







朴素贝叶斯算法(Navie Bayes)
概率定义
概率定义为一件事情发生的可能性 , 扔出一个硬币,结果头像朝上, P(X) : 取值在[0, 1]
案例:判断女神对你的喜欢情况
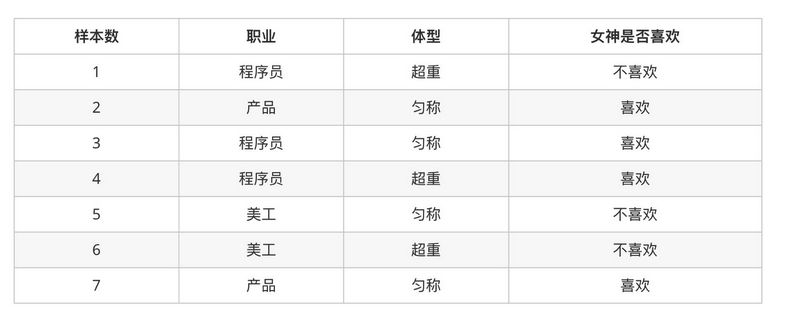
问题如下:
被女神喜欢的概率?
职业是程序员并且体型匀称的被女神喜欢概率?
在女神喜欢的条件下,职业是程序员的概率?
在女神喜欢的条件下,职业是程序员、体重超重的概率?
计算结果为:
P(喜欢) = 4/7
P(程序员, 匀称) = 1/7(联合概率)
P(程序员|喜欢) = 2/4 = 1/2(条件概率)
P(程序员, 超重|喜欢) = 1/4
联合概率、条件概率与相互独立
联合概率:包含多个条件,且所有条件同时成立的概率
记作:P(A,B)
条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
记作:P(A|B)
相互独立:如果P(A, B) = P(A)P(B),则称事件A与事件B相互独立。
贝叶斯公式
公式介绍

案例计算
那么思考题就可以套用贝叶斯公式这样来解决:
P(喜欢|产品, 超重) = P(产品, 超重|喜欢)P(喜欢)/P(产品, 超重)
上式中,
- P(产品, 超重|喜欢)和P(产品, 超重)的结果均为0,导致无法计算结果。这是因为我们的样本量太少了,不具有代表性。
本来现实生活中,肯定是存在职业是产品经理并且体重超重的人的,P(产品, 超重)不可能为0;而且事件“职业是产品经理”和事件“体重超重”通常被认为是相互独立的事件,但是,根据我们有限的7个样本计算“P(产品, 超重) = P(产品)P(超重)”不成立
而朴素贝叶斯可以帮助我们解决这个问题。
- 朴素贝叶斯,简单理解,就是假定了
特征与特征之间相互独立的贝叶斯公式。 - 也就是说,朴素贝叶斯,之所以朴素,就在于假定了特征与特征相互独立。
所以,思考题如果按照朴素贝叶斯的思路来解决,就可以是
P(产品, 超重) = P(产品) * P(超重) = 2/7 * 3/7 = 6/49
p(产品, 超重|喜欢) = P(产品|喜欢) * P(超重|喜欢) = 1/2 * 1/4 = 1/8
P(喜欢|产品, 超重) = P(产品, 超重|喜欢)P(喜欢)/P(产品, 超重) = 1/8 * 4/7 / 6/49 = 7/12
那么这个公式如果应用在文章分类的场景当中,我们可以这样看:

公式分为三个部分:
- P©:每个文档类别的概率(某文档类别数/总文档数量)
P(W│C):给定类别下特征(被预测文档中出现的词)的概率 计算方法:P(F1│C)=Ni/N (训练文档中去计算)Ni为该F1词在C类别所有文档中出现的次数N为所属类别C下的文档所有词出现的次数和
P(F1,F2,…) 预测文档中每个词的概率, 如果计算两个类别概率比较:所以我们只要比较前面的大小就可以,得出谁的概率大
文章分类计算
需求:通过前四个训练样本(文章),判断第五篇文章,是否属于China类

计算结果:
P(C|Chinese, Chinese, Chinese, Tokyo, Japan) -->
P(Chinese, Chinese, Chinese, Tokyo, Japan|C) * P(C) / P(Chinese, Chinese, Chinese, Tokyo, Japan)
=
P(Chinese|C)^3 * P(Tokyo|C) * P(Japan|C) * P(C) / [P(Chinese)^3 * P(Tokyo) * P(Japan)]
# 这个文章是需要计算是不是China类,是或者不是最后的分母值都相同:
# 首先计算是China类的概率:
P(Chinese|C) = 5/8
P(Tokyo|C) = 0/8
P(Japan|C) = 0/8
# 接着计算不是China类的概率:
P(Chinese|C) = 1/3
P(Tokyo|C) = 1/3
P(Japan|C) = 1/3

# 这个文章是需要计算是不是China类:
首先计算是China类的概率: 0.0003
P(Chinese|C) = 5/8 --> 6/14
P(Tokyo|C) = 0/8 --> 1/14
P(Japan|C) = 0/8 --> 1/14
接着计算不是China类的概率: 0.0001
P(Chinese|C) = 1/3 -->(经过拉普拉斯平滑系数处理) 2/9
P(Tokyo|C) = 1/3 --> 2/9
P(Japan|C) = 1/3 --> 2/9
朴素贝叶斯优缺点
优点:
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率
对缺失数据不太敏感,算法也比较简单,常用于文本分类
分类准确度高,速度快
缺点:
由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好
需要计算先验概率,而先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳;
图书商品评论情感分析
应用朴素贝叶斯API实现商品评论情感分析
api介绍
- sklearn.naive_bayes.MultinomialNB(alpha = 1.0) 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
- MultinomialNB多项式之外,还有GaussianNB就是先验为高斯分布的朴素贝叶斯,BernoulliNB就是先验为伯努利分布的朴素贝叶斯
import pandas as pd
import numpy as np
import jieba
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
1)获取数据
data = pd.read_csv("书籍评价.csv", encoding='gbk')
data.head()
| Unnamed: 0 | 内容 | 评价 | |
|---|---|---|---|
| 0 | 0 | 从编程小白的角度看,入门极佳。 | 好评 |
| 1 | 1 | 很好的入门书,简洁全面,适合小白。 | 好评 |
| 2 | 2 | 讲解全面,许多小细节都有顾及,三个小项目受益匪浅。 | 好评 |
| 3 | 3 | 前半部分讲概念深入浅出,要言不烦,很赞 | 好评 |
| 4 | 4 | 看了一遍还是不会写,有个概念而已 | 差评 |
2)数据基本处理
2.1) 取出内容列,对数据进行分析
content = data['内容']
content[:3]
0 从编程小白的角度看,入门极佳。
1 很好的入门书,简洁全面,适合小白。
2 讲解全面,许多小细节都有顾及,三个小项目受益匪浅。
Name: 内容, dtype: object
2.2) 判定评判标准
## 把评价好坏转换成数字 直接原地操作
# data.loc[:, '评价'] == "好评"
data.loc[data.loc[:, '评价'] == "好评", "评论编号"] = 1
data.head()
| Unnamed: 0 | 内容 | 评价 | 评论编号 | |
|---|---|---|---|---|
| 0 | 0 | 从编程小白的角度看,入门极佳。 | 好评 | 1.0 |
| 1 | 1 | 很好的入门书,简洁全面,适合小白。 | 好评 | 1.0 |
| 2 | 2 | 讲解全面,许多小细节都有顾及,三个小项目受益匪浅。 | 好评 | 1.0 |
| 3 | 3 | 前半部分讲概念深入浅出,要言不烦,很赞 | 好评 | 1.0 |
| 4 | 4 | 看了一遍还是不会写,有个概念而已 | 差评 | NaN |
data.loc[data.loc[:, '评价'] == "差评", "评论编号"] = 0
data.head()
| Unnamed: 0 | 内容 | 评价 | 评论编号 | |
|---|---|---|---|---|
| 0 | 0 | 从编程小白的角度看,入门极佳。 | 好评 | 1.0 |
| 1 | 1 | 很好的入门书,简洁全面,适合小白。 | 好评 | 1.0 |
| 2 | 2 | 讲解全面,许多小细节都有顾及,三个小项目受益匪浅。 | 好评 | 1.0 |
| 3 | 3 | 前半部分讲概念深入浅出,要言不烦,很赞 | 好评 | 1.0 |
| 4 | 4 | 看了一遍还是不会写,有个概念而已 | 差评 | 0.0 |
2.3) 选择停用词
stopwords = []
with open("./stopwords.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
for temp in lines:
line = temp.strip()
stopwords.append(line)
# 去重
stopwords = list(set(stopwords))
stopwords[:5]
['', '[①f]', '不仅', '起首', './']
2.4) 把内容处理,转化成标准格式
comment_list = []
for temp in content:
# print(temp)
seg_list = jieba.lcut(temp, cut_all= False) # 是否采用全模式
sge_str = ",".join(seg_list)
comment_list.append(sge_str)
comment_list[:3]
[' ,从,编程,小白,的,角度看,,,入门,极佳,。',
'很,好,的,入门,书,,,简洁,全面,,,适合,小白,。',
'讲解,全面,,,许多,小,细节,都,有,顾及,,,三个,小,项目,受益匪浅,。']
2.5) 统计词的个数
con = CountVectorizer(stop_words=stopwords)
X = con.fit_transform(comment_list)
X.toarray()[:4]
array([[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0,
1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]])
con.get_feature_names()[:5]
['一本', '一遍', '三个', '中规中矩', '依旧']
2.6)准备训练集和测试集
X_train = X.toarray()[:10, :]
y_train = data["评价"][:10]
X_test = X.toarray()[10:, :]
y_test = data["评价"][10:]
3)模型训练
mnb = MultinomialNB(alpha=1)
mnb.fit(X_train, y_train)
y_pred = mnb.predict(X_test)
y_pred
array(['差评', '差评', '差评'], dtype='<U2')
y_test
10 差评
11 差评
12 差评
Name: 评价, dtype: object
4)模型评估
mnb.score(X_test, y_test)
1.0















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









