







这篇博客是是基于DGA系列用到的朴素贝叶斯算法的再往深一层深入,试图在简单的数学算法和不适用sklean库的方面上,理解该算法。本代码是《机器学习实战》的朴素贝叶斯源码。
理论
1.数学基础
条件概率(Condittional probability),就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示
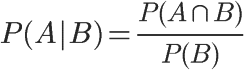
最终可变形为:
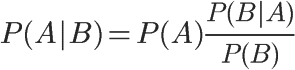
P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
朴素贝叶斯
知道基本的数学公式和相关概念之后,再看朴素贝叶斯。朴素贝叶斯就是假设每个条件概率都是独立,所以上面的公式可化为,假设x有n个特征
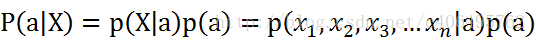
由于每个特征都是独立的,我们可以进一步拆分公式
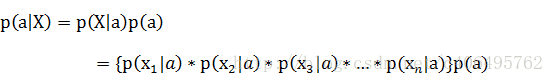
贝叶斯决策理论
假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示:
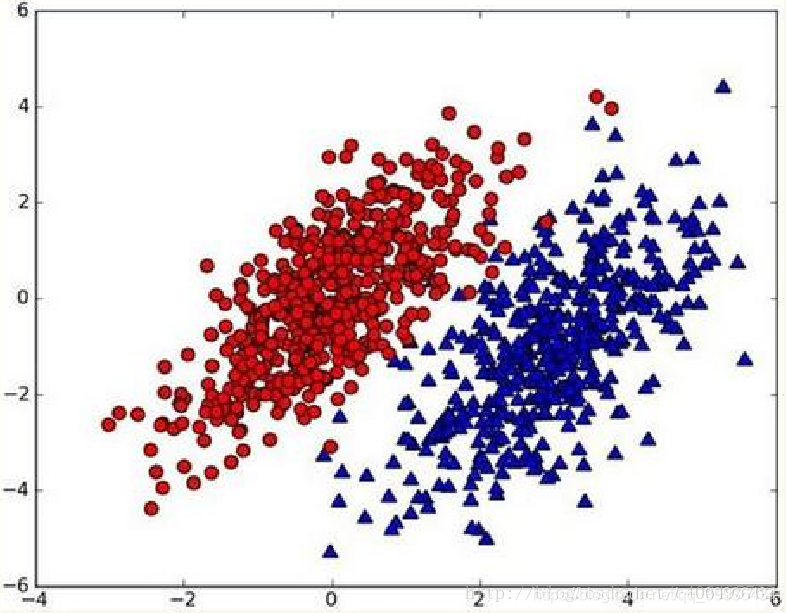
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
如果p1(x,y) > p2(x,y),那么类别为1
如果p1(x,y) < p2(x,y),那么类别为2
2.实战部分
下面我将用一个实例(鉴别评论是否为侮辱性)来诠释朴素贝叶斯分类算法的应用。
我们的训练基础数据有6条
| 序号 | 内容 |
|---|---|
| 非侮辱性 | my dog has flea problems help please |
| 侮辱性 | maybe not ake him to dog park stupid |
| 非侮辱性 | my dalmation is so cute ,I love him |
| 侮辱性 | stop posting , stupid worthless garbage |
| 非侮辱性 | mr licks ate my steak,how to stop him |
| 侮辱性 | quit buying worthless dog food,stupid |
这里有非侮辱性的语句,也有带stupid(愚蠢的)的侮辱性语句
我们将用他们来训练我们的朴素贝叶斯算法模型,
然后我们再输入 my等词汇来看朴素贝叶斯分类是否能做出正确分类
(一)数学部分
在动手代码之前,我们需要明白如果是用数学法是怎么计算的。代码就是基于数学思想的实现而已。
我们要判断一个词是否为侮辱性词语,
那么最终得到得结果是P(侮辱性|stupid,garbage…)和P(非侮辱性|stupid,garbage…),然后比较这两个概率的大小就可以得出结果
分类器就可以做出决策。
那推导公式如下:
P(侮辱类|stupid,garbage)=P(stupid|侮辱类)xP(garbage|侮辱类)xP(......|侮辱类)xP(侮辱类)/P(stupid,garbage) xP()
另一个是
P(非侮辱类|stupid,garbage)=P(stupid|非侮辱类)xP(garbage|非侮辱类)xP(......|侮辱类)xP(非侮辱类)/P(stupid,garbage)
(二)代码部分
代码部分步骤大致分为
1.加载数据
2.文本数据向量化
3.训练数据
4.测试数据
1.加载数据
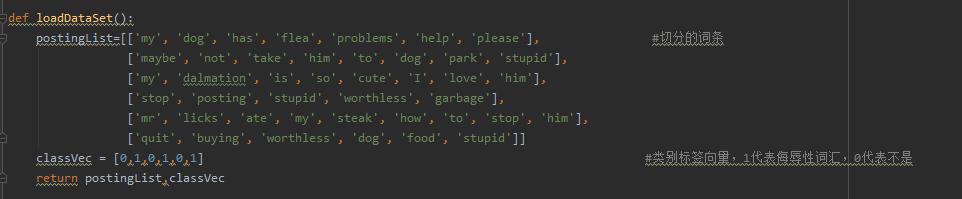
将上面的词条切割(去掉标点符号),并且创建一个classVec标签数组(侮辱性为1,非侮辱性为0)
2.文本数据向量化
分两步,第一步将重复的单词去重,建立一个不重复的词汇表

第二步,将文本转化为0101类型词集模型
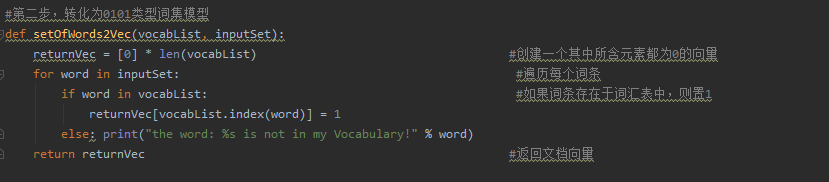
将每条评论里面的单词,逐一与词汇表比较,如果出现就打上1,否则就为0,6条评论数组的长度就为6
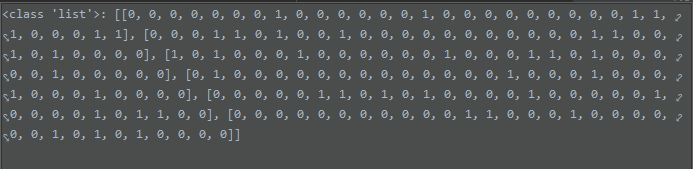
3.训练朴素贝叶斯模型数据
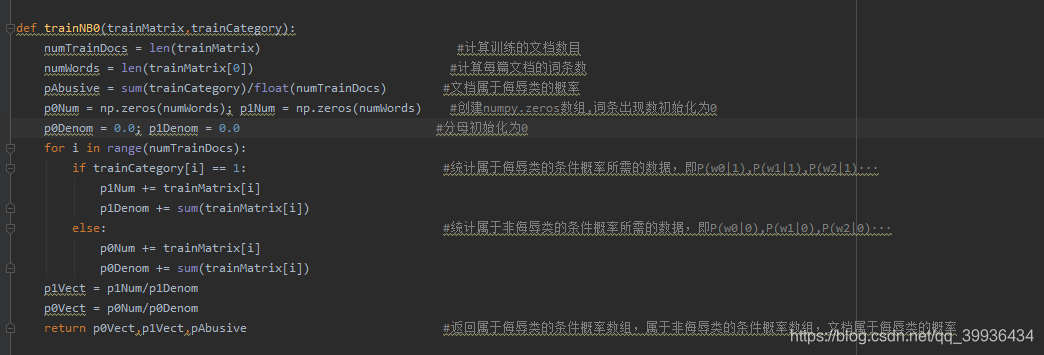
这个方法是核心算法,上面说的数学公式也是在这里实现了:
pAbusive这个变量的含义就是P(侮辱类),计算出来一个另外一个P(非侮辱类)用1-P(侮辱类)就出来了
使用np.zeros,是方便可以直接对数组进行运算,例如普通数组[1,2,3,4]若要数组中每个元素都除于2,则要遍历数组才行这样消耗很多时间,而np.zeros数组可以直接使用[1/2,2/2,3/2,4/2],返回计算结果组成的数组
for进入循环之后会判断每条评论是否为侮辱性,然后将每个类别的所以评论的中出现的单词频数相加,最后返回一个数组,这个数组就是每个单词在侮辱类/非侮辱类出现的频数。
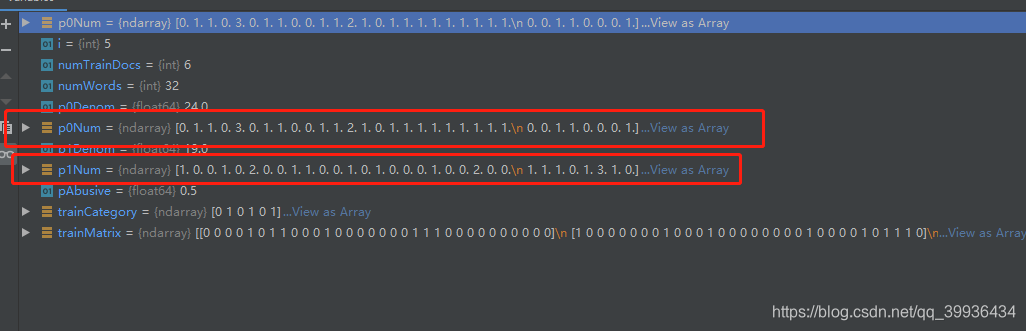
有的词语在p1Num出现1次或2次,而有的词在p0Num出现1次~3次不等
而p0Denom和p1Denom记录着侮辱类/非侮辱类的总词频

最后这个计算出类似于这样的[P(stupid|侮辱类),P(garbage|侮辱类),P(not|侮辱类)…]数组
这个方法返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
4.模型测试

我们分别使用
testEntry = [‘love’, ‘my’, ‘dalmation’]
testEntry = [‘stupid’, ‘garbage’]
两个样本去测试,模型是如何使用已训练好的数据来判断他们的呢
重点在这里classifyNB:
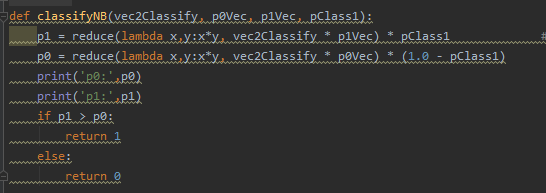
对应元素相乘,因为测试数据集已经转为01形式的词条向量了,若在之前的评论数出现的单词就1x该词的概率,没出现的就是概率0。从而最终结果变为p(w|侮辱类)相乘的形式。达到上面数学公式的结果
我们来看运行结果

p1,p0都为了。很明显这个是错误的,说明上面的算法存在问题,我们还需要对这其进行小小的改进
改进
(1) 拉普拉斯平滑:防止由于某一个条件概率为 0,导致分类概率为 0 的不合理情形
(2) 条件概率对数化:防止小数相乘出现的下溢出问题
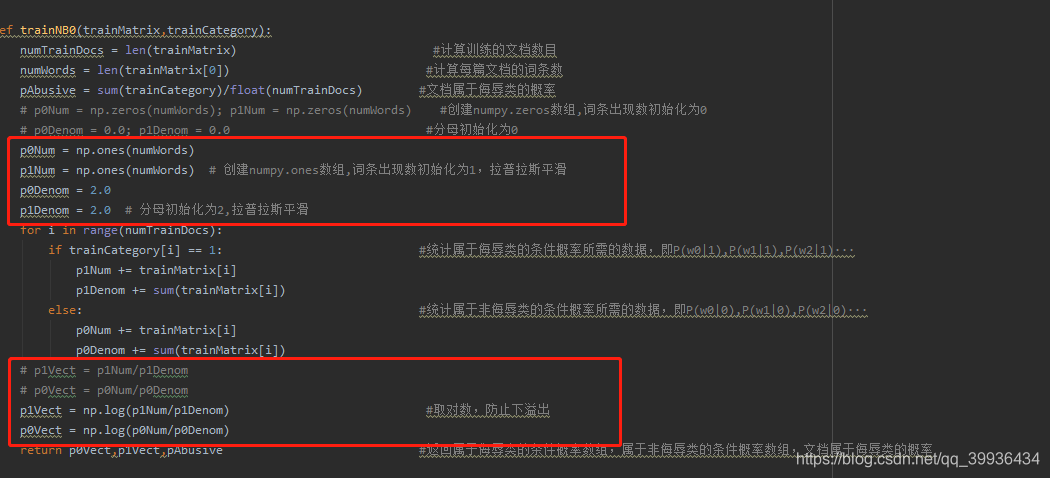
随着classifyNB方法也要改一下
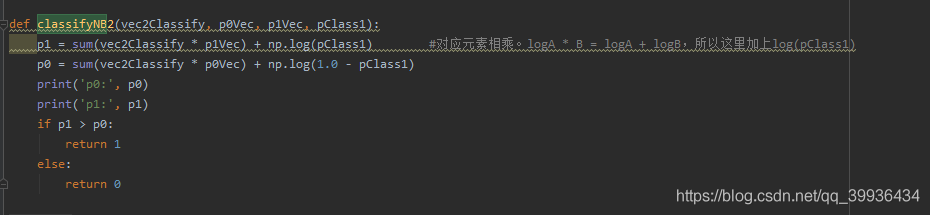
最终结果
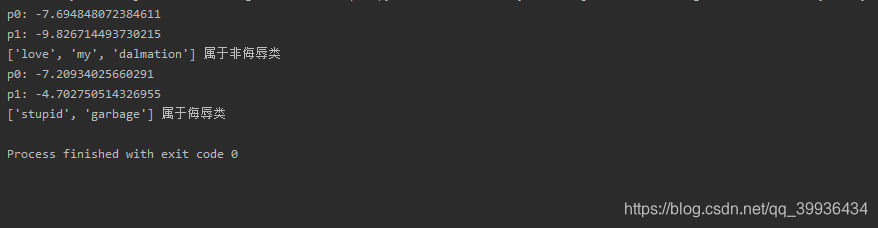
分类器能正常分类
源码发布在github上:naiveBayses.py
参考连接:https://blog.csdn.net/c406495762/article/details/77341116#2__39














 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









