







二面
1、自我介绍
2、项目介绍,及其亮点介绍。
3、然后问了我集合了解吗,让我说话ArrayList和LinkedList的区别?
答:ArrayList底层是数组,LinkedList底层是链表,ArrayLIst查找数据快,LinkedList插入删除快;
4、继续问我linkedList可以用for循环遍历吗?
答;能不用尽量不要用,linkedList底层是链表,它使用for进行遍历,访问每一个元素都是从头开始访问然后直到找到这个元素,比如说找第三个节点,需要先找到第一个节点然后找到第二个节点;继续找第4个节点,不是从第三个节点开始找的,还是从第一个节点开始,所以非常的慢,不推荐,可以用迭代器进行遍历。
5、介绍一下ConCurrenthashmap
答:我感觉是因为一面问了hashmap,所以二面面试官可能是看见了面试记录,额,这块我非常熟,这个我又讲了很长时间,讲了ConCurrentHashMap的底层的分段锁的结构,讲了ConCurrentHashmap的get源码,get源码是没有使用锁的,这里我把get源码背写了下来,并给面试官讲了get源码在插入修改删除的多线程下是安全的;然后讲了put操作,
put实现
当执行put方法插入数据时,根据key的hash值,在Segment数组中找到相应的位置,如果相应位置的Segment还未初始化,则通过CAS进行赋值,接着执行Segment对象的put方法通过加锁机制插入数据,实现如下:
场景:线程A和线程B同时执行相同Segment对象的put方法
- 1、线程A执行tryLock()方法成功获取锁,则把HashEntry对象插入到相应的位置;
- 2、线程B获取锁失败,则执行scanAndLockForPut()方法,在scanAndLockForPut方法中,会通过重复执行tryLock()方法尝试获取锁,在多处理器环境下,重复次数为64,单处理器重复次数为1,当执行tryLock()方法的次数超过上限时,则执行lock()方法挂起线程B;
- 3、当线程A执行完插入操作时,会通过unlock()方法释放锁,接着唤醒线程B继续执行;
从类图中可以看出来在存储结构中ConcurrentHashMap比HashMap多出了一个类Segment,而Segment是一个可重入锁。
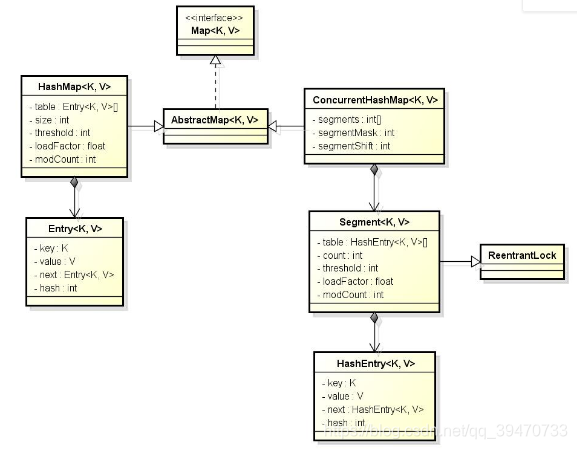
- ConcurrentHashMap是使用了锁分段技术来保证线程安全的。
- 锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
- ConcurrentHashMap提供了与Hashtable和SynchronizedMap不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
- ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
- remove,扩容操作,然后讲了在1.7和1.8的区别,引入了红黑树,链表长度大于8转换成红黑树,采用了CAS+synchronized来保证并发安全,吧啦吧啦又讲了挺长时间;
6、来看看这道题,说着拿出来一个小纸条
答:题目:让我自己手算a=10>>1 ,b = a++,c = ++a,d = c*d 的值。结果是a = 5 b=5,c=7,d=35.计算完我问他对不对,他没勒我。。。
7、然后问我单利模式了解不,写一个单例模式?请参考:https://blog.csdn.net/qq_39470733/category_7500143.html
8、接着问了我虚拟机了解吗,介绍一些虚拟机的内存模型?请参考:https://blog.csdn.net/qq_39470733/category_7116164.html
答:虚拟机的内存模型和运行时的数据区域不是一回事;虚拟机内存模型又叫JMM(edon区,from/to区,old区 永久代/元空间),就是每个线程有自己的工作内存,然后有一个主内存,所有的共享变量都存储在主内存(Main Memory)中。线程工作的时候都是在自己的工作内存中拷贝一个主内存的副本;还说了JMM的happens before原则,程序顺序原则,锁原则,线程中断原则,传递性原则,还有其他的没想起来就没说了。
9、介绍一些你了解的垃圾回收算法?
答:引用计数法、标记清除,标记整理,复制算法,把每个算法是啥说了一遍;
10、问到这里,问了我你知道SurvivorRatio这个参数为啥初始是默认的8:1:1吗?
答:这个由于刚才刚问了垃圾回收算法,我觉得可能有关联,于是我说,方便复制算法操作,Eden区域大多数都是朝生夕死的,这个比例,可以方便复制算法的中from和to来回进行复制存活的对象。
11、突然又问,二叉树了解吗,写一个二叉树的深度搜索遍历?
答:当时我听到中道题,有点懵,什么是二叉树的深度搜索遍历,我只知道层次遍历,前序后序中序遍历啊,我想了想,感觉和后序遍历挺像的,我觉得应该就是后序遍历吧,我就先写了个后序遍历的递归写法。
public ArrayList<Integer> deep(TreeNode root) {
ArrayList<Integer> lists=new ArrayList<Integer>();
if(root==null)
return lists;
Stack<TreeNode> stack=new Stack<TreeNode>();
stack.push(root);
while(!stack.isEmpty()){
TreeNode node=stack.pop();
//先往栈中压入右节点,再压左节点,这样出栈就是先左节点后右节点了。
if(node.right!=null)
stack.push(tree.right);
if(node.left!=null)
stack.push(tree.left);
lists.add(node.val);
}
return lists;
}12、java多线程你都知道哪些。请参考:https://blog.csdn.net/qq_39470733/category_7978302.html
13、项目上线了吗,网站的PV(很不好意思的说项目没上线)
PV(Page View)访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录1次,多次打开或刷新同一页面则浏览量累计。
UV(Unique Visitor)独立访客,统计1天内访问某站点的用户数(以cookie为依据);访问网站的一台电脑客户端为一个访客。可以理解成访问某网站的电脑的数量。网站判断来访电脑的身份是通过来访电脑的cookies实现的。如果更换了IP后但不清除cookies,再访问相同网站,该网站的统计中UV数是不变的。如果用户不保存cookies访问、清除了cookies或者更换设备访问,计数会加1。00:00-24:00内相同的客户端多次访问只计为1个访客。
14、spring事务管理怎么实现,你的项目中是如何使用的
可以用通过四种方式实现事务管理,分别是 编程式事务管理、基于 TransactionProxyFactoryBean的声明式事务管理、基于 @Transactional 的声明式事务管理 和 基于Aspectj AOP配置事务REQUIRED:如果有事务则加入事务,如果没有事务,则创建一个新的(默认值);
传播机制:
- NOT_SUPPORTED:Spring 不为当前方法开启事务,相当于没有事务;
- REQUIRES_NEW:不管是否存在事务,都创建一个新的事务,原来的方法挂起,新的方法执行完毕后,继续执行老的事务;
- MANDATORY:必须在一个已有的事务中执行,否则报错;
- NEVER:必须在一个没有的事务中执行,否则报错;
- SUPPORTS:如果其他 bean 调用这个方法时,其他 bean 声明了事务,则就用这个事务,如果没有声明事务,那就不用事务;
- NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与 REQUIRED 类似的操作;
常用参数:
- ISOLATION_DEFAULT:使用后端数据库默认的隔离界别,MySQL默认采用的REPEATABLE_READ 隔离级别,Oracle 默认采用的 READ_COMMITTED 隔离级别;
- ISOLATION_READ_UNCOMMITTED:最低的隔离级别,允许读取,允许读取尚未提交的的数据变更,可能会导致脏读、幻读或不可重复读;
- ISOLATION_READ_COMMITTED:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生;
- ISOLATION_REPEATABLE_READ:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生;
- ISOLATION_SERIALIZABLE:最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就说,该级别可以阻止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
7、spring的模块有哪些
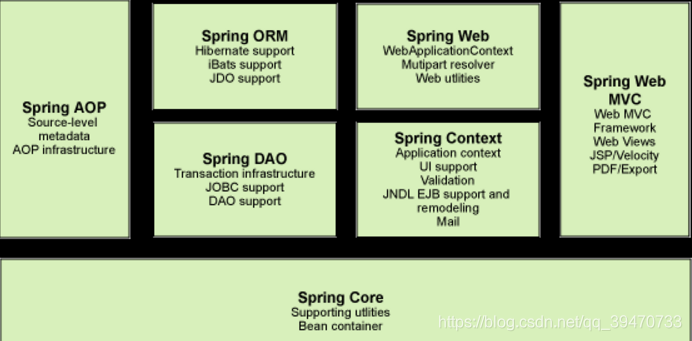
核心容器(Spring Core)
核心容器提供Spring框架的基本功能。Spring以bean的方式组织和管理Java应用中的各个组件及其关系。Spring使用BeanFactory来产生和管理Bean,它是工厂模式的实现。BeanFactory使用控制反转(IoC)模式将应用的配置和依赖性规范与实际的应用程序代码分开。
应用上下文(Spring Context)
Spring上下文是一个配置文件,向Spring框架提供上下文信息。Spring上下文包括企业服务,如JNDI、EJB、电子邮件、国际化、校验和调度功能。
Spring面向切面编程(Spring AOP)
通过配置管理特性,Spring AOP 模块直接将面向方面的编程功能集成到了 Spring框架中。所以,可以很容易地使 Spring框架管理的任何对象支持 AOP。Spring AOP 模块为基于 Spring 的应用程序中的对象提供了事务管理服务。通过使用 Spring AOP,不用依赖 EJB 组件,就可以将声明性事务管理集成到应用程序中。
JDBC和DAO模块(Spring DAO)
JDBC、DAO的抽象层提供了有意义的异常层次结构,可用该结构来管理异常处理,和不同数据库供应商所抛出的错误信息。异常层次结构简化了错误处理,并且极大的降低了需要编写的代码数量,比如打开和关闭链接。
对象实体映射(Spring ORM)
Spring框架插入了若干个ORM框架,从而提供了ORM对象的关系工具,其中包括了Hibernate、JDO和 IBatis SQL Map等,所有这些都遵从Spring的通用事物和DAO异常层次结构。
Web模块(Spring Web)
Web上下文模块建立在应用程序上下文模块之上,为基于web的应用程序提供了上下文。所以Spring框架支持与Struts集成,web模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。
MVC模块(Spring Web MVC)
MVC框架是一个全功能的构建Web应用程序的MVC实现。通过策略接口,MVC框架变成为高度可配置的。MVC容纳了大量视图技术,其中包括JSP、POI等,模型来有JavaBean来构成,存放于m当中,而视图是一个街口,负责实现模型,控制器表示逻辑代码,由c的事情。Spring框架的功能可以用在任何J2EE服务器当中,大多数功能也适用于不受管理的环境。Spring的核心要点就是支持不绑定到特定J2EE服务的可重用业务和数据的访问的对象,毫无疑问这样的对象可以在不同的J2EE环境,独立应用程序和测试环境之间重用。
15、StackOverflowError是什么,在什么情况下会出现。
每一个 JVM 线程都拥有一个私有的 JVM 线程栈,用于存放当前线程的 JVM 栈帧(包括被调用函数的参数、局部变量和返回地址等)。如果某个线程的线程栈空间被耗尽,没有足够资源分配给新创建的栈帧,就会抛出 java.lang.StackOverflowError 错误。
常见的解决方法包括以下几种:
- 修复引发无限递归调用的异常代码, 通过程序抛出的异常堆栈,找出不断重复的代码行,按图索骥,修复无限递归 Bug。
- 排查是否存在类之间的循环依赖。
- 排查是否存在在一个类中对当前类进行实例化,并作为该类的实例变量。
- 通过 JVM 启动参数 -Xss 增加线程栈内存空间, 某些正常使用场景需要执行大量方法或包含大量局部变量,这时可以适当地提高线程栈空间限制,例如通过配置 -Xss2m 将线程栈空间调整为 2 mb。
线程栈的默认大小依赖于操作系统、JVM 版本和供应商,常见的默认配置如下表所示:
| JVM 版本 | 线程栈默认大小 |
| Sparc 32-bit JVM | 512 kb |
| Sparc 64-bit JVM | 1024 kb |
| x86 Solaris/Linux 32-bit JVM | 320 kb |
| x86 Solaris/Linux 64-bit JVM | 1024 kb |
| Windows 32-bit JVM | 320 kb |
| Windows 64-bit JVM | 1024 kb |
16、mysql的索引你知道哪些
普通索引,唯一索引,联合索引,全文索引,空间索引
17、mysql关于多列索引失效的问题,mysql什么情况下索引会失效,举其他的几个例子
- 1) 查询的数量是大表的大部分,应该是30%以上;
- 2) 查询条件在索引列上使用函数或者对索引列进行运算,运算包括(+,-,*,/,! 等) 错误的例子:select * from test where id-1=9; 正确的例子:select * from test where id=10,如果需要对索引列进行运算,可以建立函数索引;
- 3) 对小表(少数据量)查询;
- 4)隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误. 由于表的字段tu_mdn定义为varchar2(20),但在查询时把该字段作为number类型以where条件传给Oracle,这样会导致索引失效. 错误的例子:select * from test where tu_mdn=13333333333; 正确的例子:select * from test where tu_mdn='13333333333';
- 5) <> / >,<,(有时会用到,有时不会) ;
- 6) not in、not exist、like "%_" 百分号在前;
- 7) 单独引用复合索引里非第一位置的索引列(第一索引列没有值);
- 8) 当变量采用的是times变量,而表的字段采用的是date变量时.或相反情况。
- 9) B-tree索引 is null不会走,is not null会走,位图索引 is null,is not null 都会走
- 10) 联合索引 is not null 只要在建立的索引列(不分先后)都会走, in null时 必须要和建立索引第一列一起使用,当建立索引第一位置条件是is null 时,其他建立索引的列可以是is null(但必须在所有列 都满足is null的时候),或者=一个值; 当建立索引的第一位置是=一个值时,其他索引列可以是任何情况(包括is null =一个值),以上两种情况索引都会走。其他情况不会走。
17、B树B+树的区别
B-Tree
- 根节点至少有两个子节点;
- 每个节点有M-1个key,并且以升序排列;
- 位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间;
- 其它节点至少有M/2个子节点;
B+Tree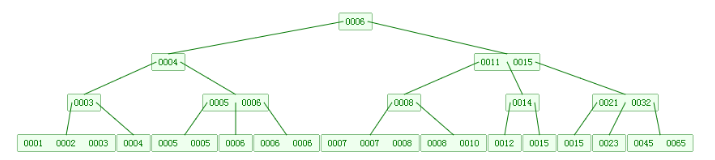
- 有k个子结点的结点必然有k个关键码;
- 非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中;
- 树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录;
- 由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据也具有更好的缓存命中率;
- B+树的叶子结点都是相链的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好;
16、知不知道dubbo 请参考:https://blog.csdn.net/qq_39470733/category_10246528.html
17、redis的数据结构知道哪些 请参考:https://blog.csdn.net/qq_39470733/category_7793435.html
18、XSS攻击和SQLl注入 请参考:https://blog.csdn.net/qq_39470733/category_8783087.html
如有披露或问题欢迎留言或者入群探讨














 2445
2445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









