







这篇博客是《web安全机器学习入门》DGA域名检测朴素贝叶斯的代码进行复现与解释。
实验步骤如下
1.数据搜集和数据清洗
2.特征化
3.训练样本
4.效果验证
数据搜集和数据清洗
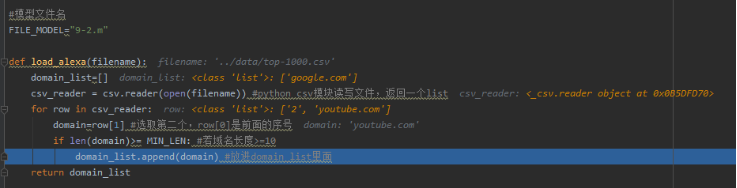
返回如下结果
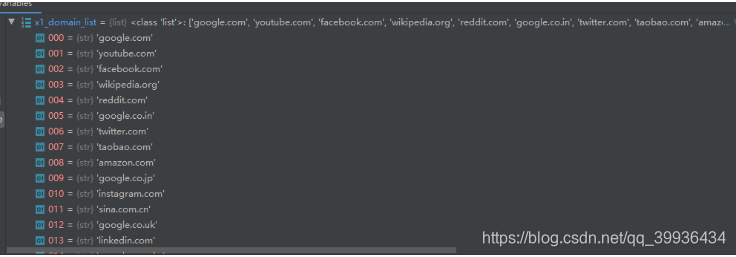
load_dga
特征化、训练与验证
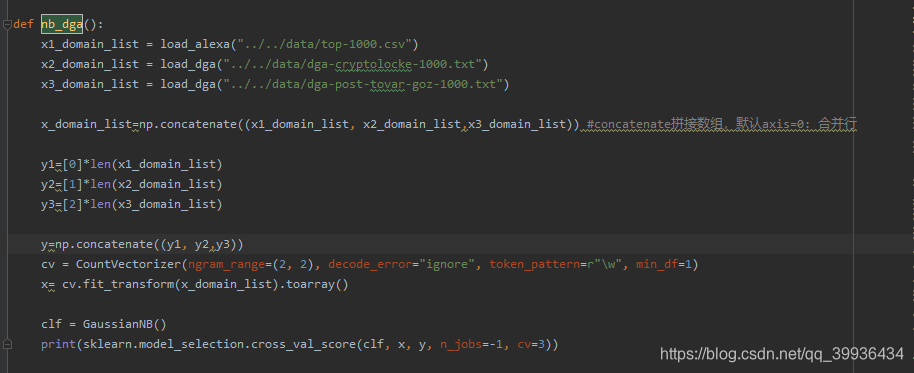
使用三折交叉验证法,输出结果
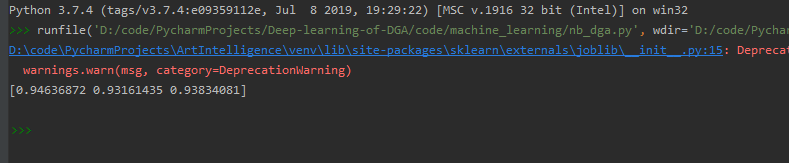
命中率还不错率还不错
想深入了解三折交叉验证法得话,看我另一篇Blog
其中,对某些代码与函数解释
初始化变量y1,y2,y3


concatenate 转换成数组
核心处理特征函数
countVectorizer 是用来处理N-Gram特征的函数

countVectorizer参数介绍:每2个切割,单词读取错误忽略,正则匹配所有字符,频数起码出现1次
然后,fit_transform训练数据
我们用简单的数据测试下,看返回结果

用countVectorizer切割
分割出来的词典
print(cv.get_feature_names())

无序词典,并且带有下标
print(cv.vocabulary_)

输出训练后的稀疏矩阵,print(x)
参数为 :data列表下标,无序词典下标,该词在data出现的频数
eg:“为了”在无序词典的下标为0,而且属于data列表的0下标,在data列表里出现了两次,所以为(0,0)2,所以定位了一个词的位置和频数

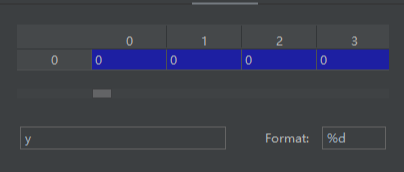
转为array,print(x.toarray())
x的每个定位都可以在坐标中找到,例如:“为了”,
他的是(0,0) 2,则对应矩阵中第一行第一列的值2,
其他依此类推

本博客对应代码已上传至GitHub:nb_dga.py














 6058
6058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









