






GPU并行计算OpenCL(2)——矩阵卷积
我们完成了helloworld之后,会感慨一个helloworld就要2-3百行代码。但由于OpenCL需要完成一系列启用GPU并行计算的过程,所以我们之后许多编码会和helloworld十分类似。比如这次,我们将实现非常常见的功能,矩阵的卷积计算,该功能便可以体会到GPU并行计算的强大之处了。
我们这次我们将输入信号作为一个矩阵,完成对信号的卷积,我们的例子就是将3*3的卷积核应用到8*8的输入信号矩阵中。然后获取一个6*6的矩阵。完成过程如下图:
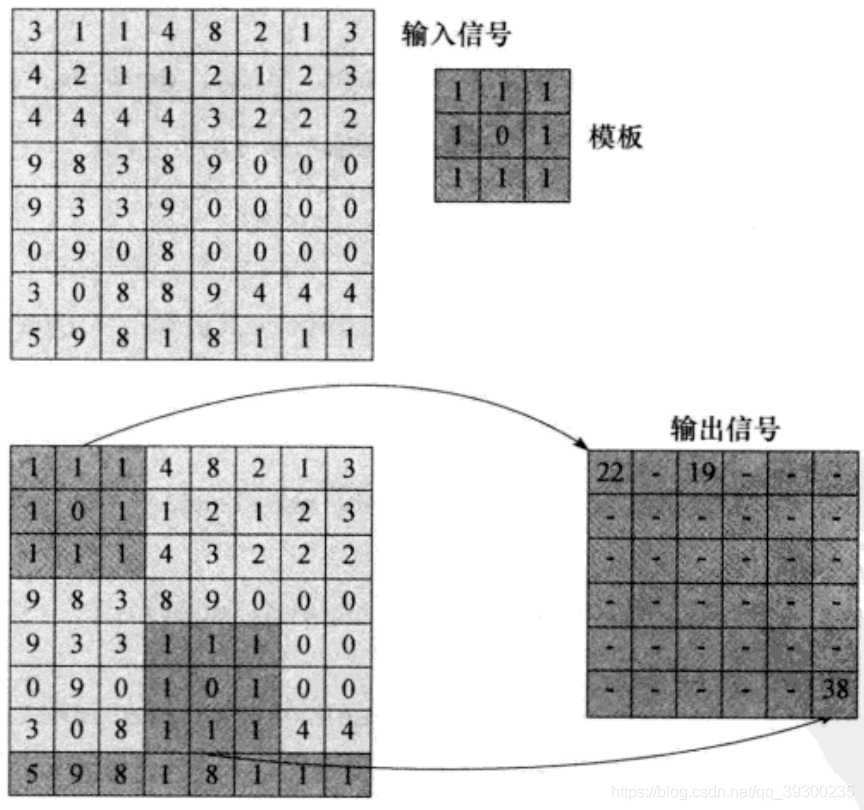
该算法非常简单,步骤为:
1)将模版置于输入信号上。
2)将输入值与模版中的相应元素相乘。
3)将第二步的结果累加为一个和,写至相应的输出位置。
因此我们的.cl内核代码为:
__kernel void convolve(const __global uint *const input,
__constant uint* const mask,
__global float *const output,
const int inputWidth,
const int maskWidth){
const int x=get_global_id(0);
const int y=get_global_id(1);
uint sum=0;
for(int r=0;r<maskWidth;r++){
const int idxIntpm=(y+r)*inputWidth+x;
for(int c=0;c<maskWidth;c++){
sum+=mask[(r*maskWidth)+c]*input[idxIntpm+c];
}
}
output[y*get_global_size(0)+x]=sum;
}
这里的x,y为我们在并行计算的时候,获取的全局索引。其中get_global_id(i),表示获取第i维中当前的索引。下面的sum则为卷积的每个项的结果。(这里注意的是:虽然这里用y去获取第二维的索引,但我们的代码最后还是通过一维实现的,所以所有的y获得的都是0,x为0-35)。
接下来就是我们的宿主机代码(.cpp文件)了。这里的代码流程是与helloworld基本一致的。
1)创建上下文,创建上下文代码:
cl_context CreatContext(){
cl_int errNum;
cl_uint numPlatforms;
cl_platform_id firstPlatformID;
cl_context context=nullptr;
/*首先,选择要运行的OpenCL平台。 对于这个例子,我们
只需选择第一个可用平台。通常,我们也可以
查询所有可用平台,然后选择最合适的平台。
*/
errNum=clGetPlatformIDs(1, &firstPlatformID, &numPlatforms);
if (errNum != CL_SUCCESS || numPlatforms <= 0)
{
std::cerr << "Failed to find any OpenCL platforms." << std::endl;
return NULL;
}
/*接下来,在平台上创建一个OpenCL上下文。 尝试
创建基于GPU的上下文,如果失败,请尝试创建
基于CPU的上下文。
*/
//创建上下文需要的资源 属性 属性值 0结束
cl_context_properties contextProperties[]={
CL_CONTEXT_PLATFORM,
(cl_context_properties)firstPlatformID,
0
};
context=clCreateContextFromType(contextProperties, CL_DEVICE_TYPE_GPU, nullptr, nullptr, &errNum);
if (errNum != CL_SUCCESS)
{
std::cout << "Could not create GPU context, trying CPU..." << std::endl;
context = clCreateContextFromType(contextProperties, CL_DEVICE_TYPE_CPU,
NULL, NULL, &errNum);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to create an OpenCL GPU or CPU context." << std::endl;
return NULL;
}
}
return context;
}2)创建命令队列,创建命令队列的函数:
cl_command_queue CreateCommandQueue(cl_context context, cl_device_id *device)
{
cl_int errNum;
cl_device_id *devices;
cl_command_queue commandQueue = NULL;
size_t deviceBufferSize = -1;
// 获取设备缓存的尺寸
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &deviceBufferSize);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed call to clGetContextInfo(...,GL_CONTEXT_DEVICES,...)";
return NULL;
}
if (deviceBufferSize <= 0)
{
std::cerr << "No devices available.";
return NULL;
}
// 给设备缓存分配空间
devices = new cl_device_id[deviceBufferSize / sizeof(cl_device_id)];
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, deviceBufferSize, devices, NULL);
if (errNum != CL_SUCCESS)
{
delete [] devices;
std::cerr << "Failed to get device IDs";
return NULL;
}
// 选择第一个设备和上下文,创建出一个命令队列
commandQueue = clCreateCommandQueue(context, devices[0], 0, NULL);
if (commandQueue == NULL)
{
delete [] devices;
std::cerr << "Failed to create commandQueue for device 0";
return NULL;
}
*device = devices[0];
delete [] devices;
return commandQueue;
}
3)创建程序对象,函数代码:
cl_program CreateProgram(cl_context context, cl_device_id device, const char* fileName)
{
cl_int errNum;
cl_program program;
std::ifstream kernelFile(fileName, std::ios::in);
if (!kernelFile.is_open())
{
std::cerr << "Failed to open file for reading: " << fileName << std::endl;
return NULL;
}
std::ostringstream oss;
oss << kernelFile.rdbuf();//oss输出kernelFile指向的流缓冲
std::string srcStdStr = oss.str();
const char *srcStr = srcStdStr.c_str();
//在context上下文上创建程序对象(字符串个数为1)
program = clCreateProgramWithSource(context, 1,
(const char**)&srcStr,
NULL, NULL);
if (program == NULL)
{
std::cerr << "Failed to create CL program from source." << std::endl;
return NULL;
}
//编译内核源码
errNum = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
if (errNum != CL_SUCCESS)
{
// 输出编译错误信息
char buildLog[16384];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG,
sizeof(buildLog), buildLog, NULL);
std::cerr << "Error in kernel: " << std::endl;
std::cerr << buildLog;
clReleaseProgram(program);//释放程序对象空间
return NULL;
}
return program;
}到这里,我们的代码和helloworld是一致的。我们来看.cpp文件:
#include <iostream>
#include <OpenCL/OpenCL.h>
#include <fstream>
#include <sstream>
//输入矩阵长宽
const unsigned int inputSignalWidth = 8;
const unsigned int inputSignalHeight = 8;
//矩阵值
cl_int inputSignal[inputSignalWidth][inputSignalHeight] =
{
{3, 1, 1, 4, 8, 2, 1, 3},
{4, 2, 1, 1, 2, 1, 2, 3},
{4, 4, 4, 4, 3, 2, 2, 2},
{9, 8, 3, 8, 9, 0, 0, 0},
{9, 3, 3, 9, 0, 0, 0, 0},
{0, 9, 0, 8, 0, 0, 0, 0},
{3, 0, 8, 8, 9, 4, 4, 4},
{5, 9, 8, 1, 8, 1, 1, 1}
};
//输出长宽
const unsigned int outputSignalWidth = 6;
const unsigned int outputSignalHeight = 6;
//输出矩阵值
cl_float outputSignal[outputSignalWidth][outputSignalHeight];
const unsigned int maskWidth = 3;
const unsigned int maskHeight = 3;
cl_int mask[maskWidth][maskHeight] =
{
{1, 1, 1}, {1, 0, 1}, {1, 1, 1},
};
/*
1 选择平台创建OpenCL上下文
2 选择设备创建命令队列
3 加载内核文件(hello_world.cl)并构建到程序对象中
4 为内核函数创建hello_kernel()创建一个内核对象
5 为内核参数创建内存对象(result,a,b)
6 将待执行的内核排队
7 将内核结果读回结果缓冲区
*/
cl_context CreatContext();
cl_command_queue CreateCommandQueue(cl_context context, cl_device_id *device);
cl_program CreateProgram(cl_context context, cl_device_id device, const char* fileName);
bool CreateMemObjects(cl_context context, cl_mem memObjects[3], cl_int (*a)[inputSignalWidth], cl_int (*b)[maskWidth]);
void Cleanup(cl_context context, cl_command_queue commandQueue,cl_program program, cl_kernel kernel, cl_mem memObjects[3]);
int main(int argc, const char * argv[]) {
cl_context context=0;
cl_command_queue commandQueue=0;
cl_program program=0;
cl_device_id device=0;
cl_kernel kernel=0;
cl_mem memObjects[3]={0,0,0};
cl_int errNum;
//创建上下文
context=CreatContext();
if (context == NULL)
{
std::cerr << "Failed to create OpenCL context." << std::endl;
return 1;
}
//创建命令队列
commandQueue=CreateCommandQueue(context, &device);
if (commandQueue == NULL)
{
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
//创建程序对象
program=CreateProgram(context, device, "convolve.cl");
if (program == NULL)
{
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
//创建OpenCL核
kernel=clCreateKernel(program, "convolve", nullptr);
if (kernel == NULL)
{
std::cerr << "Failed to create kernel" << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
//不同
//创建内存对象
if (!CreateMemObjects(context, memObjects, inputSignal, mask))
{
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
//设置内核参数
errNum=clSetKernelArg(kernel, 0, sizeof(cl_mem), &memObjects[0]);
errNum|=clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObjects[1]);
errNum|=clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObjects[2]);
errNum|=clSetKernelArg(kernel, 3, sizeof(cl_uint), &inputSignalWidth);
errNum|=clSetKernelArg(kernel, 4, sizeof(cl_uint), &maskWidth);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error setting kernel arguments." << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
size_t globalWorkSize[1] = { outputSignalWidth * outputSignalHeight };
size_t localWorkSize[1] = { 1 };
//为将在设备上执行的内核排队
errNum=clEnqueueNDRangeKernel(commandQueue, kernel, 1, nullptr, globalWorkSize, localWorkSize, 0, nullptr, nullptr);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error queuing kernel for execution." << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
//执行内核并读出数据
errNum = clEnqueueReadBuffer(commandQueue, memObjects[2], CL_TRUE,
0, outputSignalHeight * outputSignalWidth * sizeof(cl_int), outputSignal,
0, NULL, NULL);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error reading result buffer." << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
// Output the result buffer
for (int i = 0; i < outputSignalHeight; i++)
{
for (int j=0; j<outputSignalWidth; j++) {
std::cout << outputSignal[i][j] << " ";
}
std::cout<<std::endl;
}
std::cout << std::endl;
std::cout << "Executed program succesfully." << std::endl;
Cleanup(context, commandQueue, program, kernel, memObjects);
return 0;
}4)我们创建OpenCL核,然后创建内存对象。我们创建内存对象不同了,因为内存对象是需要我们根据算法合理创建的。创建内存对象以及清空缓存代码为:
bool CreateMemObjects(cl_context context, cl_mem memObjects[3], cl_int (*a)[inputSignalWidth], cl_int (*b)[maskWidth])
{
memObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(cl_int) * inputSignalHeight * inputSignalWidth,
a, NULL);
memObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(cl_int) * maskHeight * maskWidth,
b, NULL);
memObjects[2] = clCreateBuffer(context, CL_MEM_READ_WRITE,
sizeof(cl_float) * outputSignalHeight * outputSignalWidth, NULL, NULL);
if (memObjects[0] == NULL || memObjects[1] == NULL || memObjects[2] == NULL)
{
std::cerr << "Error creating memory objects." << std::endl;
return false;
}
return true;
}
//释放OpenCL资源
void Cleanup(cl_context context, cl_command_queue commandQueue,
cl_program program, cl_kernel kernel, cl_mem memObjects[3])
{
for (int i = 0; i < 3; i++)
{
if (memObjects[i] != 0)
clReleaseMemObject(memObjects[i]);
}
if (commandQueue != 0)
clReleaseCommandQueue(commandQueue);
if (kernel != 0)
clReleaseKernel(kernel);
if (program != 0)
clReleaseProgram(program);
if (context != 0)
clReleaseContext(context);
}这里我们内存对象依旧为3个,分别为输入信号矩阵,卷积核,以及输出矩阵。
5)为内核设置参数以及在设备上为内核排队。该代码:
errNum=clEnqueueNDRangeKernel(commandQueue, kernel, 1, nullptr, globalWorkSize, localWorkSize, 0, nullptr, nullptr);第三个参数正是我们全局工作项的维度,指明为1,则表明我们实际仍是以1维的方式进行计算的。
由于我们的内核有5个参数,因此我们设置参数应该为它们分别设置。为内核排完队,我们就可以成功读出输出矩阵,代码输出如果为:
22 21 27 25 22 16
27 35 35 31 31 27
19 10 29 33 39 43
35 26 16 6 22 31
41 48 31 34 9 0
12 24 26 48 37 38
那我们的GPU计算矩阵卷积就成功了。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









