







基于OCR的身份证要素提取
1赛题简介
1.1赛题背景
我们本次的比赛赛题“基于OCR的身份证要素提取”来自CCF大数据与计算智能大赛(CCF Big Data & Computing Intelligence Contest,简称CCF BDCI)。
身份证影像文件包含姓名、地址等多项个人基本信息,信息准确度和权威性高,在商业银行中被广泛应用于身份认证、信息采集等领域。然而,商业银行的影像数据来源渠道复杂,时间跨度很大,质量层次不齐,目前市面上的身份证识别模型尚不能满足银行质量参差的影像识别需求。因此,一个具备强抗噪声干扰能力的OCR模型有着极高的商业价值。而且在实际应用中OCR识别身份证的实际情况比较复杂,这里列举以下几个难题:
- 图像质量参差:黑白复印件与彩色照片混杂,影像清晰度不尽相同,使得寻找具有普适性的图像处理手段和模型成为困难。

- 文字重叠:商业银行为保护客户信息时常在保存影像件时叠加水印,尤其是深色的文字水印,例如“仅供xxx使用,复印无效”,这些水印与身份证上的文字重叠,给文字识别带来困难。

这些挑战在这个赛题中都有一定的体现。本次赛题的任务是设计针对商业银行身份证识别的OCR系统,识别身份证中姓名、地址、身份证号码和身份证有效日期等信息。通过网络的识别,得到身份证的输出结果示例:例如(0a1c9d6658e3417491f898a3602a0581,李岩宏,阿昌,男,1960,11,25,广西壮族自治区南宁市横县平马镇快龙村,45012719601125584X,南宁市横县公安局,2009.10.17-长期)(结果字符串为csv格式,字符编码为UTF-8格式)。我们小组要做的就是探索对上述挑战中的任意一项设计解决方案,并验证其可行性。
最终的评测方法就是准确率,即:

1.2赛题难点
样本是实际情况下的样本,存在文字重叠、水印覆盖在有效文字上面以及分辨率较低,正反面角度不同等等实际情况中会出现的情况,除此之外,本次赛题其实并不是单纯的OCR,而是基于OCR识别以后的更进一步的图像转文字的问题。所以本次的赛题要求我们在进行数据清洗以及预处理的前提下,更进一步的进行OCR定位以及图片转文字的工作。
2.具体的比赛结果
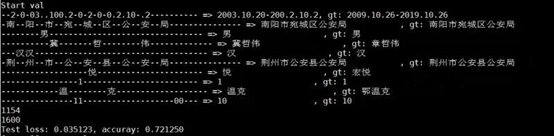
我们的识别准确率为76.125%(这个结果是我们在测试集上的结果,但是并没有提交到网上进行评分,因为这个比赛的结束时间比较早,我们没有赶上deadline),当时的排 名为46/1684=2.7%。
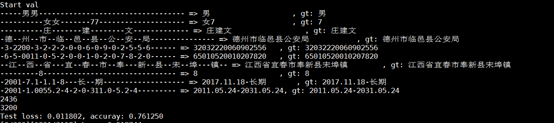
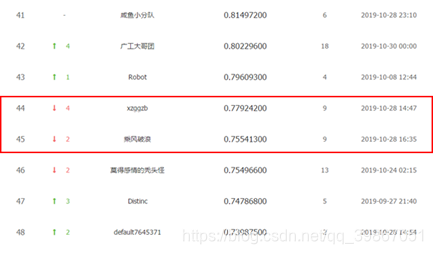
在比赛结束后,我们重新对于模型进行了训练,准确率又有了进一步的提升。准确率提升到了89.25%,排名大约为31/1684=1.84%。
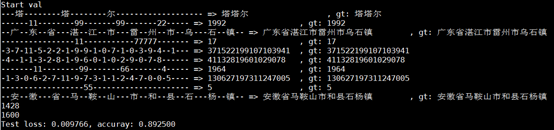
随后我们对于此模型在训练集中划分了4:1的训练集和验证集的数据,并进行了训练,最终的测试效果的准确率为72.125%,名次为51/1684=3.03%。
3. 项目实现
3.1 初步规划
在这里我们所用到的模型如下所示:
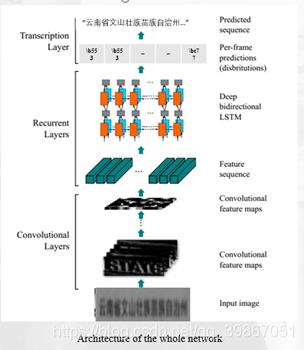
我们的模型是CRNN,它由三部分组成:1. 卷积层,从输入图像中提取特征序列;2. 递归层,预测每个图像的标签分布;3. 转录层,将每帧预测翻译成最终的标签序列。
3.2 中期进度
在前期工作里,我们大部分时间是在进行数据的预处理操作,因为关于整个项目的难点就是对所存在的图片进行处理,才能够更好的输入到模型里进行fine tune
我们先把图像进行了旋转切割,然后识别正反并进行精细度的切割,在前期工作里,我们预期是要加入图像增强和去水印,但是经过使用很多的方法进行测试,我们的图片质量和模型要求并不适用这两个方法,所以直接在识别正反后就进行了精细度的分割,然后得出的相应预处理的结果。所以我们在中期验收时,还没有进行模型的训练。
3.3后期改进
中期答辩之后,结合我们现有的问题以及老师给出的关于生僻字的处理方案的建议,我们小组进行了方案的改进和更改,前期所做的预处理工作还是有很大的用处的,但我们在商量调研之后,对我们的后期任务进行了新的规划安排,大体的计划还是不变的,但是准备换一种训练的模型。
我们小组经过几次实验和调研,和在讨论区看别人的经验和相似问题,最后确定的模型如下,这是RNN和CNN的结合:
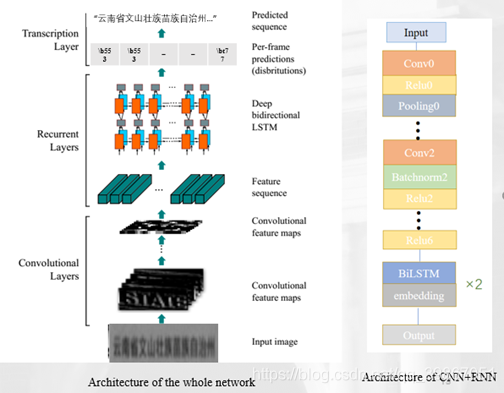
在这里我们做了改进:CNN–特征提取;RNN–对序列进行编码;另外还加入了CTC操作。下面具体讲解一下CTC算法:
CTC是用来解决输入序列和输出序列难以一一对应的问题。因为在OCR中使用RNN时,RNN的每一个输出要对应到字符图像中的每一个位置,要手工做这样的标记工作量太大,而且图像中的字符数量不同,字体样式不同,大小不同,导致输出不一定能和每个字符一一对应。如下所示:
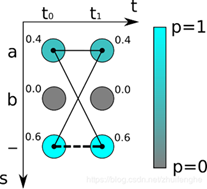
在这里,我们的输入用符号序列X=[x1,x2,…,xT]表示,对应的输出(如对应的标注文本)用符号序列Y=[y1,y2,…,yU],为了方便训练这些数据我们希望能够找到输入X与输出Y之间精确的映射关系。
而在使用有监督学习算法训练模型之前,有几个难点:和都是变长的;和的长度比也是变化的;和相应的元素之间没有严格的对齐(即与不一定对齐);
但是使用CTC算法能克服上述问题,需要明确的是,我们使用的CTC是RNN后接CTC算法,RNN模型输入是个个片段,输出个数与输入的维度一样,有T个片段,就输出T个维度的概率向量,每个向量又由字典个数的概率组成。例如网络输入个数定为T,字典中不同字的个数为N,那么RNN输出的维度为T*N。 根据这个概率输出分布,我们就能得到最可能的输出结果。在接下来的讨论中可以把RNN+CTC看成一个整体,当然也可以将RNN替换成其他的提取特征算法。
其中的损失函数定义为,对于给定的输入X,我们训练模型希望最大化Y的后验概率P(Y|X),P(Y|X)应该是可导的,这样我们就能利用梯度下降训练模型了。
测试阶段:当我们已经训练好一个模型后,输入X,我们希望输出Y的条件概率最高即Y=argmax[p(Y|X)],而且我们希望尽量快速的得到Y值,利用CTC我们能在低投入情况下迅速找到一个近似的输出。
CTC算法对于输入的能给出非常多的Y的条件概率输出(可以想象RNN输出概率分布矩阵,所以通过矩阵中元素的组合可以得到很多Y值作为最终输出),在计算输出过程的一个关键问题就是CTC算法如何将输入和输出进行对齐的。在接下来的部分中,我们先来看一下对齐的解决方法,然后介绍损失函数的计算方法和在测试阶段中找到合理输出的方法。
对齐:CTC算法并不要求输入输出是严格对齐的。但是为了方便训练模型我们需要一个将输入输出对齐的映射关系,知道对齐方式才能更好的理解之后损失函数的计算方法和测试使用的计算方法。
假设对于一段文字序列,我们希望的输出是这个序列,一种将输入输出进行对齐的方式如下图所示,先将每个输入对应一个输出字符,然后将重复的字符删除。
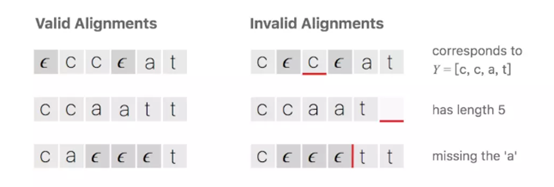
CTC算法的对齐方式有下列属性:输入与输出的对齐方式是单调的,即如果输入下一输入片段时输出会保持不变或者也会移动到下一个时间片段;输入与输出是多对一的关系;输出的长度小于等于输入。
CTC的特征:
条件独立:CTC的一个非常不合理的假设是其假设每个时间片都是相互独立的,这是一个非常不好的假设。在OCR或者语音识别中,各个时间片之间是含有一些语义信息的,所以如果能够在CTC中加入语言模型的话效果应该会有提升。单调对齐:CTC的另外一个约束是输入与输出之间的单调对齐,在OCR和语音识别中,这种约束是成立的。但是在一些场景中例如机器翻译,这个约束便无效了。多对一映射:CTC的又一个约束是输入序列的长度大于标签数据 的长度,但是对于的长度大于的长度的场景,CTC便失效了。
所以在我们的实验中,我们采取了这种方法来进行我们的模型实现并且得到了不错的结果。
除此之外,在中期答辩之后,我们发现准确率不是很高所以就对于图片进行了人工筛选,本来是打算把有生僻字的图片也拿出来单独训练,但是后来考虑效果之后没有采取这种方法;
解码步骤理论上尝试所有可能的文本,那么要选出的最佳路径解码就是在每个时间步中选择最可能的字符,然后删除重复的字符,再从路径中删除所有空格,从而撤消编码;最终得到识别后的文本
在我们从网上重新找到新的模型之后,经过前面同学的坐标定位后,要再进行一次去水印操作,我们采取的是找一个和所给的复印件中带有复印无效字样的最接近的样例:

具体也是用画图软件进行处理的,把边缘进行黑白像素块的覆盖或者填充,进而拿着这个去和我们里面的图片进行对比筛选,最后的结果也是不错,这一步去水印也算是完成的还不错。
4.项目成果
我们输入模型的原始数据如下所示:

在这里进行fine tune遇到的问题如下:
生僻字出现次数很少,难以支持训练;网络RNN层softmax的输出向量形状由Alphabet的个数决定,单纯将生僻字添加进Alphabet表会影响整个网络权重 ;生僻字多出现在居住地、民族、身份证签发公安局等,我们就利用这些信息的专有性进行处理,一共有以下两种思路:
思路一:针对发证公安局和民族,数量较少,词库易于获得,利用爬虫爬取数据库相关信息并制成词库;
思路二:针对公民住址:内容庞杂,词库不易获得,直接利用网络检索。
到最后我们经过尝试之后,和搭档几次无休止的熬夜fine tune之后,模型终于有了一个差不多的结果,结果见第二部分。
除此之外,最终为了展示,我们还做了一个小demo,具体的识别效果和识别率如下:

5.其他的详细工作
5.1去水印工作
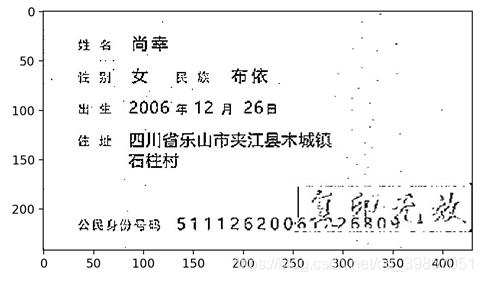
一般图片去水印的方法主要包括两个方法,一个是直接使用蒙版mask匹配的方法去水印,在此基础上还可以加入边缘检测以及进一步的滤波工作,虽然这种去水印的方法实现起来比较简单而且时间复杂度比较小,但是它的约束也很多,例如mask的精度对于图像去水印效果影响很大,而且对于图片水印位置的把控相对来说也是比较重要。但是我们的赛题中的数据,水印的位置不确定,角度也并不是垂直于或水平的,不同图片的亮度也不同,分辨率也有所不同,有的水印下有文字信息,有的没有文字信息,背景也不同。如下面两张图:


分割得到的水印如下图:


从上图中就可以明显看出,分割得到的“复印无效”的水印的背景、亮度分辨率不同,除此之外在真实图片内的位置和角度也不同(当然这个通过精细化的分割来减小误差)。所以仅仅使用一个模板进行水印的去除是不太可能的。基于mask的传统方法的流程如下:

这里可以直接使用Opencv中自带的函数进行去水印的操作,我这里采用的是使用下面这幅mask图像,对于分割好的图片进行逐像素的匹配,选择MSE最高的位置认为是水印出现的位置,并进行进一步去除水印的操作。

接下来使用了Opencv自带的inpaint函数进行不同方法的操作,其中分别选择TELEA(Telea在2004年提出的基于快速行进的修复算法)、NS(噪声抑制核心算法)等数字图像处理的算法进行边缘修复,不过效果一般,尤其是边缘的噪点较多,在图像分辨率本身就不高的情况下会造成网络的误识别。最终的去水印的结果如下:
究其原因,我们发现的是由于是复印件所以本身的水印的宽度不同,或者说分辨率比较低,就算使用最佳的mask匹配也不会得到非常吻合的匹配效果。况且我们不太容易得到纯mask的图片作为蒙版。所以在后期我们有尝试了使用画图等工具将mask进行人工的“修复”,从而使去水印的效果变得好了一些。
除此之外,我还考虑了使用深度学习的方法进行去水印的操作,这里我尝试的使用了Noise2Noise (Remove the watermark & Denoising ICML2018)的方法,因为其既可以去水印,更可以去除噪音并实现超像素。
我复现了整个Noise2Noise,并使用这篇paper中使用的图片集进行了测试:

由上图可见,左图是原图,中间的图是我加了随机的文字噪声(不同颜色,不同大小),可以将其类比于我们数据中的“复印无效”的水印,最右侧的图片是经过算法后的“去水印”的结果,我们可以看出去除文字的效果还可以,不过对于下面这种形式的图片的话,效果很差:

可以比较明显的看到,对于背景为图片的文字的部分的去水印效果非常不好,基本达到了人眼无法识别的程度,此算法仅仅对于背景为一般图像的去水印效果好一些。所以这种基于Noise2Noise的深度模型去水印的方法我们最终也没有采用。一开始我认为深度学习使用到这里完全是杀鸡用牛刀,不过发现真实的效果并不是特别的理想。
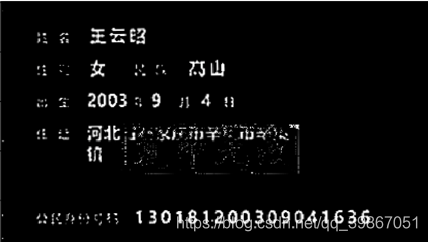
所以在中期结束后,我们尝试了使用传统的方法进行更加精细的匹配和mask图片的更加精细化的处理,我们使用了画图等工具让mask看起来更加“饱满”,然后采取不计时间复杂度的方法进行像素级别的匹配,最终的结果如下。并使用此方法运用在所有的图片中,进行去水印。最终我们使用的水印蒙版和去水印的效果如下两图:

5.2 图片数据处理
我也自己尝试了一下提升图像分辨率的方法,经过分析,我们最终的模型识别率较低的原因,其中有一个是因为本身图像的分辨率就不是很高,后面又进行了切割、旋转、滤波等操作,导致了图像的分辨率进一步降低,从而导致识别效果变差。所以提升图像分辨率是比较重要的,通过查阅资料我们直到,其实有很多的超像素等等的深度学习的方案,不过考虑到问题的复杂程度,我们这里使用基于图像处理的传统方法进行实现。这里我尝试了使用图像膨胀和腐蚀的操作进行图像细节的处理。例如对于下面这幅图:

“洛”字还有最后的“局”字,中间的笔画都缺失了一些,导致最终的识别效果变差,如果我们在输入网络之前再进行一步基于图像形态学的膨胀与压缩就可以进一步增强其识别准确率。经过测试,由于图片的像素比较低,所以这里采用直接膨胀就可以达到我们想要的目标。结果对比如下:

所以我们在将分割好的图片输入网络中的时候,使用膨胀的方法进行了图像分辨率的加成,把肉眼可见的提升结果送入网络中进行训练。
5.3 模型选择与训练
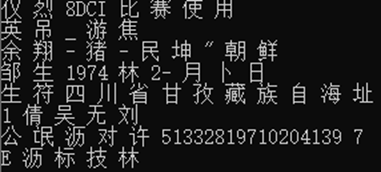
对于OCR,我们一开始尝试使用网上开源的tesseract-ocr库以及金山识别等等软件对于我们的数据集进行了测试,发现结果如下,识别的效果非常不理想:

对于后期的模型选择,我一开始也进行了探索,一开始我认为,我们最终的模型应该分为两个,首先是OCR,即图片的文字区域的定位,这个我认为就是目标识别,我们可以使用YOLO或者Faster RCNN等网络进行文字区域的定位工作,并根据实际的情况进行分割,第二步将分割后的结果进行图像转文字的网络,常见的网络就是CRNN,所以归结起来就是这样的流程,在中期以后,我们着手开始进行模型fine tune的时候,我们分别进行了不同方式的算法复现,最终确定使用的方案。
在使用CTC进行fine tune的时候我们遇到了以下的问题,首先是数据集中的民族有的不在我们公认的56个民族里,所以在这里我们不能使用词库的方法进行匹配。第二点对于地址的信息出现了较多的生僻字,我们一开始尝试使用不同的汉字库,结果发现不论使用什么样的汉字库都不能将数据中出现的文字涵盖到,接着我们又尝试了见到生僻字就将其加入到我们对应的地名库中,发现这样工作量太大,最后我们在老师的建议下,使用了地名库,因为中国所有的省、市县乃至乡的名称我们都可以在网上找到,所以我们使用了爬虫将国家地名库中的内容进行了爬取,并将识别的内容在地名库中进行搜索,从而得到最终正确的预测结果。例如本来识别为“石家庄市辛佳市公安局”的信息,通过我们的地名库可以查到石家庄市下属只有“辛集市”没有“辛佳市”,所以我们将最终的信息认为是“石家庄市辛集市公安局”。
另外,我们也通过身份证号码的结构进行结果的改进,例如身份证号的信息:公民身份号码是特征组合码,由十七位数字本体码和一位校验码组成。排列顺序从左至右依次为:六位数字地址码,八位数字出生日期码,三位数字顺序码和一位数字校验码。其中的地址码:表示编码对象常住户口所在县(县级市、旗、区)的行政区划代码,出生日期码:表示编码对象出生的年、月、日。我们可以通过这些信息来判断数字判断错误或者是数字对应的出生年月或者地址信息判断有误等等。
5.4 后期的demo的制作
在最后的阶段,由于我们赛题的性质是偏实用性,所以由我做出了一个展示的Demo,模仿实际的使用场景实现了实时的OCR识别功能。这里我使用了python的web库在本地开设端口,并进行与模型接口的对接,并使用html编写了简单的OCR识别界面,由于我们在赛题后期,对于数字的处理效果很好,但是对于文字的识别还有待提高,所以我在这里也分别提供了不同的识别对象,我们也可以通过这个Demo实时的看出我们的模型文字定位效果以及模型的文字转换的效果。下面是我们对于身份证的数字识别的效果:对于大部分的数字我们可以百分百的识别成功(识别时间0.379秒)。
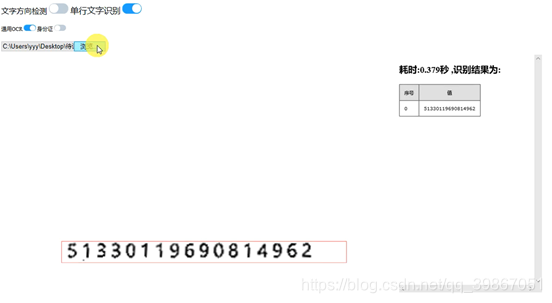
对于单行的切割出来的文字,我们也可以做到比较好的识别(识别时间0.02秒):
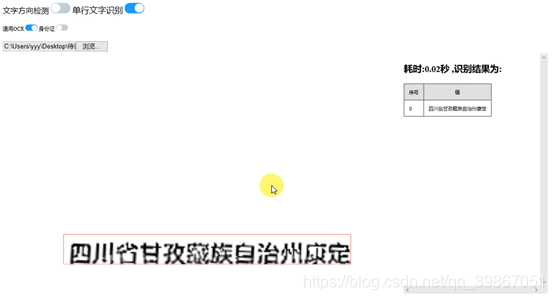
对于大部分的完整身份证,我们也可以做到比较好的识别(识别时间1秒左右):
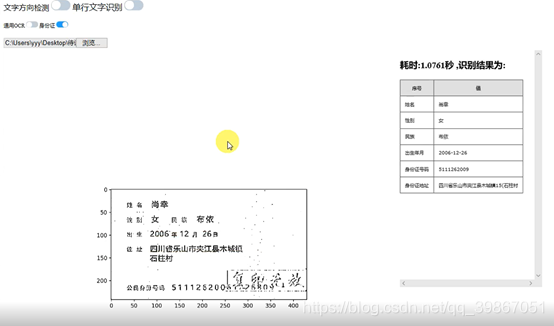

最终的Demo的录屏视频,我们也放到了提交的压缩包中。
6 项目总结与心得体会
通过近两个月的工作,我们能够较为准确的识别出来身份证复印件上的各种信息,但是我们在生僻字以及被水印覆盖的地方的识别效果仍然不是很好,不过我们的最终的模型的识别效果以及基本超过了开源的OCR文字识别软件。从项目中也收获了很多知识。
在比赛的方面,我也了解到了处理这种偏实际应用的比赛,数据的预处理是特别的重要。尤其是尽可能地使用非深度学习地方法,这也就要求我们从更加深层次地角度去看待问题,我们自己去挖掘数据中的有用信息。对于模型的选择,我也是通过这次比赛了解到了图片转文字所使用的CRNN以及CTPN等模型和CTC等模型结构,在熟悉代码的同时,也掌握了模型的结构和思想,这对于我们日后的项目和科研都有很大的帮助。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









