







多线程爬虫项目示意图
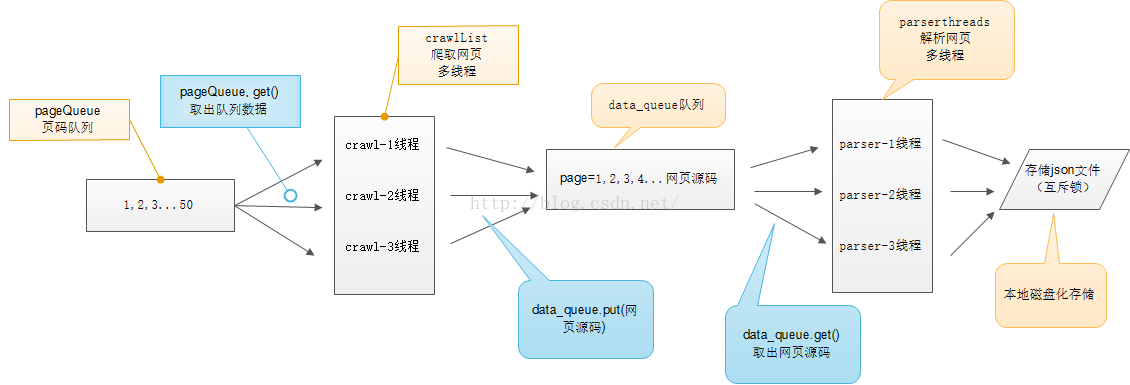
首先,我们要明确知道多线程以下几个重点:
1.要等目标线程都结束才能使主线程结束:主线程结束所有线程都会随之停止则线程可能还未完全跑完
2.多个线程间要对同一数据进行操作时要添加互斥锁
3.多个线程之间通信要用队列(先进先出)
此次多线程爬虫我们要写两个多线程:
1.爬取网页的多线程 2.解析网页的多线程
import requests
import threading
from lxml import etree
from queue import Queue
import json
import time
class Crawlthread(threading.Thread):
def __init__(self, name, pagequeue, dataqueue):
# 调用父类初始化
super(Crawlthread, self).__init__()
self.name = name
self.pagequeue = pagequeue
self.dataqueue = dataqueue
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
def run(self):
print("启动" + self.name)
# 循环的目的是等待此线程有从队列中获取数据
while not a:
try:
page = self.pagequeue.get(False)
# 默认是True 当队列为空进入阻塞直至超时
# 设置False 当队列为空会捕获异常
url_temp = "https://www.qiushibaike.com/text/page/{}/"
url = url_temp.format(page)
response = requests.get(url, headers=self.headers)
time.sleep(1)
self.dataqueue.put(response.content.decode("utf8", "ignore"))
except:
pass
class Parsethread(threading.Thread):
def __init__(self, name, dataqueue, file, lock):
super(Parsethread, self).__init__()
self.name = name
self.dataqueue = dataqueue
self.file = file
self.lock = lock
def run(self):
print("启动" + self.name)
while not b:
try:
html = self.dataqueue.get(False)
self.parse(html)
except:
pass
print("退出" + self.name)
def parse(self, html):
html = etree.HTML(html)
node_list = html.xpath("//div[@id='content-left']/div[@class='article block untagged mb15 typs_hot']")
connect_list = []
for div in node_list:
item = {}
item["id"] = div.xpath(".//h2/text()")
item["id"] = [i.replace("\n", "") for i in item["id"]][0]
item["content"] = div.xpath(".//div[@class='content']/span/text()")
item["content"] = [i.replace("\n", "") for i in item["content"]][0]
item["author_image"] = div.xpath(".//div/a/img/@src")
item["author_image"] = "https:" + item["author_image"][0] if len(item["author_image"]) > 0 else None
item["age"] = div.xpath(".//div[contains(@class, 'articleGender')]/text()")
item["age"] = item["age"][0] if len(item["age"]) > 0 else "暂无此信息"
item["author_gender"] = div.xpath(".//div[contains(@class, 'articleGender')]/@class")
item["author_gender"] = item["author_gender"][0].split(" ")[-1].replace("Icon", "")[0] if len(
item["author_gender"]) > 0 else "暂无此信息"
item["stats_vote"] = div.xpath(".//div/span/i/text()")
item["stats_vote"] = item["stats_vote"][0] if len(item["stats_vote"]) > 0 else "没有点赞"
item["user_commons"] = div.xpath(".//span[@class='stats-comments']/a/i/text()")
item["user_commons"] = item["user_commons"][0] if len(item["stats_vote"]) > 0 else "没有评论"
connect_list.append(item)
# 同步锁操作:包括打开和释放锁 避免因为多个线程同时操作进行时出错
with self.lock:
for c in connect_list:
self.file.write(json.dumps(c, ensure_ascii=False) + "\n")
print("保存成功")
a = False
b = False
def main():
pagequeue = Queue(10)
dataqueue = Queue()
for i in range(1, 11):
pagequeue.put(i)
file = open("duanzi.json", "a", encoding="utf8")
lock = threading.Lock()
crawllist = ["采1号", "采2号", "采3号", "采4号"]
treadcawl = []
# 启动获取网页四个线程
for crawl in crawllist:
thread = Crawlthread(crawl, pagequeue, dataqueue)
thread.start()
treadcawl.append(thread) # 加入线程队列
parselist = ["解1号", "解2号", "解3号", "解4号"]
# 启动解析网页四个线程
threadparse = []
for parse in parselist:
thread = Parsethread(parse, dataqueue, file, lock)
thread.start()
threadparse.append(thread)
# 判断队列是否已经都添加 不为空即还有没有添加一直等待都已经添加到线程中
while not pagequeue.empty():
pass
global a
a = True
print("page_queue已经为空了")
# 确保此线程都在主线程结束前已经执行完毕 ->主线程阻塞
for thread in treadcawl:
thread.join()
while not dataqueue.empty():
pass
global b
b = True
for thread in threadparse:
thread.join()
with lock:
file.close()
if __name__ == '__main__':
main()
运行结果如下:

> 不急不躁,稳扎稳打。
> 欢迎相互交流,促进进步。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









