







word embedding&word2vec
one-hot encoding
编码中编码单词的一种方法是one-hot encoding
eg. 有1000个单词,按照字典顺序排序为"a", “apple”, … , “zoo”。每一个单词可以用一个1000维的向量表示,分别为:
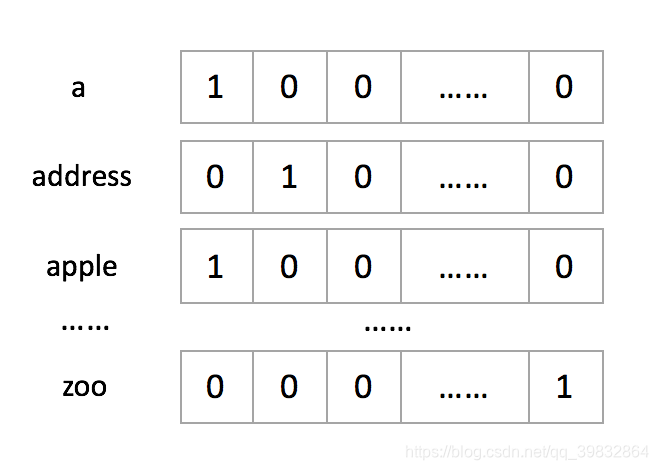
one-hot方式处理数据显然有很多缺点:
- 产生大量冗余稀疏矩阵
- 单词间的关系没有体现
word embedding
我们可以试着将词汇表里面的词语用"Royalty", “Masculinity”, “Femininity”, "Age"表示:
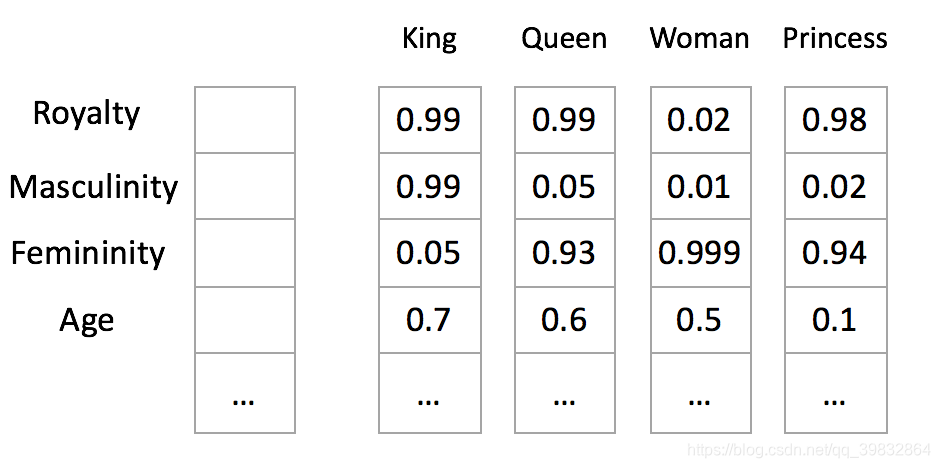
这个过程就是word embedding——将高维词向量嵌入到低维空间。
尽管我们无法具体说出每一个数字的意义。
经过降维操作,使每一个词带有语义关系,我们便可以分析词与词之间的关系。
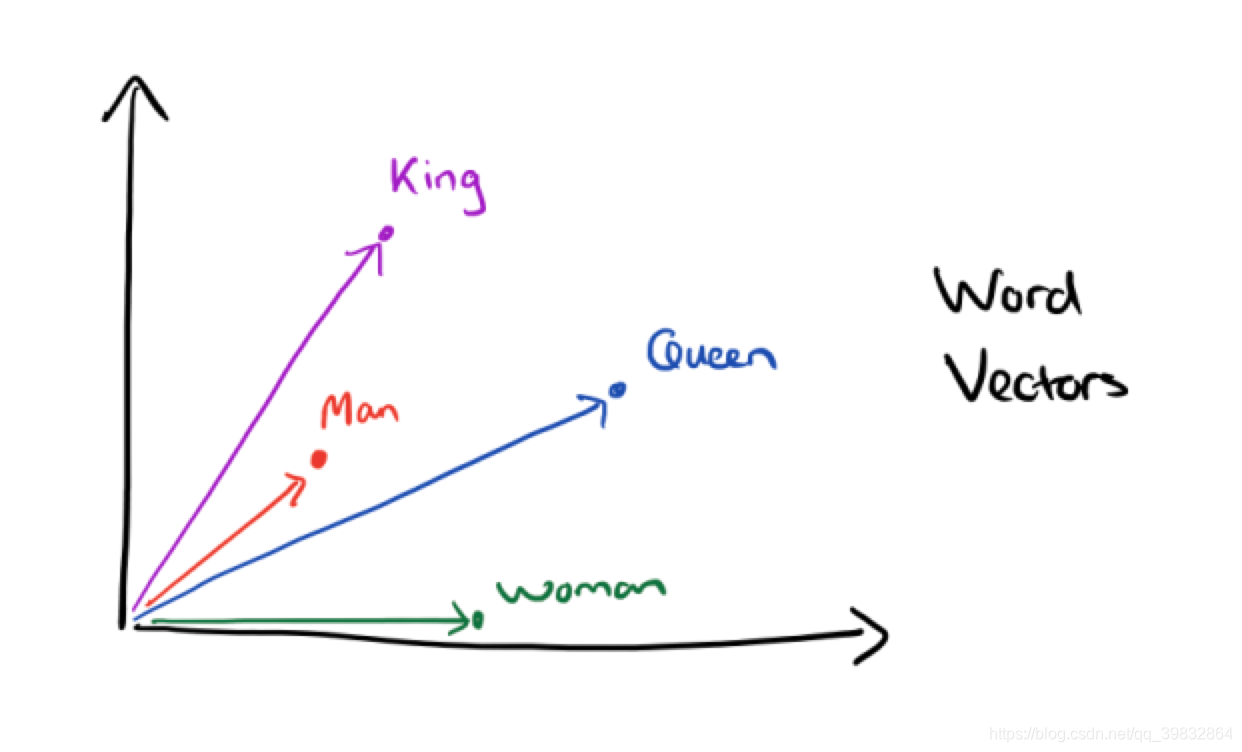
经过研究,一个很有意思的现象产生了,我们可以用数学公式:
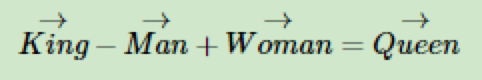
找到四个词语之间的关系。
(普及)softmax函数
百度百科上对softmax函数的解释:
在数学,尤其是概率论和相关领域中,Softmax函数,或称归一化指数函数,是逻辑函数的一种推广。它能将一个含任意实数的K维向量 z “压缩”到另一个K维实向量 σ(z) 中,使得每一个元素的范围都在(0, 1)之间,并且所有元素的和为1。
该函数的形式通常按下面的式子给出: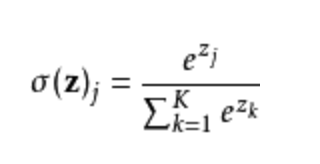
其中,j=1,2,…, K
word2vec
什么是word2vec
word2vec其实是一个简单的神经网络。
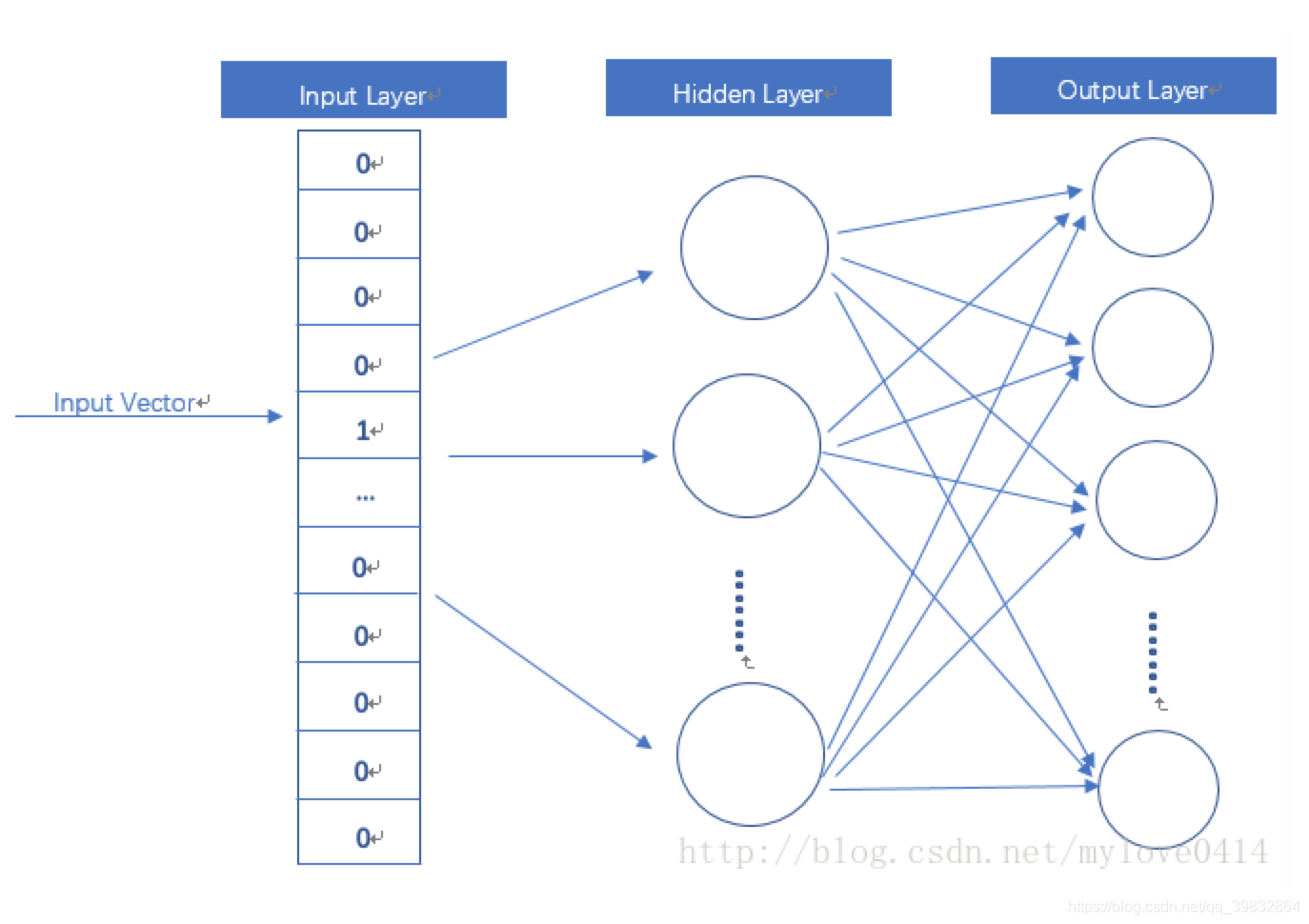
- 输入one-hot Vector
- Hidden Layer没有激活函数(现行单元)
- Output Layer 和Inpyt Layer 维度一样,用的是softmax函数
- 模型训练好以后,并不会用这个模型处理新的任务,而是使用参数。(eg.权重矩阵W)
模型定义输入与输出
有两种方法:
-
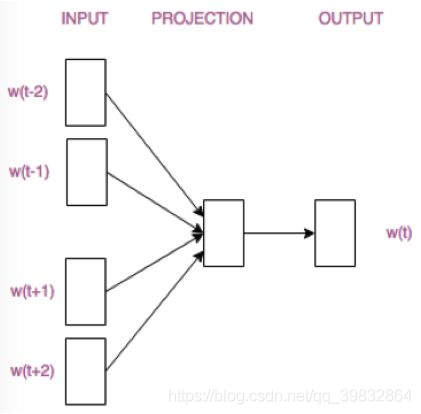
CBOW(Continuous Bag-of-words)
- 输入:某特征词的上下文的词向量
- 输出:这个特征词的词向量 -
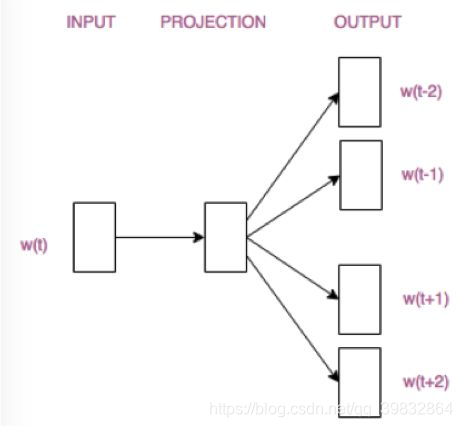
Skip-Gram
- 输入:某个特征词的词向量
- 输出:这个特征词的上下文的词向量
CBOW一般适用于小型语料库;Skip-Gram可以很好地运用在大型语料库中。
CBOW模型:
Skip-Gram模型:
CBOW模型
CBOW模型训练图
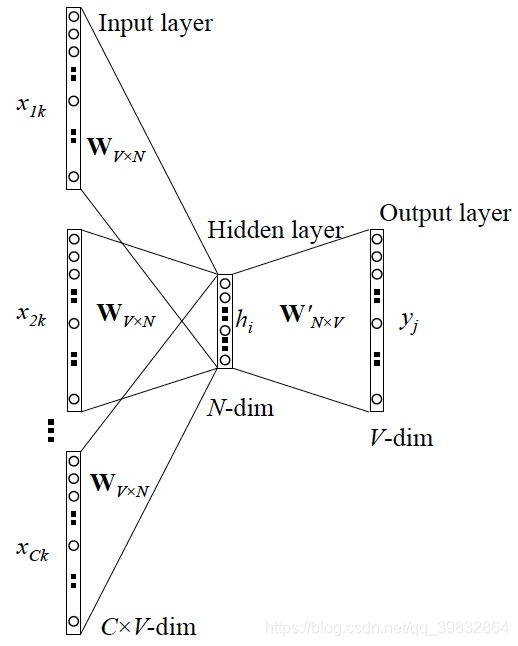
- 输入层:上下文单词的onehot. (假设单词向量空间dim为V,上下文单词个数为C)
- 所有onehot分别乘以共享的输入权重矩阵W. (VN矩阵,N为自己设定的数,初始化权重矩阵W)
- 所得的向量 (因为是onehot所以为向量) 相加求平均作为隐层向量, size为1N.
- 乘以输出权重矩阵W’ (NV)
- 得到向量 (1V) 激活函数处理得到V-dim概率分布
- 概率最大的index所指示的单词为预测出的中间词(target word)与true label的onehot做比较,误差越小越好(根据误差更新权重矩阵)
为了得到更好的权重矩阵,采用梯度下降算法更新W和W’。
训练完毕后,输入层的没一个单词与矩阵W相乘就是我们想要的词向量(word embedding)也叫做look up table。
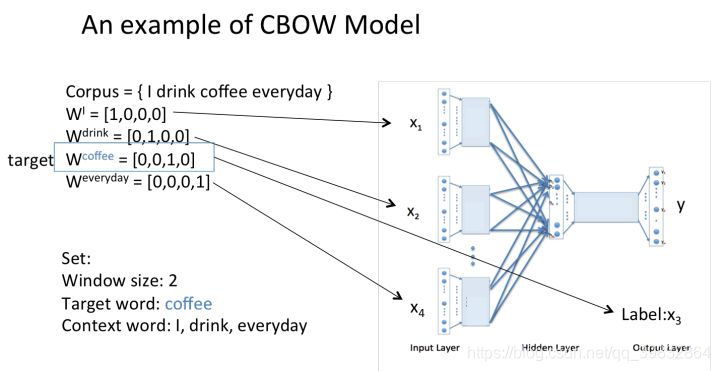
example of CBWO

Skip-Gram模型
Skip-Gram是给定input word来预测上下文。

接下来我们来看看如何训练我们的神经网络。
假如我们有一个句子“The quick brown fox jumps over the lazy dog”。
首先我们选句子中间的一个词作为我们的输入词,例如我们选取“The”作为input word;
有了input word以后,我们再定义一个叫做 skip_window 的参数 (它代表着我们从当前input word的一侧(左边或右边)选取词的数量)。如果我们设置skip_window=2,那么我们最终获得窗口中的词就是[‘The’, ‘quick’,‘brown’]。
skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word.
当skip_window=2,num_skips=2时,我们将会得到两组 Training Samples (input word, output word) ,即 (‘The’, ‘quick’),(‘The’, ‘brown’)。
当然图中的只是一组数据,我们的训练数据有很多这样的句子。
神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词是output word的可能性。例如,input是‘The’, 我们会判断下一个单词是‘quick’的概率。
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。举个栗子,如果我们向神经网络模型中输入一个单词“中国“,那么最终模型的输出概率中,像“英国”, ”俄罗斯“这种相关词的概率将远高于像”苹果“,”蝈蝈“非相关词的概率。因为”英国“,”俄罗斯“在文本中更大可能在”中国“的窗口中出现。我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。
文章参考
https://www.jianshu.com/p/471d9bfbd72f
https://baike.baidu.com/item/Softmax
https://www.jianshu.com/p/da235893e4a5














 3556
3556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









