









1.数据结构与算法
1.数据结构
数据结构是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合。
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
1.数据结构的基本功能
- 如何插入一条新的数据项
- 如何寻找某一特定的数据项
- 如何删除某一特定的数据项
- 如何迭代的访问各个数据项,以便进行显示或其他操作
2.常用的数据结构
- 数组array
数组是相同数据类型的元素按一定顺序排列的集合,是一块连续的内存空间。数组的优点是:get和set操作时间上都是O(1)的;缺点是:add和remove操作时间上都是O(N)的。
Java中,Array就是数组,此外,ArrayList使用了数组Array作为其实现基础,它和一般的Array相比,最大的好处是,我们在添加元素时不必考虑越界,元素超出数组容量时,它会自动扩张保证容量。
Vector和ArrayList相比,主要差别就在于多了一个线程安全性,但是效率比较低下。如今java.util.concurrent包提供了许多线程安全的集合类(比如 LinkedBlockingQueue),所以不必再使用Vector了。
int[] ints = new int[10];
ints[0] = 5;//set
int a=ints[2];//get
int len = ints.length;//数组长度
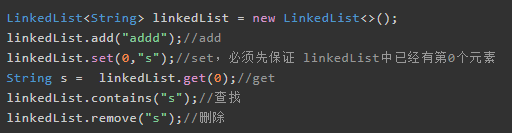
- 链表linkedlist
链表是一种非连续、非顺序的结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的,链表由一系列结点组成。链表的优点是:add和remove操作时间上都是O(1)的;缺点是:get和set操作时间上都是O(N)的,而且需要额外的空间存储指向其他数据地址的项。
查找操作对于未排序的数组和链表时间上都是O(N)。
Java中,LinkedList 使用链表作为其基础实现。
- 队列queue
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端进行删除操作,而在表的后端进行插入操作,亦即所谓的先进先出(FIFO)。
Java中,LinkedList实现了Deque,可以做为双向队列(自然也可以用作单向队列)。另外PriorityQueue实现了带优先级的队列,亦即队列的每一个元素都有优先级,且元素按照优先级排序。
//以上方法也适用于ArrayList

- 树tree
- 哈希表hash
- 散列表
- 栈stack
- 堆heap
- 图graph
这几种结构优缺点如下:先有个大概印象,后面会详细讲解!!!
PS:我看下面的评论,对于下面所说的数组,插入块,查找、删除慢的特点有疑问。
这里可能是我没有描述清楚,对于数组,你们所说的查找快,我想只是随机查找快,因为知道数组下标,可以按索引获取任意值。但是你要查找某个特定值,对于无序数组,还是需要遍历整个数组,那么查找效率是O(n),效率是很低的(有序数组按照二分查找算法还是很快的)。
插入快,是在数组尾部进行插入,获取到数组的最后一个索引下标,加1进行赋值就可以了。
删除慢,除开尾部删除,在任意中间或者前面删除,后面的元素都要整体进行平移的,所以也是比较慢的。
综上所述:对于数组,随机查找快,数组尾部增删快,其余的操作效率都是很低的

2.算法
算法简单来说就是解决问题的步骤。
在Java中,算法通常都是由类的方法来实现的。前面的数据结构,比如链表为啥插入、删除快,而查找慢,平衡的二叉树插入、删除、查找都快,这都是实现这些数据结构的算法所造成的。后面我们讲的各种排序实现也是算法范畴的重要领域。
一、算法的五个特征
①、有穷性:对于任意一组合法输入值,在执行又穷步骤之后一定能结束,即:算法中的每个步骤都能在有限时间内完成。
②、确定性:在每种情况下所应执行的操作,在算法中都有确切的规定,使算法的执行者或阅读者都能明确其含义及如何执行。并且在任何条件下,算法都只有一条执行路径。
③、可行性:算法中的所有操作都必须足够基本,都可以通过已经实现的基本操作运算有限次实现之。
④、有输入:作为算法加工对象的量值,通常体现在算法当中的一组变量。有些输入量需要在算法执行的过程中输入,而有的算法表面上可以没有输入,实际上已被嵌入算法之中。
⑤、有输出:它是一组与“输入”有确定关系的量值,是算法进行信息加工后得到的结果,这种确定关系即为算法功能。
二、算法的设计原则
①、正确性:首先,算法应当满足以特定的“规则说明”方式给出的需求。其次,对算法是否“正确”的理解可以有以下四个层次:
一、程序语法错误。
二、程序对于几组输入数据能够得出满足需要的结果。
三、程序对于精心选择的、典型、苛刻切带有刁难性的几组输入数据能够得出满足要求的结果。
四、程序对于一切合法的输入数据都能得到满足要求的结果。
PS:通常以第 三 层意义的正确性作为衡量一个算法是否合格的标准。
②、可读性:算法为了人的阅读与交流,其次才是计算机执行。因此算法应该易于人的理解;另一方面,晦涩难懂的程序易于隐藏较多的错误而难以调试。
③、健壮性:当输入的数据非法时,算法应当恰当的做出反应或进行相应处理,而不是产生莫名其妙的输出结果。并且,处理出错的方法不应是中断程序执行,而是应当返回一个表示错误或错误性质的值,以便在更高的抽象层次上进行处理。
④、高效率与低存储量需求:通常算法效率值得是算法执行时间;存储量是指算法执行过程中所需要的最大存储空间,两者都与问题的规模有关。
前面三点 正确性,可读性和健壮性相信都好理解。对于第四点算法的执行效率和存储量,我们知道比较算法的时候,可能会说“A算法比B算法快两倍”之类的话,但实际上这种说法没有任何意义。因为当数据项个数发生变化时,A算法和B算法的效率比例也会发生变化,比如数据项增加了50%,可能A算法比B算法快三倍,但是如果数据项减少了50%,可能A算法和B算法速度一样。所以描述算法的速度必须要和数据项的个数联系起来。也就是“大O”表示法,它是一种算法复杂度的相对表示方式,这里我简单介绍一下,后面会根据具体的算法来描述。
相对(relative):你只能比较相同的事物。你不能把一个做算数乘法的算法和排序整数列表的算法进行比较。但是,比较2个算法所做的算术操作(一个做乘法,一个做加法)将会告诉你一些有意义的东西;
表示(representation):大O(用它最简单的形式)把算法间的比较简化为了一个单一变量。这个变量的选择基于观察或假设。例如,排序算法之间的对比通常是基于比较操作(比较2个结点来决定这2个结点的相对顺序)。这里面就假设了比较操作的计算开销很大。但是,如果比较操作的计算开销不大,而交换操作的计算开销很大,又会怎么样呢?这就改变了先前的比较方式;
复杂度(complexity):如果排序10,000个元素花费了我1秒,那么排序1百万个元素会花多少时间?在这个例子里,复杂度就是相对其他东西的度量结果。
然后我们在说说算法的存储量,包括:
程序本身所占空间;
输入数据所占空间;
辅助变量所占空间;
一个算法的效率越高越好,而存储量是越低越好。















 97
97











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









