







workflow之shell-sqoop脚本实录
前面讲解了sqoop的密码明文问题解决与sqoop导入分库分表mysql数据问题解决,那么这里就详细介绍下在hue上配置shell-sqoop脚本时所遇到的问题!这里的shell脚本会以上篇的脚本为例!
一、配置hue的workflow
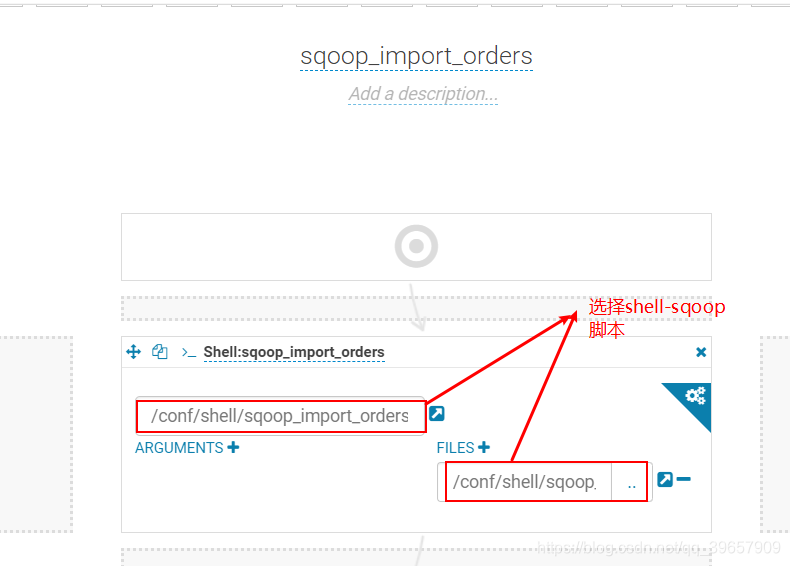
二、所遇问题
2.1 不能加载mysql驱动
报错如下:
ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.RuntimeException: Could not load db driver class: com.mysql.jdbc.Driver
java.lang.RuntimeException: Could not load db driver class: com.mysql.jdbc.Driver
at org.apache.sqoop.manager.SqlManager.makeConnection(SqlManager.java:874)
at org.apache.sqoop.manager.GenericJdbcManager.getConnection(GenericJdbcManager.java:52)
at org.apache.sqoop.manager.SqlManager.execute(SqlManager.java:762)
at org.apache.sqoop.manager.SqlManager.execute(SqlManager.java:785)
at org.apache.sqoop.manager.SqlManager.getColumnInfoForRawQuery(SqlManager.java:288)
at org.apache.sqoop.manager.SqlManager.getColumnTypesForRawQuery(SqlManager.java:259)
at org.apache.sqoop.manager.SqlManager.getColumnTypes(SqlManager.java:245)
at org.apache.sqoop.manager.ConnManager.getColumnTypes(ConnManager.java:333)
at org.apache.sqoop.orm.ClassWriter.getColumnTypes(ClassWriter.java:1858)
at org.apache.sqoop.orm.ClassWriter.generate(ClassWriter.java:1657)
at org.apache.sqoop.tool.CodeGenTool.generateORM(CodeGenTool.java:106)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:494)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:621)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
问题解决:由于是使用的shell脚本进行的导入所以回去SQOOP_HOME的lib目录下去加载mysql驱动,所以这里只需要把mysql驱动拷贝到sqoop的lib目录下,然后重启服务就好了。操作过程如下
# 获取驱动
wget http://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.46.tar.gz/from/http://cdn.mysql.com/
# 拷贝驱动到SQOOP_HOME的lib目录下
cp /usr/share/java/mysql-connector-java-5.1.46.jar /data/cloudera/parcels/CDH-5.14.4-1.cdh5.14.4.p0.3/lib/sqoop/lib
# 分发每台机器,xsync这里是自定义的分发脚本,参考之前博客hadoop,也可使用scp命名去进行分发
xsync /data/cloudera/parcels/CDH-5.14.4-1.cdh5.14.4.p0.3/lib/sqoop/lib/mysql-connector-java-5.1.46.jar
2.2 调度时报错文件不存在
报错如下:
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.io.FileNotFoundException: File does not exist: hdfs://nameservice1/user/admin/.staging/job_1590901453442_0029/job.splitmetainfo
at org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl$InitTransition.createSplits(JobImpl.java:1580)
at org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl$InitTransition.transition(JobImpl.java:1444)
at org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl$InitTransition.transition(JobImpl.java:1402)
at org.apache.hadoop.yarn.state.StateMachineFactory$MultipleInternalArc.doTransition(StateMachineFactory.java:385)
at org.apache.hadoop.yarn.state.StateMachineFactory.doTransition(StateMachineFactory.java:302)
at org.apache.hadoop.yarn.state.StateMachineFactory.access$300(StateMachineFactory.java:46)
at org.apache.hadoop.yarn.state.StateMachineFactory$InternalStateMachine.doTransition(StateMachineFactory.java:448)
at org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl.handle(JobImpl.java:996)
at org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl.handle(JobImpl.java:138)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster$JobEventDispatcher.handle(MRAppMaster.java:1366)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster.serviceStart(MRAppMaster.java:1142)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster$5.run(MRAppMaster.java:1573)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster.initAndStartAppMaster(MRAppMaster.java:1569)
at org.apache.hadoop.mapreduce.v2.app.MRAppMaster.main(MRAppMaster.java:1502)
Caused by: java.io.FileNotFoundException: File does not exist: hdfs://nameservice1/user/admin/.staging/job_1590901453442_0029/job.splitmetainfo
at org.apache.hadoop.hdfs.DistributedFileSystem$20.doCall(DistributedFileSystem.java:1269)
at org.apache.hadoop.hdfs.DistributedFileSystem$20.doCall(DistributedFileSystem.java:1261)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1261)
at org.apache.hadoop.mapreduce.split.SplitMetaInfoReader.readSplitMetaInfo(SplitMetaInfoReader.java:51)
at org.apache.hadoop.mapreduce.v2.app.job.impl.JobImpl$InitTransition.createSplits(JobImpl.java:1575)
... 17 more
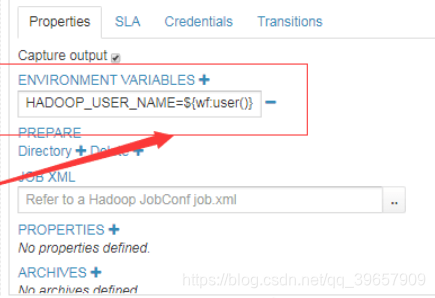
问题解决:由于hue执行shell脚本时是随机发往一台集群中的机器执行,而当我们运行该任务时,任务会在当前hue用户下创建job等任务信息,但是在下发至集群机器执行时没有指定执行任务的用户使其无法获取任务信息从而提示文件不存在。具体解决如下:
HADOOP_USER_NAME=${wf:user()}
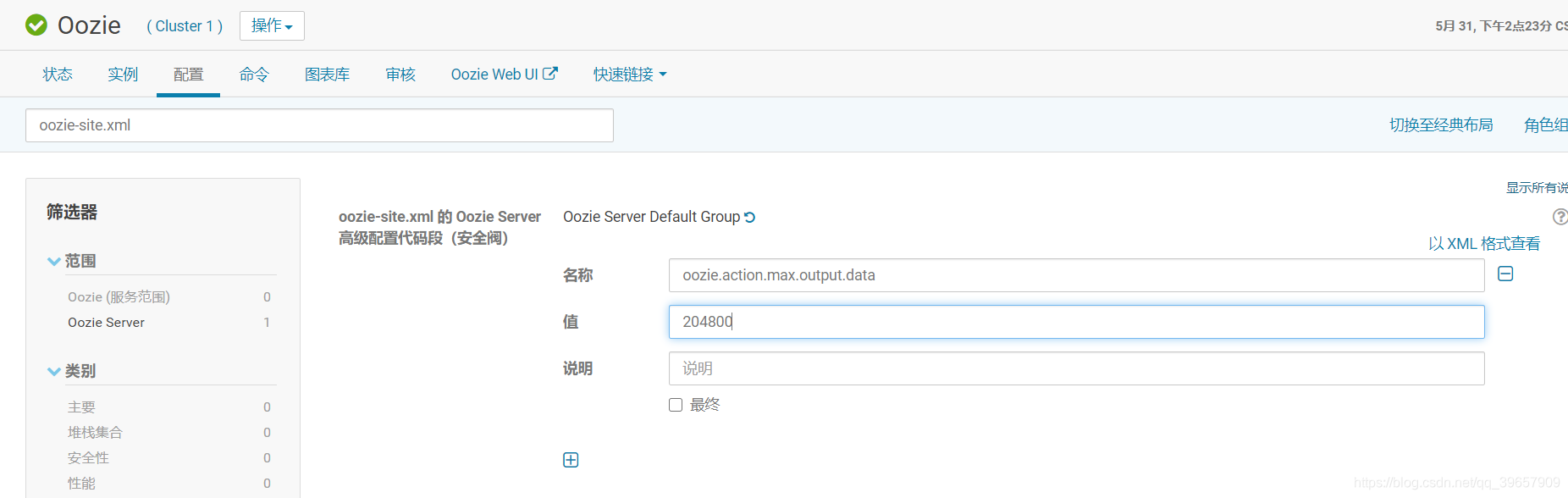
2.3 oozie调度脚本java.io.IOException: output.properties data exceeds its limit [2048]
shell脚本中一次提交的作业量太大,其中包含的信息超过oozie launcher一次容许的最大值2K(2K是默认值)
问题解决:CDH集群中修改 oozie-site.xml 的 Oozie Server 高级配置代码段(安全阀),然后重启,修改如下:
<property>
<name>oozie.action.max.output.data</name>
<value>204800</value>
</property>














 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









