







Spark内核
所谓的内核,就是Spark内部核心原理。
一、内核解析的分解
- Spark应用的提交
- Spark内部的通信
- Spark作业的调度
- 任务的执行
- spark内存管理
二、 SparkSubmit
--本章节讲述job提交应用以后,环境的准备工作。主要包含以下:
1. spark向yarn提交job的过程
2. yarn中application、driver、executor、container是如何相互响应
- 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploymode cluster \ 表示yarn的集群模式
./examples/jars/spark-examples_2.12-2.4.5.jar \
10
-- 说明:
--master yarn 默认是采用yarn的客户端模式,但是在实际过程中,我们都是使用yarn的集群模式。
所以增加:--deploymode cluster \
2.1 Spark向yarn提交
2.1.1 SparkSubmit
--作用:
1. 解析参数
2. 提交参数,初始数环境,并获取"org.apache.spark.deploy.yarn.YarnClusterApplication"的对象,调用对象的start方法
1. 执行SparkSubmit的mian方法
2. 在main方法中:
1)、 new SparkSubmit
2)、 submit.doSubmit(args) -->执行提交程序,点击doSubmit
①、 val appArgs = parseArguments(args) -->解析参数,解析应用提交的参数,点击parseArguments
a、parse(args.asJava) -->具体进行参数的解析,点击parse,返回参数的解析,方法的内部调用了handle方法
action = Option(action).getOrElse(SUBMIT),-->默认值为submit
b、handle(opt: String, value: String) -->opt:参数的名称,value:参数的值。
左边是参数 => 右边是赋值的变量
// --master yarn => master
// --deploy-mode cluster => deployMode
// --class SparkPI(WordCount) => 【mainClass】
"如上为解析参数"
②、appArgs.action match {case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)-->点击submit
a、submit中又调用了doRunMain(),doRunMain()中调用了runMain()方法
-- runMain(args, uninitLog),运行主程序,在runmain()方法中:
1.准备提交环境
-- val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
2.设定当前类的加载器
-- Thread.currentThread.setContextClassLoader(loader)
3.通过类名加载这个类,'反射的方式'
-- mainClass = Utils.classForName(childMainClass)
4.创建第3步类的实例,并将类型转换为SparkApplication
-- app: SparkApplication = mainClass.newInstance().asInstanceOf[SparkApplication]
childMainClass到底是谁?
cluster模式:childMainClass = YARN_CLUSTER_SUBMIT_CLASS
=org.apache.spark.deploy.yarn.YarnClusterApplication
client模式:childMainClass = args.mainClass=class SparkPI(WordCount)
5.YarnClusterApplication.start
-- app.start(childArgs.toArray, sparkConf)
"如上为提交环境,并启动org.apache.spark.deploy.yarn.YarnClusterApplication"
2.2.2 yarn.YarnClusterApplication
--作用:
1. 调用YarnClusterApplication的start方法,创建yarn的resourcemanagerClient,RM的客户端
2. 执行RM客户端执行run方法
3. 在run方法中,启动一个应用程序application,也就是一个进程,并提交应用程序,则会执行这个进程的main方法。
1. 通过反射调用start()方法,在start()方法中:
-- 1)new Client(new ClientArguments(args), conf).run()
①new ClientArguments(args),是配置参数的封装
②new Client,在client类中的属性有:
--val yarnClient = YarnClient.createYarnClient,点击createYarnClient方法,在这个方法中:
-- YarnClient client = new YarnClientImpl(),点击YarnClientImpl类,在类中有一个属性
rmclient:resourcemanagerClient
-- protected ApplicationClientProtocol rmClient
"如上就是创建RM客户端对象",接下来执行run方法
③run(),RM客户端对象执行run方法,点击run,在run方法的内部:
1. 提交应用,返回应用的id。
-- this.appId = submitApplication(),点击submitApplication(),查看具体提交的过程
1. 初始化hadoop的环境
--yarnClient.init(hadoopConf)
2. 启动yarn客户端,与yarn之间进行连接
-- yarnClient.start()
3. yarn客户端创建一个应用application
--val newApp = yarnClient.createApplication()
4. 获取应用的id,在yarn应用程序中,每一个应用都是有唯一的应用id
-- appId = newAppResponse.getApplicationId()
5. 提交yarn应用程序,提交的是什么呢?
--yarnClient.submitApplication(appContext),点击appContext
--// Set up the appropriate contexts to launch our AM
配置java虚拟机的启动参数,点击createContainerLaunchContext,
在这个方法的内部进行了command的封装:
【集群模式】command = bin/java org.apache.spark.deploy.yarn.ApplicationMaster
【client模式】command = bin/java org.apache.spark.deploy.yarn.ExecutorLauncher
--val containerContext = createContainerLaunchContext(newAppResponse)
基本参数配置的封装
--val appContext = createApplicationSubmissionContext(newApp, containerContext)
2.2.3 yarn.ApplicationMaster
-- 作用
1. 封装ApplicationMaster的参数
2. 根据参数,创建ApplicationMaster对象
3. 执行ApplicationMaster的run方法,在run方法中,最后调用到runDriver方法,在这个方法中:
a、启动用户的应用,并返回这个应用的"线程",具体实现如下:
a、启动用户提交的应用程序;
b、在ApplicationMaster中创建一个线程,线程的名称就是"Driver"
c、启动这个线程,并执行run方法,在run方法中,就是执行我们提交的应用程序类的main方法
d、返回这个"Driver"线程
b、 执行一个方法,用于返回"sparkContext"的对象,如果没有返回,就不会执行下面的代码,当返回了这个上下文的对象以后:
c、 ApplicationMaster通过ApplicationMaste的客户端,向ResourceManager注册自己,并申请资源
d、 分配资源,具体实现如下:
a、在ResourceManager端获取一个ApplicationMaster的客户端,返回一个分配器
b、分配器进行资源的分配:
a、ApplicationMaster的客户端申请一个分配器响应
b、分配器响应返回所有被分配的容器container(资源列表)给到ApplicationMaster
c、如果分配的资源列表的数量大于0,则对容器进行处理,处理的方式为:
1.AM内部会创建一个线程,并调用线程的run方法,在run方法中循环遍历RM返回的可用容器,然后进行
对每个容器进行匹配,此时涉及到首选位置,根据请求匹配选择哪些容器.首选位置的选择规则见首选位置说明。
2. 运行匹配后的资源,挨个遍历可用的容器,如果运行执行器的数量小于目标执行器的数量"假如需要4个执行
器,即为目标执行器,此时已经运行了2个执行器,即为运行执行器的数量,此时会启动下面的逻辑",
那么在这个容器中会创建一个线程池,一个线程池container对应一个ExecutorRunnable,并调用了这个对象的
run方法,在这个线程池中,有一个nmClient(nameManagClient),说明AM能够找到NM,在这个run方法中,创建
NM的客户端,初始化NM,并启动容器container,在启动容器中,封装一个指令, command:/bin/java
/org.apache.spark.executor.CoarseGrainedExecutorBackend,并且启动了这个指令,显然是一个进程
,CoarseGrainedExecutorBackend,粗粒度的执行器后台。
1. main方法,在main方法中,分三步骤:
1) 封装参数
--val amArgs = new ApplicationMasterArguments(args)
2)创建ApplicationMaster的对象
--master = new ApplicationMaster(amArgs)
3)执行run方法,点击run方法
--System.exit(master.run())
①run方法的实现,点击runImpl
--runImpl()
// 如果是client模式,执行:
-- runExecutorLauncher()
// 如果是集群模式,执行,点击runDriver
-- runDriver
1. 启动用户的程序,返回一个线程,点击startUserApplication
--userClassThread = startUserApplication()
1. 通过类加载器加载一个类,并获取这个类的main方法
-- val mainMethod = userClassLoader.loadClass(args.userClass).getMethod("main", classOf[Array[String]])
2. 创建一个线程
-- val userThread = new Thread
3.
-- userThread.setContextClassLoader(userClassLoader)
4. 设定线程的名字为driver,说明driver就是一个applicationMaster的一个线程
-- userThread.setName("Driver")
5. 启动线程,执行线程的run方法,其实就是执行类userClass的main方法,userClass是哪个类呢?
通过查到,就是我们提交应用的--class,sparkpi,或者是我们自定的类
-- userThread.start()
-- mainMethod.invoke
6. 返回用户线程
-- userThread
2. awaitResult等待结果,线程阻塞,等待对象(SparkContext)的返回
--val sc = ThreadUtils.awaitResult(sparkContextPromise.future,Duration(totalWaitTime, TimeUnit.MILLISECONDS))
3. 返回sparkContext以后,向rm进行注册AM:ApplicationMaster,点击registerAM()
--registerAM(host, port, userConf, sc.ui.map(_.webUrl))
ApplicationMaster的客户端向RM注册自己,并申请资源
--client.register(host, port, yarnConf, _sparkConf, uiAddress, historyAddress)
4. 返回RM分配的容器
--createAllocator(driverRef, userConf)
// 1.AM的客户端,'在RM端',创建分配器,返回一个分配器
-- allocator = client.createAllocator
// 2.分配器分配资源,点击allocateResources
-- allocator.allocateResources()
// 1.AM的客户端,申请一个分配响应
--val allocateResponse = amClient.allocate(progressIndicator)
// 2.分配器响应获取所有被分配的容器container(资源列表)
--val allocatedContainers = allocateResponse.getAllocatedContainers()
// 3.如果可分配的容器数量大于0,则调用处理可用容器的方法,点击handle方法
--if (allocatedContainers.size > 0) =>
handleAllocatedContainers(allocatedContainers.asScala)
// 1.内部会创建一个线程,并调用线程的run方法,在run方法中循环遍历RM返回的可用容器,然后进行
对每个容器进行匹配,此时涉及到首选位置,根据请求匹配选择哪些容器.首选位置的选择规则见
首选位置说明。
// 2. 运行匹配后的资源,点击runAllocatedContainers
--runAllocatedContainers(containersToUse)
// 1. 挨个遍历可用的容器资源
--for (container <- containersToUse)
// 2. 每个容器中,如果运行执行器的数量小于目标执行器的数量,执行如下代码
--runningExecutors.size() < targetNumExecutors
// 3. 线程池,在线程池的内部有:
--launcherPool.execute(new Runnable
// 1.执行的池子是一个线程池
--launcherPool = ThreadUtils.newDaemonCachedThreadPool
// 2.一个线程container对应一个ExecutorRunnable,并调用了这个对象的run方法
--new ExecutorRunnable...run()
// a、在ExecutorRunnable中:说明AM能够找到NM
--nmClient,nodeManager
// b、run()中:其实就是AM与NM建立连接
// 创建NM的客户端
--nmClient = NMClient.createNMClient()
// 初始化NM
--nmClient.init(conf)
// 启动NM
-- nmClient.start()
// 启动容器,点击
--startContainer()
// NM启动容器,启动executor
--nmClient.startContainer(container.get, ctx)
// 封装指令,点击prepareCommand
--val commands = prepareCommand()
commands=/bin/java/org.apache.spark.executor.CoarseGrainedExecutorBackend-->粗粒度的执行器后台,是一个进程
//将封装好的指令传递到参数中
--ctx.setCommands(commands.asJava)
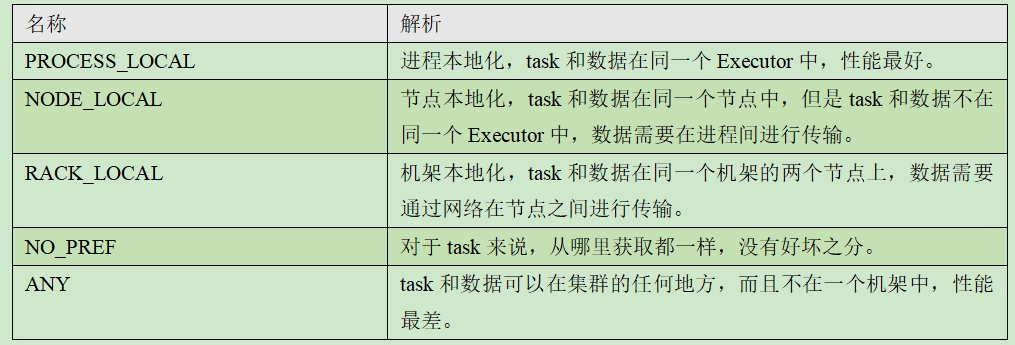
-- 首选位置说明
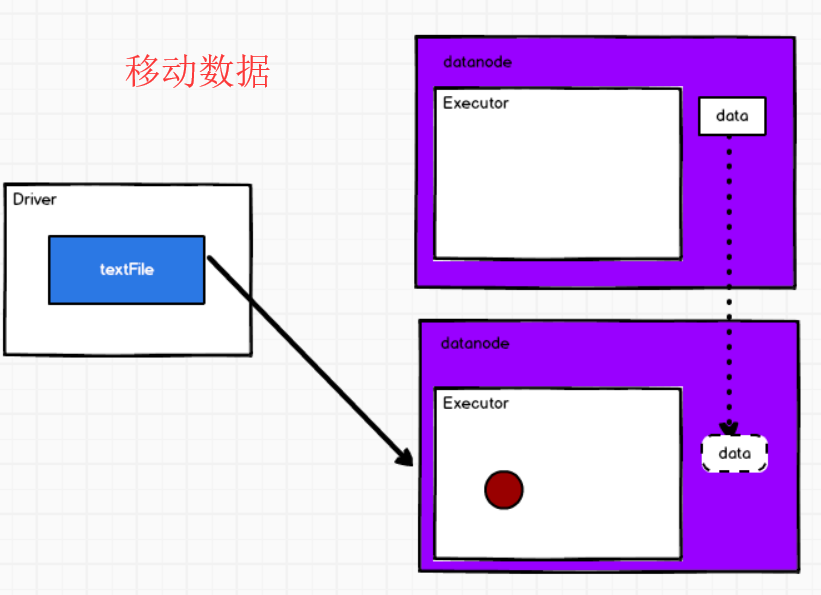
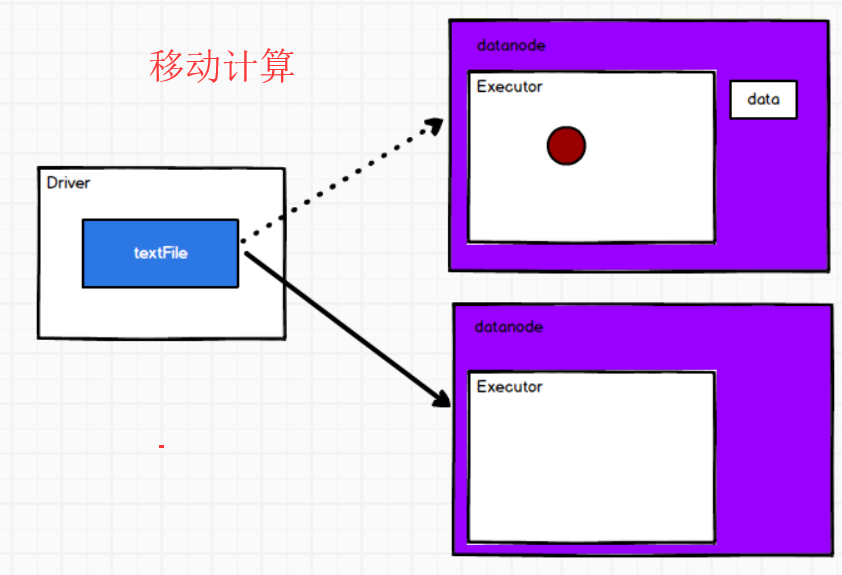
--1. 移动数据不如移动计算。
--2. 首选位置:有多个,和本地化级别有关。
--3. 本地化级别:将数据和计算所在的位置称之为本地化
1. 计算和数据在同一个Executor中,称之进程本地化
2. 计算和数据在同一个节点中,称之节点本地化
3. 计算和数据在同一个机架中,称之机架本地化
4. 任意
2.2.4 CoarseGrainedExecutorBackend
执行一次bin/java就会执行一个新的进程,则是属于并行执行的感觉,和之前执行的内容是分开的。类似我们在Windows中开了一个微信和qq程序一样,各自执行,互不影响。
-- 作用:
执行CoarseGrainedExecutorBackend"执行器后台"的main方法,在main方法中:
1. 首先封装一些参数
2. 执行run方法,在run方法中:
1. 通过driver的URI,使得CoarseGrainedExecutorBackend与Driver进行关联
2. 通过通信环境创建了一个终端,名字为executor,创建一个CoarseGrainedExecutorBackend对象并调用onstart方法:
1. 获取driver的引用
2. ExecutorBackend向driver发送消息,注册executor的消息,也称之为反向注册
3. 在driver端会接收到这个消息,通过executor的引用,发送消息给到ExecutorBackend,注册executor成功
4. ExecutorBackend接收driver返回的executor注册成功的消息,
-- 说明:
executor是一个计算对象,在这个对象里面有一个线程池,每一个线程来处理一个从driver端发送过来的任务
1. commands=/bin/java/org.apache.spark.executor.CoarseGrainedExecutorBackend,
执行这个指令,那么是调用这个类的main方法。
2. main方法中:
// 1. 首先是对一些参数进行封装
// 2. 执行run方法
-- run(driverUrl, executorId, hostname, cores, appId, workerUrl, userClassPath)
// 1.通过driver的uri和Driver进行关联
--driver = fetcher.setupEndpointRefByURI(driverUrl)
// 2.通过通信环境创建了一个终端,名字为executor,
在底层:Executor启动后会注册通信,并收到信息onStart,收到消息后,会执行通信对象CoarseGrainedExecutorBackend
的onStart方法,点击CoarseGrainedExecutorBackend
--env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(
env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))
// 1.获取driver的引用
-- driver = Some(ref)
// 2.ExecutorBackend向driver发送消息,注册executor的消息,也称之为反向注册
--ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls))
// 3.在driver端会接收到这个消息,因为在driver端,有一个上下文的对象,sparkcontext,在这个类有一个属性:
private var _schedulerBackend: SchedulerBackend = _,点击SchedulerBackend,是一个trait,找到
实现类:CoarseGrainedSchedulerBackend,在这个类中,有一个方法:receiveAndReply():
// executor的引用,在driver端,发送消息给到ExecutorBackend,注册executor成功
--executorRef.send(RegisteredExecutor)
// ExecutorBackend类中有一个recive方法,用来接收driver返回的executor注册成功的消息,executor是一
个计算对象,在这个对象里面有一个线程池,每一个线程来处理一个从driver端发送过来的任务
--executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)


2.2.5 总结
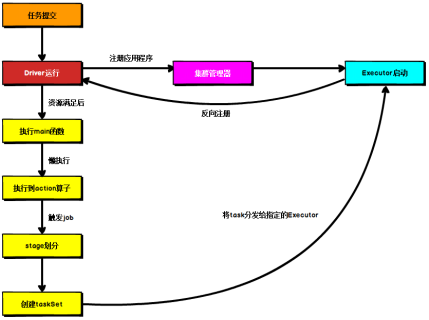
-- 1. application是在一个nodemanager中container中,并且在这个container中创建了一个driver线程
-- 2. 在一个nodemanager中,可以创建多个container,在每个container中,会创建ExecutorBackend对象,在这个对象中,会创建一个executor对象,在这个对象中一个线程池,一个线程用来处理driver发来的一个task,至于能同时执行多少个task,和executor中的core数量有关。
-- 3. ApplicationMaster周旋于Driver和ResourceManager之间
-- 4. spark有两个进程,也就是两个分支
创建RM的客户端,创建AM,在AM中,创建Driver的线程
"分支1":此时会执行Driver线程的run方法,在run方法中就是执行了应用程序的main方法
"分支2":构建SparkContext上下文的对象,再向RM注册AM,然后申请资源和返回可用的资源,最后Driver进行资源的选择,按照首选位置的原则。
所以如下图片有一个错误:资源满足以后才执行main方法,实际上是创建了driver线程,还没有申请资源就已经开始执行main方法了。
-- 5. 进程、线程、对象
"进程":SparkSubmit、ApplicationMaster和CoarseGrainedExecutorBackend
"线程":Driver,但是我们一般称SparkContext称之为Driver
"对象":Executor和YarnClusterApplication
-- 6. client和cluster模式的区别:
Driver的位置不同,其余的逻辑是一样的。
Cluster:在集群中,在nodemanager中的AM对象中,是一个线程
client:在集群之外
三、Spark内部组件及通信
3.1 通信原理
-- 通信原理 - IO - RPC
1. 基本的网络通信:Socket, ServerSocket
2. 通信框架:AKKA(旧), Netty(新)(AIO)
3. 三种IO方式:BIO(阻塞式), NIO(非阻塞式), AIO(异步)
4. Linux, windows
在Linux系统上,AIO的底层实现仍使用EPOLL,与NIO相同,因此在性能上没有明显的优势;Windows的AIO底层实现良好,但是Netty开发人员并没有把Windows作为主要使用平台考虑。微软的windows系统提供了一种异步IO技术:IOCP(I/O CompletionPort,I/O完成端口);Linux下由于没有这种异步IO技术,所以使用的是epoll(一种多路复用IO技术的实现)对异步IO进行模拟。所以在Linux上不建议使用AIO
3.2 组件之间通信
1. 组件:Driver、executor
2. 通信环境:NettyRpcEnvFactory()
通过env.rpcEnv.setupEndpoint,将driver和executor终端放进rpcenv中,那么这个driver和executor就可以通信
3. 组件之间的通信:
a、通信终端共通类:Endpoint
b、通信终端:RpcEndpoint(receive) --> 通信的终端,drive和executor,负责接收数据
c、通信终端引用:RpcEndpointRef(send,ask) --> 通信终端的指代,负责发送和请求
4. 一个终端的生命周期:
The life-cycle of an endpoint is:
创建终端-> 启动终端 -> 接收消息 -> 停止终端
* {@code constructor -> onStart -> receive* -> onStop}
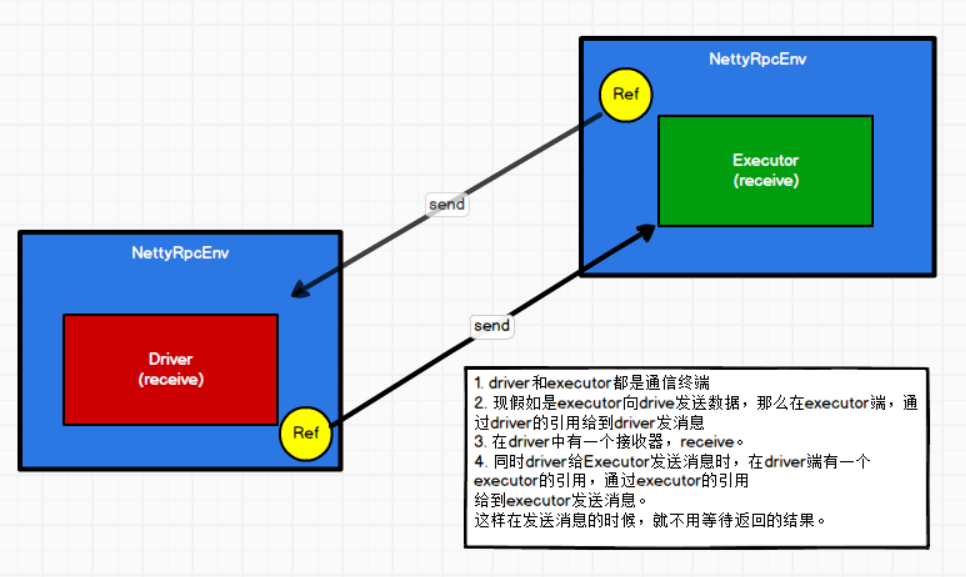
5. "终端和终端的引用是如何关联的呢?"
1. driver和executor都是通信终端
2. 现假如是executor向drive发送数据,那么在executor端,通过driver的引用ref给到driver发消息
3. 在driver中有一个接收器,receive。
4. 同时driver给Executor发送消息时,在driver端有一个executor的引用,通过executor的引用给到executor发送消息。
5. 这样在发送消息的时候,就不用等待返回的结果。
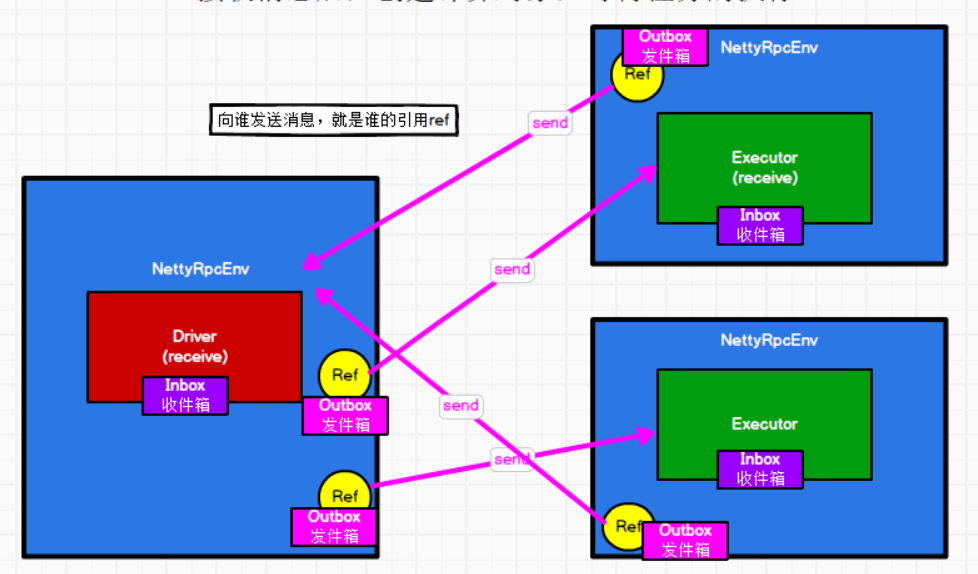
1. 接收消息就是通过收件箱:Inbox
2. 发送消息就是通过发件箱:outbox
3. 一个终端:RpcEndpoint,只有一个收件箱,但是有N个发件箱。
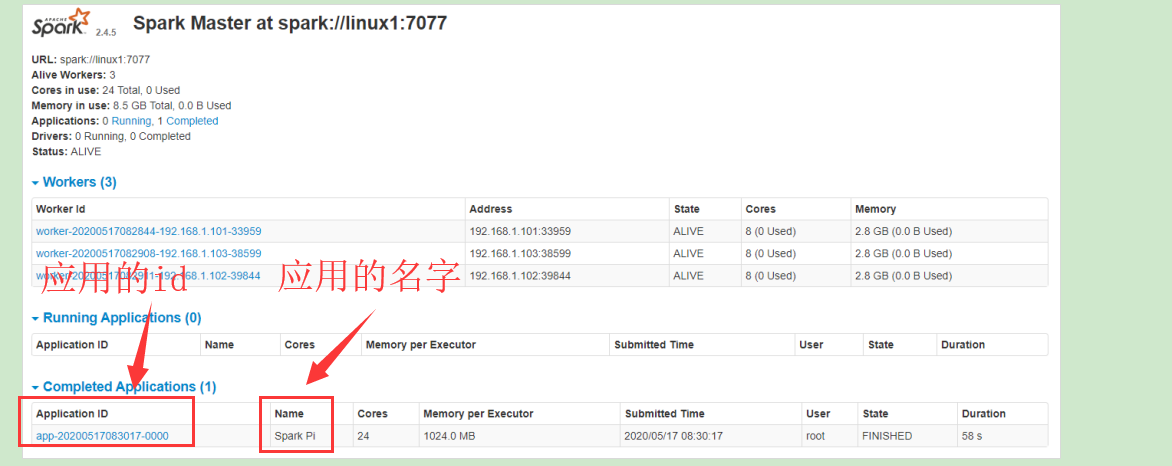
四、作业的调度
4.1 Application
1. Yarn中会有application,提交任务以后,就会产生一个应用,并有一个唯一的应用id
2. 在SparkConf中配置了setAppName(xxxx),设置应用的名字
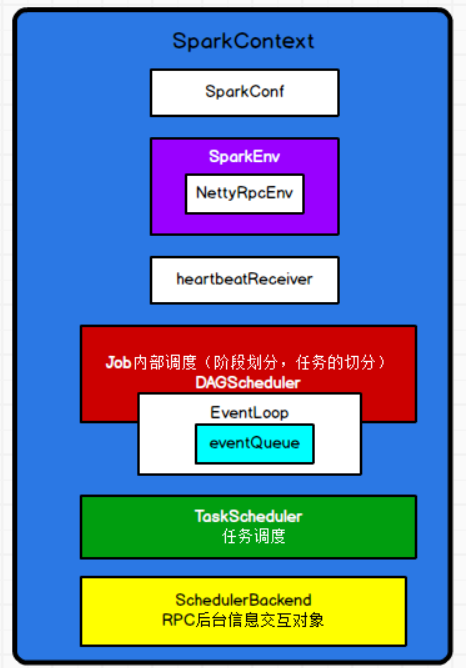
3. SparkContext,是spark核心的对象,核心类,在这个核心类中的一些重要的参数有:
private var _conf: SparkConf = _ -- spark的关键参数
private var _env: SparkEnv = _ -- spark的环境,内部有NettyRpcEnv
private var _schedulerBackend: SchedulerBackend = _ -- spark的调度后台,Rpc后台信息交互对象
private var _taskScheduler: TaskScheduler = _ -- 任务调度器
private var _heartbeatReceiver: RpcEndpointRef = _ -- 指心跳接收器,通信终端的引用
@volatile private var _dagScheduler: DAGScheduler = _ -- 有向无环图调度器,负责job内部调度,负责阶段划分和任务的切分。
-- _conf:下滑线开头,表示内部的变量,不是规范,是早期程序员默认遵守的规范。
4. DAGScheduler ,spark非常核心的调度器。
1.内部有一个对象,DAGSchedulerEventProcessLoop,"指事件调度的规则",点击这个类:
--private[spark] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
1.上面类继承于EventLoop,这个类中有一个属性:事件队列,用来存放事件
BlockingQueue[E]:阻塞式队列
LinkedBlockingDeque:双端队列
-- private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]()
4.2 逻辑代码
1. RDD的创建: 从内存中/从文件中
2. RDD的转换: 转换算子(单value类型、双value类型、kv类型)
3. RDD的行动: 行动算子
4.3 job
1. 触发作业的执行,在行动算子的内部会执行过程:
1.sparkContext提交作业
--> sc.runjob
2. 有向无环图的调度器执行runjob
--> dagScheduler.runJob
3. 提交job
--> submitjob
4. 消息队列进行存放消息
--> eventProcessLoop.post
5. 消息队列将消息放进队列中,这个消息是:JobSubmitted
--> eventQueue.put(event)
6. 在eventQueue有一个线程,线程中有一个run方法
--> eventThread
7. 负责取出消息,因为这个队列是一个阻塞式队列,队列中没有消息,那么就处于阻塞式状态
--> val event = eventQueue.take()
8. 取到消息
--> onReceive(event)
9. 执行处理消息
--> doOnReceive(event)
10. 使用模式匹配的的方式处理消息
--> def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
11. 有向无环图调度器处理任务的提交
--> dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
12. 创建一个活动的job
--> val job = new ActiveJob
-- 总结:
启动一个行动算子 --> runjob -> 将执行事件放进阻塞式队列中 -> 创建一个线程取出队列中的消息 -> 进行模式匹配,处理任务的提交
--> 创建一个运行job
4.4 stage
-- 1. 阶段的划分,取决于转换算子的依赖类型。
-- 2. 宽依赖:ShuffleDependency
-- 3. 窄依赖:OneToOneDependency extends NarrowDependency
-- 4. 分区的数量
a、窄依赖:分区数量保持不变
1. 获取窄依赖的分区数量,点击 firstParent
-- override def getPartitions: Array[Partition] = firstParent[T].partitions
1. 获取依赖关系的第一个rdd分区数量
-- dependencies.head.rdd.asInstanceOf[RDD[U]]
b、宽依赖:
1. 获取宽依赖的分区数量
partitioner:是一个分区器,partitioner,由上一个RDD传递过来的,在传递的时候,会进行判断,如果当前的RDD的分区器
和上一级的分区器一样,那么是不会创建shuffleRDD,只有当前RDD的分区器和上一级的分区器不一样时,才会创建
ShuffledRDD
--Array.tabulate[Partition](part.numPartitions)(i => new ShuffledRDDPartition(i))
2. 默认情况下,默认的分区器将上一级的RDD传入
-- reduceByKey(defaultPartitioner(self), func)
1. 默认的分区数量等于上级RDD的最大值,因为上一级RDD可能有多个
-- val defaultNumPartitions = rdds.map(_.partitions.length).max
2. 构造分区器的时候,将默认的分区数量传入,分区器的作用是指定数据去到哪个分区,分区的数量默认和上一级RDD
保持一致
-- new HashPartitioner(defaultNumPartitions)
-- 5. 总结:
a、窄依赖默认分区数量保持不变
b、宽依赖,默认和上一级 RDD最大的分区数量保持一致,如果上一级RDD只有一个,那就和上一级RDD保持一致
但是Shuffle的算子一般都会有改变分区数量的参数
-- 6. 从文件中创建RDD时默认的分区数量
1. 取(defaultParallelism, 2)的最小值,点击defaultParallelism
--math.min(defaultParallelism, 2)
2. 选择yarn模式中的默认平行度。
--defaultParallelism = conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
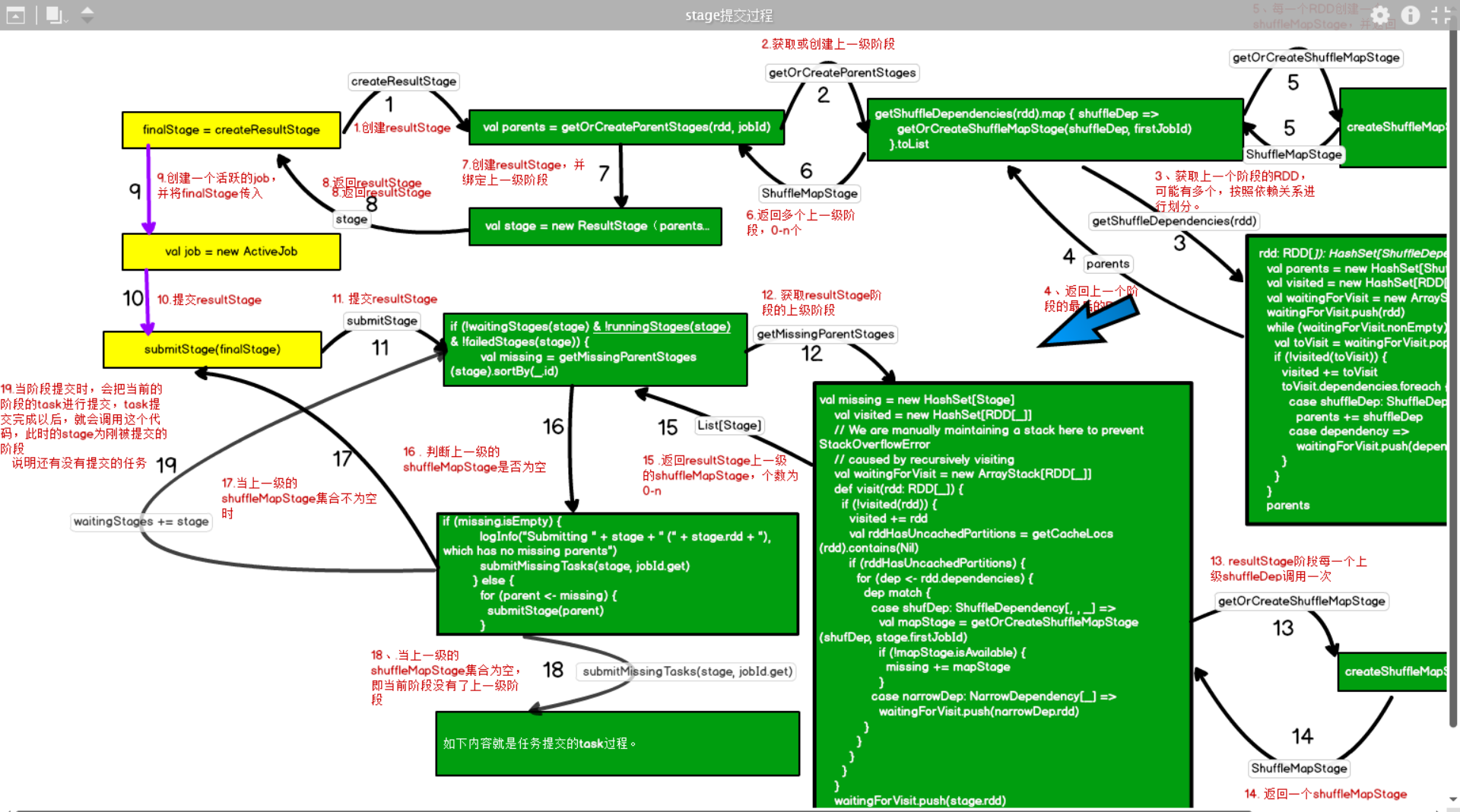
4.5 task的切分
--1. 任务和阶段stage的关系
定位:DAGScheduler类
1. 处理任务的提交handleJobSubmitted,在这个方法的内部:
1. 将整个job作为一个finalStage
-- var finalStage: ResultStage = null
2. 创建一个结果阶段,并赋值给finalStage
finalRDD:最后提交job时的RDD,点击createResultStage
-- finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
1. 通过当前的RDD获取其上一级的阶段,点击getOrCreateParentStages
-- val parents = getOrCreateParentStages(rdd, jobId)
1.获取最后一个RDD的shuffle依赖,每一个shuffle依赖创建一个shufflemapStage
--getShuffleDependencies(rdd).map { shuffleDep =>getOrCreateShuffleMapStage(shuffleDep, firstJobId)}.toList
a. 在getShuffleDependencies方法中,找到resultStage的上一级shuffleRDD
val parents = new HashSet[ShuffleDependency[_, _, _]] -- 存放宽依赖
val visited = new HashSet[RDD[_]] --创建一个hashSet集合,用来存放已经被访问过的RDD
val waitingForVisit = new ArrayStack[RDD[_]] -- 集合的栈,创建一个集合,用来存放待访问的RDD
waitingForVisit.push(rdd) -- 将最后的一个RDD传到这个集合中
while (waitingForVisit.nonEmpty) { -- 集合是否为空,刚放进去,肯定不是空
val toVisit = waitingForVisit.pop() -- pop,弹栈,将刚刚放进去的RDD弹出来,并准备去访问
if (!visited(toVisit)) { -- 当前放进去的RDD是否被访问过,如果没有,则继续向下执行
visited += toVisit -- 将当前获取的RDD放进已经被访问的RDD集合中
toVisit.dependencies.foreach { -- 获取RDD与直接上级的RDD的依赖关系,并循环遍历。
case shuffleDep: ShuffleDependency[_, _, _] => -- 如果是宽依赖
parents += shuffleDep -- 则将依赖加入parents集合中
case dependency =>
waitingForVisit.push(dependency.rdd) -- 如果是窄依赖,将上级RDD放进等待访问的RDD中,并
进行循环,判断其与上级RDD的依赖关系,直到当前的RDD为
shuffleRDD
}
}
}
parents -- 将上一级shuffleRDD放进parents的集合中
获取当前RDD与直接上级的RDD的依赖关系,返回一个seq序列集合,因为当前的RDD的直接上级的RDD可能有多个
-- toVisit.dependencies
b、通过map方法,对resultStage上级的shuffleRDD进行遍历,调用如下方法:返回获取的ShuffleDependency,执行获取或创建shuffleMapStage,点击这个方法
-- getOrCreateShuffleMapStage
创建shuffleMapStage,每一个shuffleDep创建一个shuffleMapStage
-- createShuffleMapStage(shuffleDep, firstJobId)
new出一个shuffleMapStage
// 将依赖的上一级RDD赋值给rdd
--val rdd = shuffleDep.rdd
// 又调用了创建或获取上一级阶段
-- val parents = getOrCreateParentStages(rdd, jobId)
-- val stage = new ShuffleMapStage
--2. 阶段的类型
ResultStage 和 shuffleMapStage
--3. 阶段的数量
= ResultStage + n * shuffleMapStage
--4. 任务和分区的关系
1. 提交最后一个阶段:
--submitStage(finalStage)
1. 获取当前阶段的上一级阶段
-- val missing = getMissingParentStages(stage).sortBy(_.id)
2. 如果有上一级阶段不为空,则循环遍历上一阶段,先假如上一级阶段只有一个,则提交上一个阶段,又调用提交阶段
--for (parent <- missing) {submitStage(parent)}
"总结:在提交阶段时,从最后一个阶段往前找,直到最前面的一个阶段,然后再依次从前往后进行提交阶段"。
2. 当没有上一级阶段以后,提交任务
-- submitMissingTasks(stage, jobId.get)
// 1.对当前阶段进行模式匹配,确认是shuffleMapSrage还是ResultStage,返回结果为taskIdToLocations,任务本地化路径
// 2. 如果当前阶段是ShuffleMapStage,则创建ShuffleMapTask
如果当前阶段是ResultStage ,则创建ResultTask
val tasks: Seq[Task[_]] = try {
case stage: ShuffleMapStage
partitionsToCompute.map --> 计算分区的数量,每一个分区,会执行如下创建任务的代码。
{........
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber
.....}
case stage: ResultStage =>
{
.......
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
.......
}
-- 5. task的类型:
a、如果当前阶段是ShuffleMapStage,则创建ShuffleMapTask
b、如果当前阶段是ResultStage ,则创建ResultTask
-- 6 .任务的总数量
= 每个阶段的任务总和
--总结:
1. 通过resultStage最后一个RDD,进行循环依次向上找,获取resultStage阶段,上一级为shuffleDep的ShuffleDependency,
存放到一个parents集合中
2. 采用map算子,parents集合中的每个ShuffleDependency,获取到所有上级依赖为shuffleDep的RDD,然后每一个shuffleDep会创建
一个ShuffleMapStage阶段。
3. 当找到job最前面一个RDD以后,开始从第一个阶段提交阶段,提交阶段时,首先获取当前阶段最后一个RDD的分区数量,在一个阶段中,每一个分区就会创建一个task,task的类型和阶段的类型匹配:
a、如果当前阶段是ShuffleMapStage,则创建ShuffleMapTask
b、如果当前阶段是ResultStage ,则创建ResultTask
4. 当前阶段提交完成以后,就提交下一个阶段,依次类推,最后就会提交resultStage。
五、任务的执行
5.1 任务包含的内容
1.任务的提交:
--new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
2. 提交的重要几个参数有:
a、"stage.id":任务从属的阶段id
b、"taskBinary":是一个广播变量,内容为:阶段的"RDD"和"依赖关系"序列化以后的二进制字节码,因为RDD是不保存数据,一旦任务执行失败,需要知道RDD的元数据信息以及依赖关系,才能进行重新计算。
1. 是一个广播变量
--var taskBinary: Broadcast[Array[Byte]] = null
2. 将任务的二进制的字节码赋值给了这个广播变量
--taskBinary = sc.broadcast(taskBinaryBytes)
3. 任务的二进制的字节码是通过对阶段匹配,如果是shuffle阶段,就会采用闭合的序列化器将阶段的RDD和阶段的依赖进行序列化
--taskBinaryBytes = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
c、 "part" :分区,指当前的task和哪个partition有关
-- val part = partitions(id)
d、 "locs" : 任务的首选位置
-- val locs = taskIdToLocations(id)
5.2 序列化
1. 默认的序列化:"JavaSerializer"
1. 在SparkContext中创建了SparkEnv,点击创建的方法,一层一层往里点:
-- _env = createSparkEnv(_conf, isLocal, listenerBus)
1. 最终看到了默认的序列化器为:JavaSerializer
--val serializer = instantiateClassFromConf[Serializer](
"spark.serializer", "org.apache.spark.serializer.JavaSerializer")
logDebug(s"Using serializer: ${serializer.getClass}")
2. kryo序列化:
--1.特点:
a、性能优
b、序列化结果文件的字节数少
c、可以绕过java的序列化,将不能序列的对象也能进行序列化
d、但是,我们在实际的情况下,并不是所有的对象都会采用kryo序列化。
--2. 那么哪些对象采用kryo序列化会比较有优势呢?
"总结:在shuffle阶段,当为kv类型时,k、v的数据类型如果都支持kryo序列,则会采用kryo进行序列化。
支持ktyo序列化的数据类型有:String和值类型(anyVal)"
底层:当有shuffle阶段时,会选择最好的序列化器
-- Pick the best serializer for shuffling an RDD of key-value pairs.
2. 判断选择的规则:
如果kv的k和v都能使用kryo序列化器时,则选择kryo序列化器,否则选择默认的序列化器:javaSerializer
当为如下类型(值类型)或者是string类型的时候,则可以使用kyro序列化器
--if (canUseKryo(keyClassTag) && canUseKryo(valueClassTag)) {
kryoSerializer
} else {
defaultSerializer
}
-- ClassTag.Boolean,
ClassTag.Byte,
ClassTag.Char,
ClassTag.Double,
ClassTag.Float,
ClassTag.Int,
ClassTag.Long,
ClassTag.Null,
ClassTag.Short
5.3 任务的调度
-- 1. driver生成的任务以后存放在哪里了?
a、当driver生成任务以后,并不是立即将任务task就发送给executor,因为可能发送过程有异常,也可能发送过去的时候,executor对象还没有创建,都会导致任务task发送失败
1. 一个阶段stage生成tasks以后,如果这个阶段的tasks的数量大于0,那么这个任务调度器就会提交任务,在提交任务中,会将这个
stage的任务封装成一个TaskSet,任务集进行提交,点击submitTasks
-- if (tasks.size > 0),taskScheduler.submitTasks(new TaskSet( tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
1.首先取出任务
--val tasks = taskSet.tasks
2. 创建一个任务集taskset的管理者manager
-- val manager = createTaskSetManager(taskSet, maxTaskFailures)
3. 构建调度器,将刚刚创建的任务集管理者放到调度器中,点击addTaskSetManager
--schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
1.是一个抽象方法,类是一个trait,有两个实现类,分别是:
FIFOSchedulableBuilder --> 先进先出调度器
FairSchedulableBuilder --> 公平调度器
那么我们新增加进去的manager是采用什么调度器呢?
a、通过源码可知,默认的调度模式为FIFO模式
-- private val schedulingModeConf = conf.get(SCHEDULER_MODE_PROPERTY, SchedulingMode.FIFO.toString)
b、创建一个任务调度池,当driver生成任务以后,会将任务放进任务池中,由manager来进行调度
val rootPool: Pool = new Pool("", schedulingMode, 0, 0)
2. 将manager直接放进调度池中,
rootPool.addSchedulable(manager)
4. 点击.reviveOffers:恢复当前的操作
--backend.reviveOffers()
1.driver的终端,自己给自己发消息
-- driverEndpoint.send(ReviveOffers)
2.在DriverEndpoint中,就有一个receive方法,在这个方法中,匹配获取的消息,如果是ReviveOffers,
则执行makeOffers()方法,点击makeOffers()方法
-- case ReviveOffers =>makeOffers()
a、DriverEndpoint调度器从任务池中取出任务,取任务的具体方式:点击resourceOffers
-- val taskDescs = scheduler.resourceOffers(workOffers)
a、获取一个排好序的任务集合,实现方式,点击getSortedTaskSetQueue
--val sortedTaskSets = rootPool.getSortedTaskSetQueue
a、如下为任务集的调度的算法,依据算法对任务集进行比较排序,返回排好序的任务集,然后将
返回任务集存放到一个arraybuffer集合中,并返回给到sortedTaskSets,不同的调度的算法
是不一样的。
"FIFO调度算法":先比较优先级,优先级高的先调度,如果优先级相等,则比较阶段id,阶段
id小的先执行。
"Fair调度算法":根据运行任务的数量、权重【默认值为1】、最小分配数量【默认值为0】,
进行综合分配
-- val sortedSchedulableQueue =
schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
b、如果任务不为空,则driver发射任务
-- if (!taskDescs.isEmpty) {launchTasks(taskDescs)}
-- 1.总结
1. 一个stage生成tasks以后,由taskSchedule负责任务的调度
2. 一个stage就会有一个任务集,taskSet
3. 每一个taskSet都会被封装成TaskSetManager,负责监控管理同一个Stage中的Tasks,TaskScheduler调度模式有两种:
a、FIFOSchedulableBuilder --> 先进先出调度器【默认调度模式】
b、FairSchedulableBuilder --> 公平调度器
4. TaskScheduler初始化过程中会实例化rootPool任务池,driver准备的任务和管理者会发送到这个任务池中,
由TaskScheduler负责将任务调度结果发送给executor
5. driver的终端自己给自己发送一个消息"ReviveOffers",driverEndpoint收到ReviveOffer消息后调用makeOffers方法,TaskScheduler就开始进行任务集的调度
6. 根据"调度算法"对任务集进行排序,获取一个排好序的队列"排序在前的就先执行,排序在后的就后执行",将排好序的队列放到一个arraybuffer集合中,并返回给到sortedTaskSets
"FIFO调度算法":先比较优先级,优先级高的先调度,如果优先级相等,则比较阶段id,阶段 id小的先执行。
"Fair调度算法":根据运行任务的数量、weight【默认值为1】、minShare【默认值为0】,进行综合分配
minShare、weight的值均在公平调度配置文件"fairscheduler.xml"中被指定,调度池在构建阶段会读取此文件的相关配置
7. "driverEndpoint"调度器就从这个排好序的任务队列的数组中取任务tasks。
8. 如果获取的任务不为空,则dirver开始发射任务
-- 2.说明:
1. 从任务池中取出的任务,包含了本地化级别信息以及等待的时长("默认每个级别等待时间为3s,也可以单独设置每个级别的等待时间"),当在driver在发送任务的时候,会根据本地化级别进行发送任务.
-- 3.区分本地化级别和调度算法
调度算法:是指driverEndpoint在调度任务集时,确定哪个任务集先执行,哪个任务集后执行
本地化级别:是指driver在发送向executor发送任务的首选位置,确定任务发送到哪个executor中,如果发送不成功,并进行降级处理
5.4 任务的计算
1. driver发送任务前,会将任务进行编码:
--val serializedTask = TaskDescription.encode(task)
2. 然后向executor发送已经编码和序列化的任务task
-- executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask))
3. 在executorbackend就会收到任务(receive)并启动任务,首先是对任务进行解码,然后executor启动任务,点击launchTask
--val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskDesc)
4. 来一个task就使用一个线程来接收
--val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
threadPool.execute(tr)
5. 线程中有一个run方法,方法中有一个逻辑为:task.run,通过底层发现,其实调用的是具体task对象的runTask()方法
5.5 shuffle
【在"shuffleMapTask类"中的runTask()方法中】
1. shuffle"写操作"
--var writer: ShuffleWriter[Any, Any] = null
2. 在写操作之前,也会调用迭代器的方式,所以也可以实现"读的操作"
--writer.write(rdd.iterator(partition, context)......
【在"resultTask类"中的runTask()方法中,那么就得有读数据的操作】
1. RDD中不保存数据,所以操作的时候数据是一条一条的执行,则会调用迭代器的方法,点击iterator方法
-- func(context, rdd.iterator(partition, context))
1. 一层一层的调,在shuffleRDD中的computer中有:"读的操作"
-- SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context).read()
"分支1": Shuffle map(Write)
1. 点击getWrite
-- writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
1. getWriter是一个抽象方法,所在的类为:ShuffleManager,'shuffle管理器',获取其实现类:"SortShuffleManager"
是一个可排序的shuffleManager管理器。查询这个管理类的getWriter方法,在这个方法中,对handle的类型进行模式匹
配,所以现在handle就很很重要了,从模式匹配项,可以知道有3种不同类型的handle,而且handle来自"getWriter方法"
-- handle match {
case unsafeShuffleHandle: SerializedShuffleHandle
case bypassMergeSortHandle: BypassMergeSortShuffleHandle
case other: BaseShuffleHandle
2.在 "manager.getWriter"方法中的handle到底是什么?看源码
1. 是shuffle管理器注册shuffle获取的,点击registerShuffle
--val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
2. 是一个抽象方法,获取抽象类"ShuffleManager"的实现类"SortShuffleManager",查询"registerShuffle"方法
从这里发现,确实有三种handle:
a、如果忽略索引文件的排序 --> 创建BypassMergeSortShuffleHandle
b、如果可以实现序列化 --> 创建SerializedShuffleHandle
c、如果不是以上两种 --> 创建BaseShuffleHandle
--if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) {
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
}
1. 点击"shouldBypassMergeSort",查看什么情况下忽略排序,如果当前rdd的map端有预聚合功能,就
不能忽略排序,如reduceByKey算子
-- if (dep.mapSideCombine) {false}
如果map端没有预聚合功能,首先获取忽略合并的阈值,如果没有显示设置,就会默认给200,如果当前RDD的
分区器的分区数量小于这个阈值,那么就返回true,则此时创建"BypassMergeSortShuffleHandle"
--else {
val bypassMergeThreshold: Int = conf.getInt("spark.shuffle.sortbypassMergeThreshold", 200)
dep.partitioner.numPartitions <= bypassMergeThreshold
-- 所以总结就是当rdd的map端没有预聚合功能,且分区器的分区数量小于阈值,那么就会创建
"BypassMergeSortShuffleHandle"
2. 点击"canUseSerializedShuffle",Spark的内存优化后的解决方案,对象序列化后不需要反序列化。
// 通过以下代码可知,创建"SerializedShuffleHandle"的条件为,满足以下三个条件即可:
a、序列化对象需要"支持"重定义
b、依赖的map端"没有"预聚合功能
c、分区数量"小于"(1 << 24) - 1 = 16777215
if (!dependency.serializer.supportsRelocationOfSerializedObjects) { false}
else if (dependency.mapSideCombine) {false }
else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) { false}
else {true }
3. 如果以上两个handle都不满足,则选择最后一个handle:"BaseShuffleHandle" -->默认的handle
"分支2":Shuffle reduce(Read)
-- 总结: shuffle的handle有三种:
1. BypassMergeSortShuffleHandle --> BypassMergeSortShuffleWriter
"条件":
a、当前rdd的map端没有预聚合功能,如groupBy
b、分区器的分区数量小于阈值,默认为200
2. SerializedShuffleHandle --> UnsafeShuffleWriter
"条件":
a、序列化对象需要"支持"重定义
b、依赖的map端"没有"预聚合功能
c、分区数量"小于"(1 << 24) - 1 = 16777215
3. BaseShuffleHandle --> SortShuffleWriter
"默认的handle"
如果前两种都不满足,那么就使用默认的write
拿着这三种handle,再来看这个"getWrite"方法
-- handle match {
-- case unsafeShuffleHandle: SerializedShuffleHandle =>
new UnsafeShuffleWriter....
-- case bypassMergeSortHandle: BypassMergeSortShuffleHandle =>
new BypassMergeSortShuffleWriter....
-- case other: BaseShuffleHandle =>
new SortShuffleWriter....
"不同的handle对应不同的writer"
1. BypassMergeSortShuffleHandle --> BypassMergeSortShuffleWriter
// 点击"BypassMergeSortShuffleWriter"中的write方法,如下代码,根据分区的数量进行循环,'每一个分区就向磁盘写一个文
件'。 即map端的每一个task会为reduce端的每一个task都创建一个临时磁盘文件,根据key的hashcode%分区数量,决定数据去到
哪个分区文件中。
-- for (int i = 0; i < numPartitions; i++) {
partitionWriters[i] = blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, writeMetrics);}
2. SerializedShuffleHandle --> UnsafeShuffleWriter
3. BaseShuffleHandle,"重要" --> SortShuffleWriter
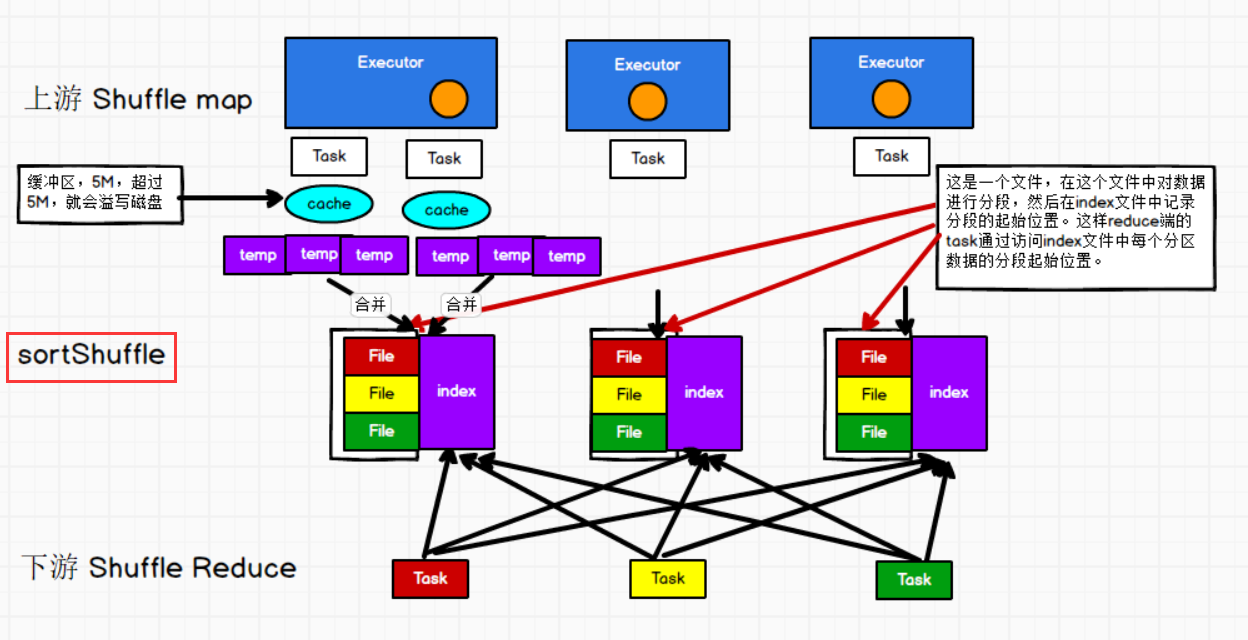
// 点击"SortShuffleWriter"中的write方法,如下代码:
// 1. "写文件过程":写磁盘文件时,首先将数据写到内存中,并在内存中的进行排序,如果内存(5M)不够,会溢写磁盘,
生成临时文件(一个数据文件,一个索引文件),最终将所有的临时文件合并(原来的数据文件和索引文件会被删除)成数据
文件和索引文件。
2. "预聚和的原理":在排序时,构造了一种类似于hashtable的结构,所以相同的key就聚合在一起。
3. "排序规则":首先会按照分区进行排序,然后按照key.
4. "数据进入不同分区的原则":按照分区器的原则,默认是hashpartition,根据key的hash%分区数量。
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit...
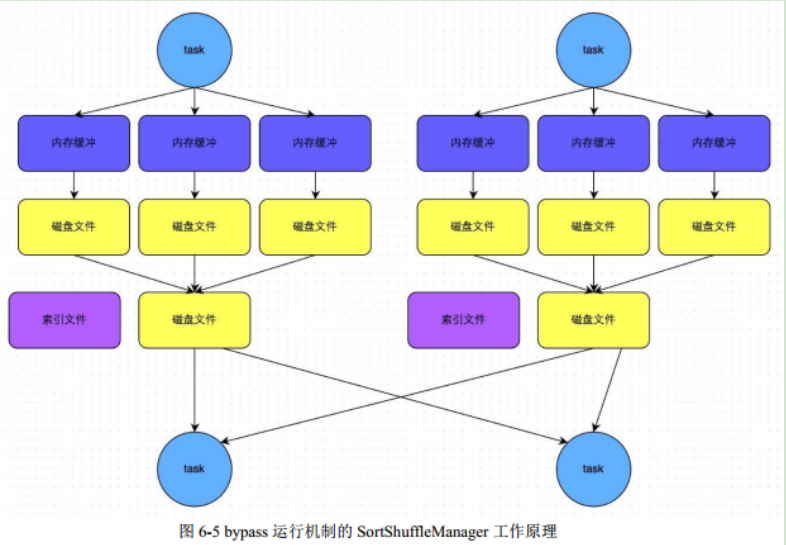
-- 面试中常见shuffle的两个问题:
1. 我们现在spark使用了哪种shuffle,哪一种类型的?
a、sortshuffle。
2. 忽略排序过程的shuffle什么时候会触发?
a、map 端没有预聚合功能
b、reduce端的分区数量小于一个阈值,默认是200
六 、 Spark内存管理
6.1 堆内内存和堆外内存
--1. "堆内内存":
是指jvm所能使用的内存,并不是完全可以控制,如GC垃圾回收器的执行时间是不可控的,当你需要内存进行数据处理时,GC并不能立
马释放内存给你使用。jvm虚拟机默认使用的内存大小是可用内存的1/64,最大值是1/4
--2. "堆外内存":
在jvm虚拟机之外的内存,可以存储我们的数据,这个内存是咱们向操作系统申请过来的,完全可控。"默认是不启用堆外内存"
--3. 设置堆外内存的参数:
a、启动堆外内存参数:spark.memory.offHeap.enabled
b、设定堆外内存的大小: spark.memory.offHeap.size
--4. 在spark中,堆内和堆外内存可以进行统一的管理。
6.2 内存空间分配
6.2.1 早期内存管理
"早期各个区域的内存分配好了以后,就需要严格遵守这个规则,内存大小不可变。"
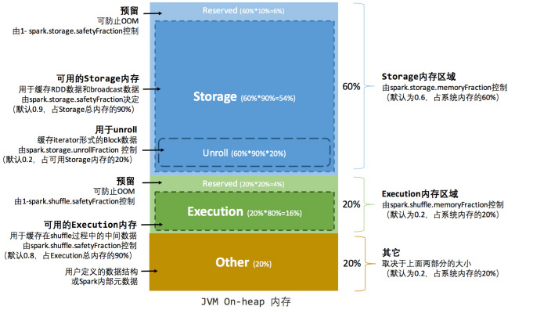
--1. 内存空间的分配:
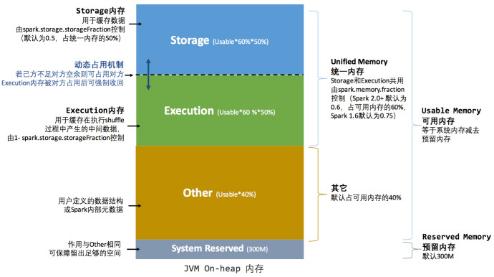
1. Storage:缓存RDD数据和广播变量的数据, "内存大小占比60%"
2. Execution:用于缓存在shuffle过程中的中间数据, "内存大小占比20%"
3. Other:用户自定义的一些数据结构或者是Spark内部的元数据 : "内存大小占比20%"
-- 2. Storage内存和Execution内存都有预留空间,目的是防止OOM,因为Spark堆内内存大小的记录是不准确的,需要留出保险区域。
-- 3. 当前不同区域内存大小分配存在的问题:
Execution的内存过小,而Storage内存大小过多。
从而就产生了新的内存分配原则
- 堆内内存
- 堆外内存
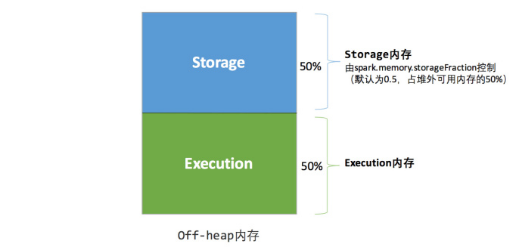
6.2.2 统一内存管理
-- 1. 什么是统一内存管理?
Spark1.6 之后引入的统一内存管理机制,各个区域内存的大小是可变的.
--2.与静态内存管理的区别:
统一内存管理"存储内存"和"执行内存共享"同一块空间,可以动态占用对方的空闲区域
-- 3. 当前spark默认的内存分配是按照统一内存管理的模式。
- 堆内内存
- 堆外内存
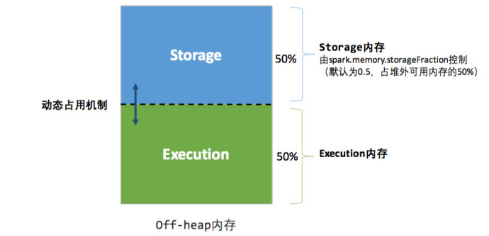
6.2.3 同一管理内存的优点
-- 1. 优点
1)设定基本的存储内存和执行内存区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间的范围;
2)双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的Block)
3)执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间;
4)存储内存的空间被对方占用后,无法让对方”归还”,因为需要考虑 Shuffle过程中的很多因素,实现起来较为复杂。
-- 2. 统一内存管理的动态占用机制图如下:
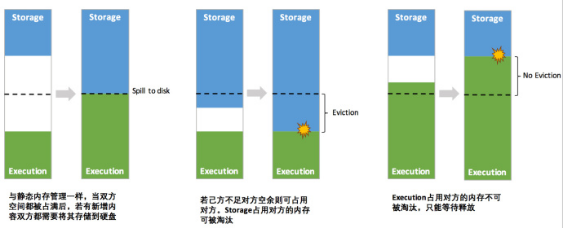
-- 注意事项
1. 如果是storage借了Execution的内存,那么当Execution需使用时,storage占用Execution的内存就要想办法还给Execution,一般可以进行落盘,但是在内存中的数据有一个存储级别,如果仅仅是Memory_Only的话,那么此时占用内存的数据就会丢失。
2. 如果是Execution借了storage的内存,那么当storage需使用时,Execution并不会把内存还给storage,那么此时storage的数据就会溢写磁盘,如果不能溢写的话,那么就会丢失或淘汰。
-- 面试题:
1. 动态占用机制图是什么情况?
2. 为什么cache为丢失数据?
3. 阶段的划分
4. task的发送
-- 1. 什么是统一内存管理?
Spark1.6 之后引入的统一内存管理机制,各个区域内存的大小是可变的.
--2.与静态内存管理的区别:
统一内存管理"存储内存"和"执行内存共享"同一块空间,可以动态占用对方的空闲区域
-- 3. 当前spark默认的内存分配是按照统一内存管理的模式。
- 堆内内存
[外链图片转存中…(img-n9FY8xpk-1600591251528)]
- 堆外内存
[外链图片转存中…(img-PMmIONkB-1600591251529)]
6.2.3 同一管理内存的优点
-- 1. 优点
1)设定基本的存储内存和执行内存区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间的范围;
2)双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的Block)
3)执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间;
4)存储内存的空间被对方占用后,无法让对方”归还”,因为需要考虑 Shuffle过程中的很多因素,实现起来较为复杂。
-- 2. 统一内存管理的动态占用机制图如下:
[外链图片转存中…(img-bawQACdm-1600591251530)]
-- 注意事项
1. 如果是storage借了Execution的内存,那么当Execution需使用时,storage占用Execution的内存就要想办法还给Execution,一般可以进行落盘,但是在内存中的数据有一个存储级别,如果仅仅是Memory_Only的话,那么此时占用内存的数据就会丢失。
2. 如果是Execution借了storage的内存,那么当storage需使用时,Execution并不会把内存还给storage,那么此时storage的数据就会溢写磁盘,如果不能溢写的话,那么就会丢失或淘汰。
-- 面试题:
1. 动态占用机制图是什么情况?
2. 为什么cache为丢失数据?
3. 阶段的划分
4. task的发送














 817
817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









