectors.groupingBy(o -> o.getOperationType(), LinkedHashMap::new,Collectors.toList()));
for (Map.Entry<Integer, List<PackageProcessFailRecordDTO>> entry : listMap.entrySet()) {
log.info("======LinkedHashMap======" + entry.getKey());
}
Map<Integer, List<PackageProcessFailRecordDTO>> listMap1 = packageProcessFailRecordDTOs.stream().collect(Collectors.groupingBy(o -> o.getOperationType(), TreeMap::new,Collectors.toList()));
for (Map.Entry<Integer, List<PackageProcessFailRecordDTO>> entry : listMap1.entrySet()) {
log.info("------TreeMap-----" + entry.getKey());
}
}
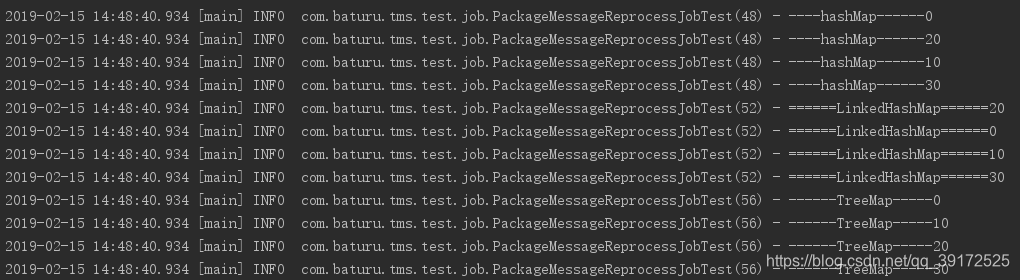
2.结果:
3.数据库的数据:

4.分析:
1.HashMap是无序的,HashMap在put的时候是根据key的hashcode进行hash然后放入对应的地方,所以在按照一定顺序put进HashMap中,然后遍历出HashMap的顺序跟put的顺序不同
2.LinkedHashMap实现了有序的HashMap,LinkedHashMap取键值对时,是按照你放入的顺序来取的(也就是sql查询出的顺序)
3.TreeMap是有序的,如果key是数值类型,默认升序,如果key为string或者对象,需要自己实现比较器
三、总结
使用Collectors.groupingBy(o -> o.getOperationType(), TreeMap::new,Collectors.toList())可以实现分组后的排序问题。也可以使用LinkedHashMap,前提是在sql查询时对key做好排序。














 7027
7027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









