






报错
2021/11/20 16:39:51 C:/Users/asus/3D Objects/个人项目/go网络编程测试/GormTest/主.go:45 Error 1300: Invalid utf8 character string: ‘a\xE6\xB5\x8B\xEF\xBF\xBD\xEF\xBF\xBD\x95’
[5.002ms] [rows:0] CREATE TABLE a测��� (id bigint unsigned AUTO_INCREMENT,created_at datetime NULL,updated_at datetime NULL,deleted_at datetime NULL,uid bigint unsigned,a数��� varchar(256),PRIMARY KEY (id),INDEX idx_a测���_deleted_at (deleted_at))ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
2021/11/20 16:39:51 C:/Users/asus/3D Objects/个人项目/go网络编程测试/GormTest/主.go:48 Error 1300: Invalid utf8 character string: ‘a\xE6\xB5\x8B\xEF\xBF\xBD\xEF\xBF\xBD\x95’
[14.143ms] [rows:0] INSERT INTO a测��� (created_at,updated_at,deleted_at,uid,a数���) VALUES (‘2021-11-20 16:39:51.916’,‘2021-11-20 16:39:51.916’,NULL,100,‘寻觅’)
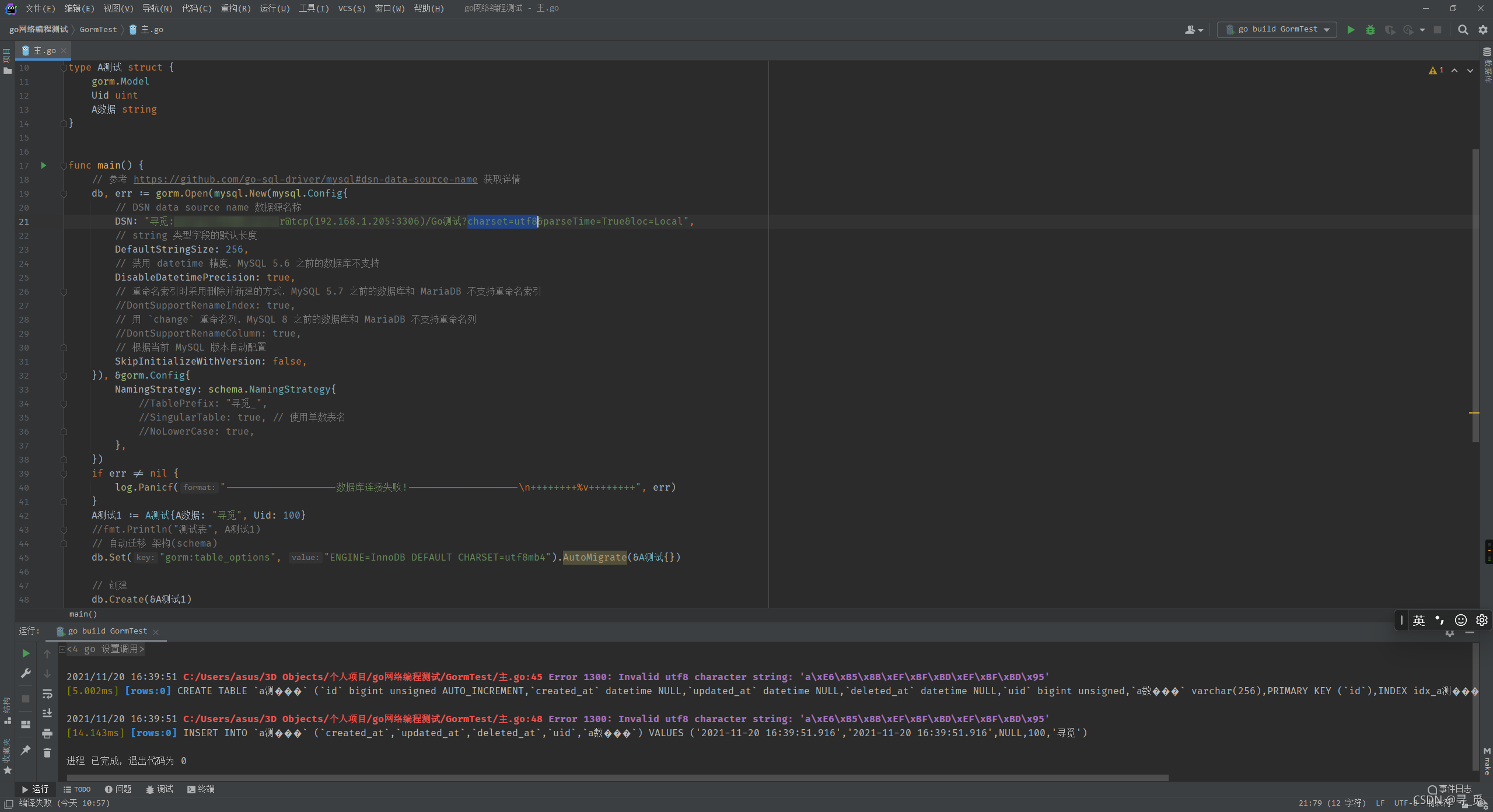
只是单纯的阻止报错的话,可以把DSN中的charset=utf8换成charset=utf8mb4即可,但这还是会乱码解决了但没完全解决。
解决方案
- 使用数字或者字母结束。
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
"gorm.io/gorm/schema"
"log"
)
type A测试a struct {
gorm.Model
Uid uint
A数据a string
}
func main() {
db, err := gorm.Open(mysql.New(mysql.Config{
// DSN data source name 数据源名称
DSN: "用户名:密码@tcp(ip:端口)/数据库?charset=utf8mb4&parseTime=True&loc=Local",
// string 类型字段的默认长度
DefaultStringSize: 256,
}), &gorm.Config{})
if err != nil {
log.Panicf("-------------------数据库连接失败!-------------------\n++++++++%v++++++++", err)
}
A测试1 := A测试a{A数据a: "寻觅", Uid: 100}
// 自动迁移 架构(schema)
db.Set("gorm:table_options", "ENGINE=InnoDB DEFAULT CHARSET=utf8mb4").AutoMigrate(&A测试a{})
// 创建
db.Create(&A测试1)
}
不过这样配置出来的表名和表头看上会比较难看,如果不介意的话可以使用这种方法。
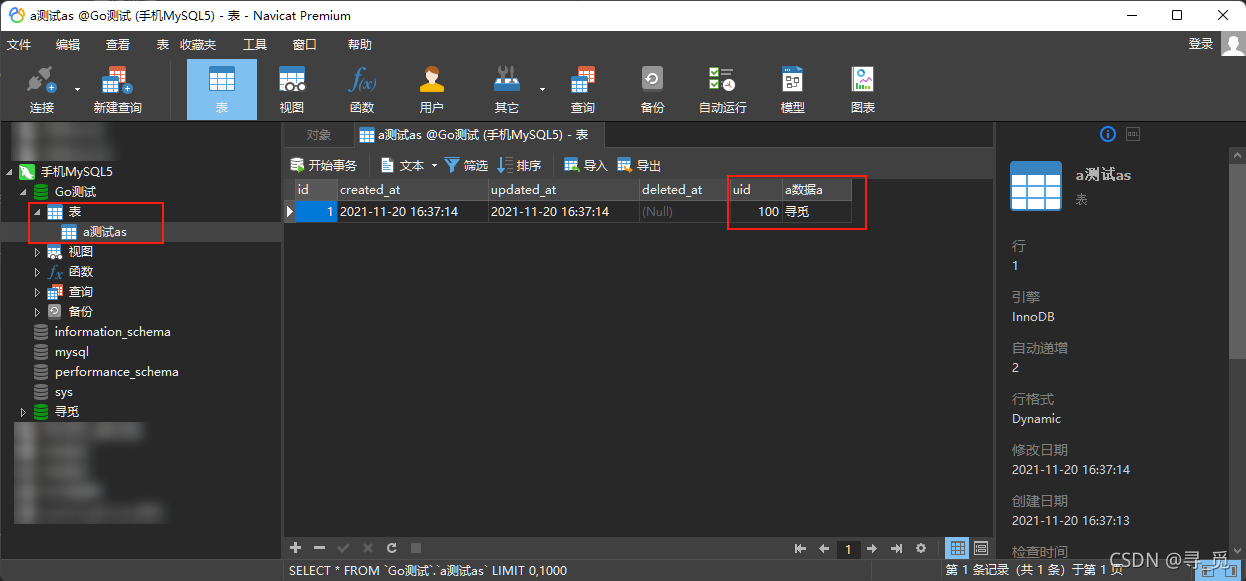
2. 关闭大写自动转小写功能NoLowerCase: true,
package main
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
"gorm.io/gorm/schema"
"log"
)
type A测试 struct {
gorm.Model
Uid uint
A数据 string
}
func main() {
db, err := gorm.Open(mysql.New(mysql.Config{
// DSN data source name 数据源名称
DSN: "寻觅:weh*gxu*RXW8ujp3cur@tcp(192.168.1.205:3306)/Go测试?charset=utf8mb4&parseTime=True&loc=Local",
// string 类型字段的默认长度
DefaultStringSize: 256,
SkipInitializeWithVersion: false,
}), &gorm.Config{
NamingStrategy: schema.NamingStrategy{
// 这里可以加个前缀
//TablePrefix: "寻觅_",
// 使用单数表名,就是不让表名自动加s,看起来比较舒服
SingularTable: true,
// 关闭大写转小写,这是关键,启动这个就不在会导致中文乱码!
NoLowerCase: true,
},
})
if err != nil {
log.Panicf("-------------------数据库连接失败!-------------------\n++++++++%v++++++++", err)
}
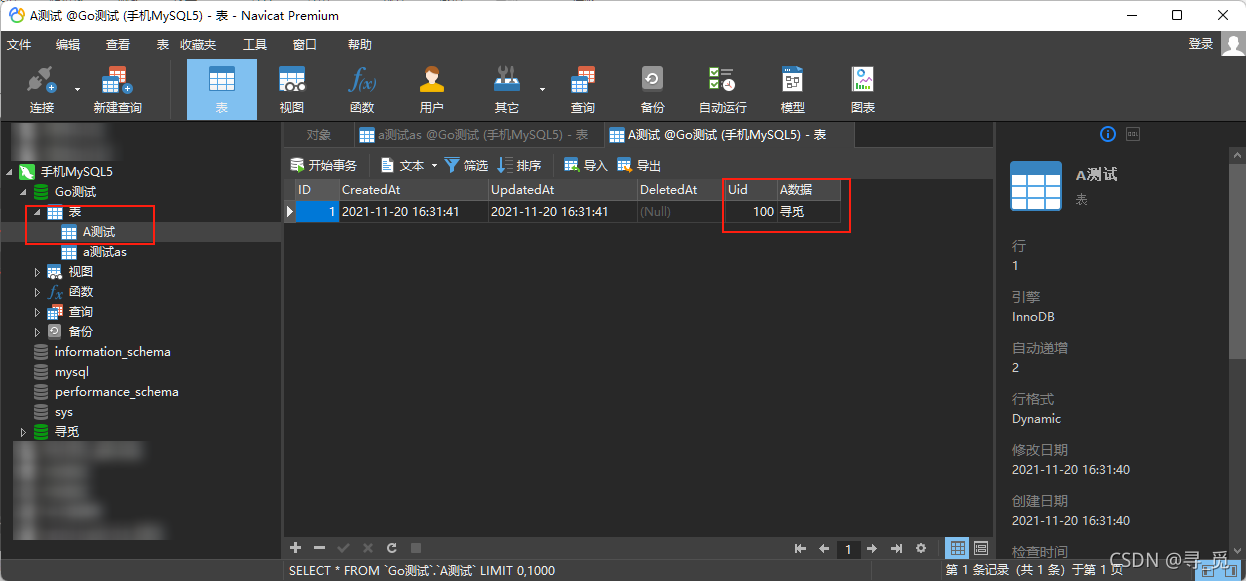
A测试1 := A测试{A数据: "寻觅", Uid: 100}
// 自动迁移 架构(schema)
db.Set("gorm:table_options", "ENGINE=InnoDB DEFAULT CHARSET=utf8mb4").AutoMigrate(&A测试{})
// 创建
db.Create(&A测试1)
}
原因分析
经过对gorm的代码审计和debug测试,导致这个乱码的是下列代码,在遍历的时候直接生硬的少取了一位,但因为中文的编码在这里是占用了三个字节的,这样生硬的减去一个字节位就导致了乱码,然后进一步引发了报错。
var (
value = commonInitialismsReplacer.Replace(name)
buf strings.Builder
lastCase, nextCase, nextNumber bool // upper case == true
curCase = value[0] <= 'Z' && value[0] >= 'A'
)
// 就是这里的[:len(value)-1]导致的报错
// go直接遍历中文会将中文转换成`UTF-16BE`编码的十进制用int32表达
for i, v := range value[:len(value)-1] {
nextCase = value[i+1] <= 'Z' && value[i+1] >= 'A'
nextNumber = value[i+1] >= '0' && value[i+1] <= '9'
if curCase {
if lastCase && (nextCase || nextNumber) {
buf.WriteRune(v + 32)
} else {
if i > 0 && value[i-1] != '_' && value[i+1] != '_' {
buf.WriteByte('_')
}
buf.WriteRune(v + 32)
}
} else {
buf.WriteRune(v)
}
lastCase = curCase
curCase = nextCase
}
if curCase {
if !lastCase && len(value) > 1 {
buf.WriteByte('_')
}
buf.WriteByte(value[len(value)-1] + 32)
} else {
buf.WriteByte(value[len(value)-1])
}
ret := buf.String()
return ret
这里我们把这块导致乱码的代码单独拿出来看,前两个字符输出的都是没有问题的,a占用一个字节,寻占用三个字节(这里的占用是utf-8),正常情况下觅也应该占用三个字节,但是因为这里少取一个,导致他成了两个字符
package main
import "fmt"
func main() {
value := "a寻觅"
for i, v := range value[:len(value)-1] {
fmt.Println("--------", i, v)
}
}
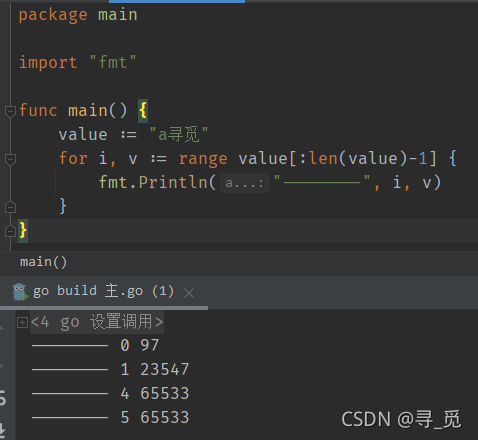
这两个字符是无法组成一个正常字的,所以这里输出变成了65533,Unicode一般无法理解的字符才会用这个来表示。
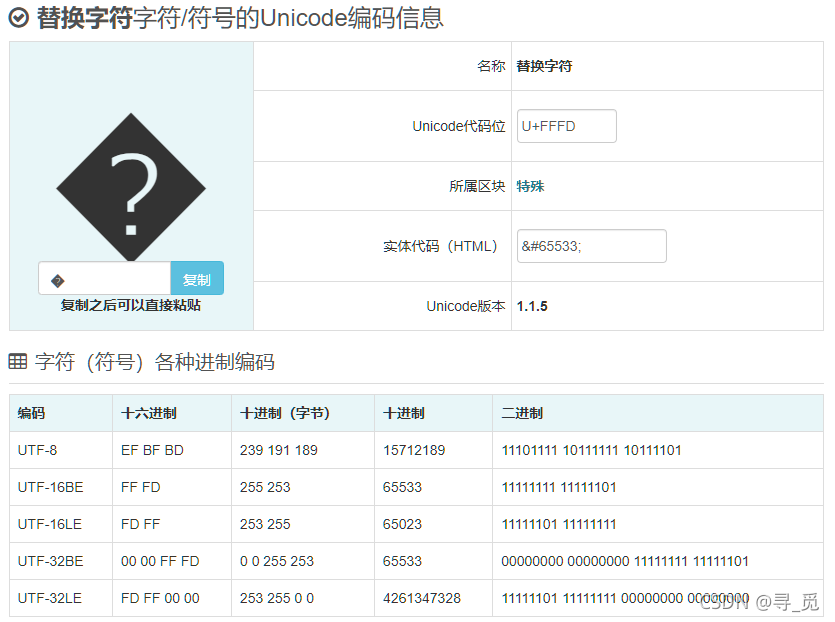
因为这是大小写转换对最后一位处理不当导致的,所以我们直接关掉大小写转换功能或者把最后一位改成ascii编码即可解决。















 3242
3242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











