






The extended Kalman Filter
Kalman Filter is build according to the assumptions of f linear state transitions and linear measurements with added Gaussian noise,but which are rarely fulfilled in practice.The extended Kalman filter (EKF) overcomes one of these assumptions: the linearity assumption.Here the assumption is that the next state probability and the measurement probabilities are governed by nonlinear functions g g g and h h h,respectively:
x t = g ( u t , x t − 1 ) + ε t z t = h ( x t ) + δ t (1) \begin{aligned} x_{t} &=g\left(u_{t}, x_{t-1}\right)+\varepsilon_{t} \tag{1} \\ z_{t} &=h\left(x_{t}\right)+\delta_{t} \end{aligned} xtzt=g(ut,xt−1)+εt=h(xt)+δt(1)
The function g g g replace the matrixs A A A and B B B ,and the h h h replace the matrix H H H.Unfortunately,the belief is no longer a Gaussian.In fact, performing the belief update exactly is usually impossible.
(写不下去了,切换中文,想想写paper多难。。。)
Linearization Via Taylor Expansion
EKF使用称为 Taylor Expansion 的方法来线性化非线性函数。泰勒展开就是在某点的值和导数构造一个线性approximation。斜率是对某点的偏导数:
g ′ ( u t , x t − 1 ) : = ∂ g ( u t , x t − 1 ) ∂ x t − 1 \begin{aligned}g^{\prime}\left(u_{t}, x_{t-1}\right):=\frac{\partial g\left(u_{t}, x_{t-1}\right)}{\partial x_{t-1}}\end{aligned} g′(ut,xt−1):=∂xt−1∂g(ut,xt−1)
其中 g g g 的值和斜率是取决于 g g g 的参数的,选取的逻辑就是在线性化的时候最有可能的值,对高斯函数,最有可能的状态就是后验的均值 μ t − 1 \mu_{t-1} μt−1 。换句话说就是 g g g 在 μ t − 1 \mu_{t-1} μt−1 处 approximate:
g ( u t , x t − 1 ) ≈ g ( u t , μ t − 1 ) + g ′ ( u t , μ t − 1 ) ⏟ = : G t ( x t − 1 − μ t − 1 ) = g ( u t , μ t − 1 ) + G t ( x t − 1 − μ t − 1 ) \begin{aligned} g\left(u_{t}, x_{t-1}\right) & \approx g\left(u_{t}, \mu_{t-1}\right)+\underbrace{g^{\prime}\left(u_{t}, \mu_{t-1}\right)}_{=: G_{t}}\left(x_{t-1}-\mu_{t-1}\right) \\ &=g\left(u_{t}, \mu_{t-1}\right)+G_{t}\left(x_{t-1}-\mu_{t-1}\right) \end{aligned} g(ut,xt−1)≈g(ut,μt−1)+=:Gt g′(ut,μt−1)(xt−1−μt−1)=g(ut,μt−1)+Gt(xt−1−μt−1)
写成概率的表达式可以近似为;
p ( x t ∣ u t , x t − 1 ) ≈ det ( 2 π R t ) − 1 2 exp { − 1 2 [ x t − g ( u t , μ t − 1 ) − G t ( x t − 1 − μ t − 1 ) ] T R t − 1 [ x t − g ( u t , μ t − 1 ) − G t ( x t − 1 − μ t − 1 ) ] } \begin{array}{l} p\left(x_{t} \mid u_{t}, x_{t-1}\right) \\ \begin{aligned} \approx & \operatorname{det}\left(2 \pi R_{t}\right)^{-\frac{1}{2}} \exp \left\{-\frac{1}{2}\left[x_{t}-g\left(u_{t}, \mu_{t-1}\right)-G_{t}\left(x_{t-1}-\mu_{t-1}\right)\right]^{T}\right.\\ &\left.R_{t}^{-1}\left[x_{t}-g\left(u_{t}, \mu_{t-1}\right)-G_{t}\left(x_{t-1}-\mu_{t-1}\right)\right]\right\} \end{aligned} \end{array} p(xt∣ut,xt−1)≈det(2πRt)−21exp{−21[xt−g(ut,μt−1)−Gt(xt−1−μt−1)]TRt−1[xt−g(ut,μt−1)−Gt(xt−1−μt−1)]}
对测量函数同样线性化,这里的泰勒展开取在 μ ˉ t \bar{\mu}_{t} μˉt 这附近:
h ( x t ) ≈ h ( μ ˉ t ) + h ′ ( μ ˉ t ) ⏟ = : H t ( x t − μ ˉ t ) = h ( μ ˉ t ) + H t ( x t − μ ˉ t ) \begin{aligned} h\left(x_{t}\right) & \approx h\left(\bar{\mu}_{t}\right)+\underbrace{h^{\prime}\left(\bar{\mu}_{t}\right)}_{=: H_{t}}\left(x_{t}-\bar{\mu}_{t}\right) \\ &=h\left(\bar{\mu}_{t}\right)+H_{t}\left(x_{t}-\bar{\mu}_{t}\right) \end{aligned} h(xt)≈h(μˉt)+=:Ht h′(μˉt)(xt−μˉt)=h(μˉt)+Ht(xt−μˉt)
写成概率的形式:
p ( z t ∣ x t ) = det ( 2 π Q t ) − 1 2 exp { − 1 2 [ z t − h ( μ ˉ t ) − H t ( x t − μ ˉ t ) ] T Q t − 1 [ z t − h ( μ ˉ t ) − H t ( x t − μ ˉ t ) ] } (7) \begin{aligned} p\left(z_{t} \mid x_{t}\right)=& \operatorname{det}\left(2 \pi Q_{t}\right)^{-\frac{1}{2}} \exp \left\{-\frac{1}{2}\left[z_{t}-h\left(\bar{\mu}_{t}\right)-H_{t}\left(x_{t}-\bar{\mu}_{t}\right)\right]^{T}\right.\\ &\left.Q_{t}^{-1}\left[z_{t}-h\left(\bar{\mu}_{t}\right)-H_{t}\left(x_{t}-\bar{\mu}_{t}\right)\right]\right\} \end{aligned}\tag{7} p(zt∣xt)=det(2πQt)−21exp{−21[zt−h(μˉt)−Ht(xt−μˉt)]TQt−1[zt−h(μˉt)−Ht(xt−μˉt)]}(7)
看到这么多字母和数字是不是很头晕?没错我也是,我一开始看也完全不知道这些字母什么意思,你就等等,再把EKF的更新公式放出来,就很清晰了。
The algorithm

我们再把熟悉的KF放上来:

如果对这个类型的KF还是不熟悉,那就再放一个肯定熟悉的:
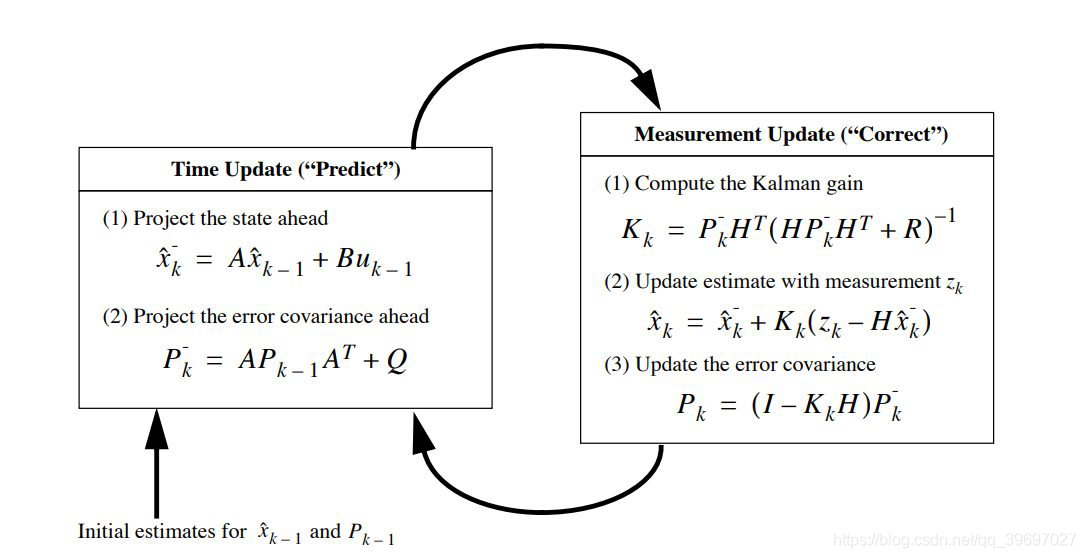
这下对比一下相信已经很熟悉了把,接下来就一个个对应起来理解。第一第二种形式是《Probabilistic Robotics》的,第三种形式是我在这篇intro看到的,第三种看起来更好理解,所以我们就来理一下前两种中字母的关系。
- μ ˉ t \bar{\mu}_{t} μˉt equal to x ^ k − \hat{x}_{k}^{-} x^k− ,predict state。
- μ t \mu_{t} μt equal to x ^ k \hat{x}_{k} x^k ,represent update the state at k k k of estimation with measurement。
- μ t − 1 \mu_{t-1} μt−1 equal to x ^ k − 1 \hat{x}_{k-1} x^k−1 ,represent the state at k − 1 k-1 k−1 of estimation。
- Σ ˉ t \bar{\Sigma}_{t} Σˉt equal to P k − P_{k}^{-} Pk− , a priori estimate error covariance,说人话就是估计的误差协方差矩阵,利用先验的知识,还没有得到观测数据。
- Σ t − 1 \Sigma_{t-1} Σt−1 equal to P k − 1 P_{k-1} Pk−1 ,a posteriori estimate error covariance,说人话就是利用后验估计误差协方差矩阵,就是利用获得的观测数据更新了误差协方差矩阵。
- G t G_{t} Gt , A t A_t At and A A A , A A A present a constant transform matrix,but A t A_t At present a dynamic, G t G_t Gt is a Jacobian matrix,what is Jacobian matrix?Partial derivative of variable matrix.
- H t H_t Ht and H H H and C t C_t Ct Jacobian H t H_t Ht corresponds to C t C_t Ct .
解释完每个变量的意思,就来看看区别:主要的区别是在Predict上:
μ ˉ t = g ( u t , μ t − 1 ) Σ ˉ t = G t Σ t − 1 G t T + R t \begin{array}{l} \bar{\mu}_{t}=g\left(u_{t}, \mu_{t-1}\right) \\ \bar{\Sigma}_{t}=G_{t} \Sigma_{t-1} G_{t}^{T}+R_{t} \end{array} μˉt=g(ut,μt−1)Σˉt=GtΣt−1GtT+Rt
其中更新predict state不是线性的关系,而是一个非线性的函数 g g g, error covariance 更新需要算协方差矩阵了。这应该就是扩展卡尔曼和卡尔曼的区别了吧。
总结
最后总结就是扩展卡尔曼是一个在某处线性化的过程,而这个线性化的点就在mean of posterior μ t − 1 \mu_{t-1} μt−1 ,因为在高斯的图形中,这个mean的点附近是概率最集中的点,这句话应该是精髓吧。然后迭代的过程和卡尔曼滤波是一样的。数学证明有能力有时间再看吧。。。














 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









