









 本文探讨了如何在金融时间序列数据上运用课程学习和模仿学习进行模型-free控制,结果显示课程学习对复杂任务有显著提升,而模仿学习需谨慎处理。研究通过数据增强、逆向平滑等手段优化控制性能,并通过实证研究和消融分析证实了这些方法的有效性。
本文探讨了如何在金融时间序列数据上运用课程学习和模仿学习进行模型-free控制,结果显示课程学习对复杂任务有显著提升,而模仿学习需谨慎处理。研究通过数据增强、逆向平滑等手段优化控制性能,并通过实证研究和消融分析证实了这些方法的有效性。
WWW'24 | 课程学习CL+模仿学习IL用于ETF及商品期货交易
原创 QuantML QuantML 2024-05-04 13:47
论文地址:[2311.13326] Curriculum Learning and Imitation Learning for Model-free Control on Financial Time-series (arxiv.org)
本文探讨了在金融时间序列数据上应用课程学习(Curriculum Learning, CL)和模仿学习(Imitation Learning, IL)的方法,特别是在模型无关控制任务上。
摘要(Abstract)
-
背景:尽管课程学习和模仿学习在机器人领域得到了广泛应用,但在处理高度随机的金融时间序列数据控制任务上的研究却很少。
-
方法:文章通过数据增强实现了课程学习的基础思想,并通过从预言者(oracle)中提取策略来实现模仿学习。
-
发现:研究发现课程学习是提高复杂时间序列控制任务性能的一个新方向。尽管在基线调整中给予了基线优势,但随机种子外样本实证研究和消融研究对课程学习非常有利。另一方面,模仿学习应谨慎使用。
引言(Introduction)
-
挑战:优化投资组合和交易市场一直是一个挑战,尤其是在批评人类管理者随意管理资金的文献背景下。
-
数据限制:与物理系统不同,金融控制领域的训练数据是固定的,并且只能在时间维度上进行抽样。
相关工作(Related Works)
-
课程学习:在深度学习和强化学习系统中,课程学习通过先让网络接触简单数据,然后逐步接触更复杂的数据来训练。
-
模仿学习:在机器人控制学习领域,模仿学习通过模仿专家或预言者的行为来训练学生(待训练的代理)。
金融控制的强化学习(RL for Financial Control)
-
进展:自2020年以来,强化学习在金融控制方面取得了显著进展,利用大型数据集和神经网络改进金融决策,而不依赖于模型假设。
信号与噪声的初步讨论(Preliminary: Signal and Noise)
-
噪声与信号:所有与公共金融市场交互的顺序控制任务都受到高随机性和随之而来的高噪声-信号比的影响。
方法(Method)
-
投资组合控制作为马尔可夫决策过程:将一系列金融控制任务,如交易、投资组合优化和最优执行等,视为通过离散动作集与市场互动的马尔可夫决策过程(MDP)。
-
模仿学习:模仿学习是一种学习策略,其中一个智能体(称为学生)通过观察另一个智能体(称为老师或专家)的行为来学习。在单学习者设置中,模仿学习通过模仿预言者的行为来训练学生代理,使其学习符合环境约束的最优策略,模仿学习的具体训练过程为:
-
-
专家模型训练:
-
首先,训练一个专家模型(Oracle),它可以访问未来的数据,从而能够确定最优的决策路径。
-
-
策略提取:
-
从专家模型中提取出最优策略,这些策略是确定性的,并且遵循环境的约束。
-
-
学生模型训练:
-
学生模型(Agent)通过模仿学习来复制专家的行为。学生模型被训练以最小化其行为与专家策略之间的差异。
-
-
直接策略蒸馏(Direct Policy Distillation, DPD):
-
学生模型通过直接模仿专家的策略来进行训练,而不是通过与环境的交互来学习。
-
-
训练过程:
-
使用强化学习算法(例如PPO, TRPO, A2C)来训练学生模型,同时使用专家策略作为训练信号。
-
-
标签空间的确定性:
-
模仿学习过程中,标签空间(即行动空间)是确定性的,因为专家的决策是基于完整信息集的。

-
-
-
-
课程学习:课程学习是一种逐步训练学习系统的方法,它将学习过程分解为一系列逐渐增加难度的任务。通过在训练期间平滑噪声时间序列数据来实现课程学习。文章假设轻微的数据平滑将减少噪声的影响,而对信号的影响较小,课程学习的训练果果成为:
-
-
数据增强:
-
通过对原始金融时间序列数据应用数据增强技术,如指数移动平均(EMA)或舍入(rounding),来平滑数据。
-
-
分阶段训练:
-
训练过程被分为多个阶段,每个阶段都使用不同程度平滑的数据。开始时使用高度平滑的数据,然后逐步减少平滑程度。
-
-
逆向平滑(Inverse-Smoothing, IS):
-
从高度平滑的数据开始训练,逐步过渡到较少平滑或未平滑的数据。
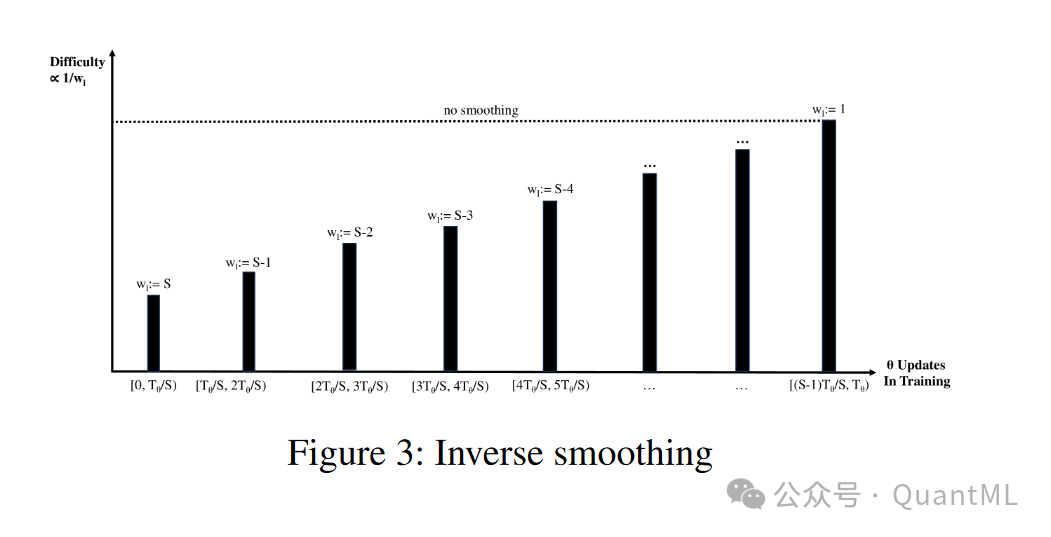
-
-
调整的逆向平滑(Tuned Inverse-Smoothing, TIS):
-
在验证集上调整平滑程度的超参数,以找到最佳的平滑级别。
-
-
训练算法:
-
使用强化学习算法来训练模型,同时应用课程学习策略。
-
-
状态表示:
-
利用历史数据点生成状态表示,可能包括使用滑动窗口或递归网络(如LSTM)来捕捉时间依赖性。
-
-
超参数调整:
-
对于课程学习中的每个阶段,调整超参数以优化模型性能。
-
-
训练和验证:
-
在训练集上训练模型,并在验证集上评估其性能,以确定是否需要调整平滑程度或模型参数。
-
-
-
数据(Data)
-
数据集:选择两个代表性的金融时间序列数据集来测试提出的方法,基于交易量选择金融变量:
-
宏观ETFs环境(Macro ETFs):
-
这个数据集包含了跨资产类别的投资组合,涉及不同的金融工具,如商品、货币、固定收益和利率等。
-
数据集包含了一系列的ETFs(交易所交易基金)和其他金融变量,用以模拟跨资产类别的问题。
-
-
商品期货环境(Commodity Futures):
-
这个数据集专注于单一资产类别,即商品期货。
-
数据集包含了多种商品期货合约,如小麦、玉米、铜、银、黄金、铂金、原油和取暖油等。
-
-
优化约束(Optimization Constraints)
-
约束:为了提高研究的鲁棒性,对每个数据集应用了硬约束,模仿现实世界的投资组合优化问题。
实证研究(Empirical Study)
-
实验:使用多层感知器(MLP)基础的实验,比较了提出的方法与启发式和强化学习基线的性能。
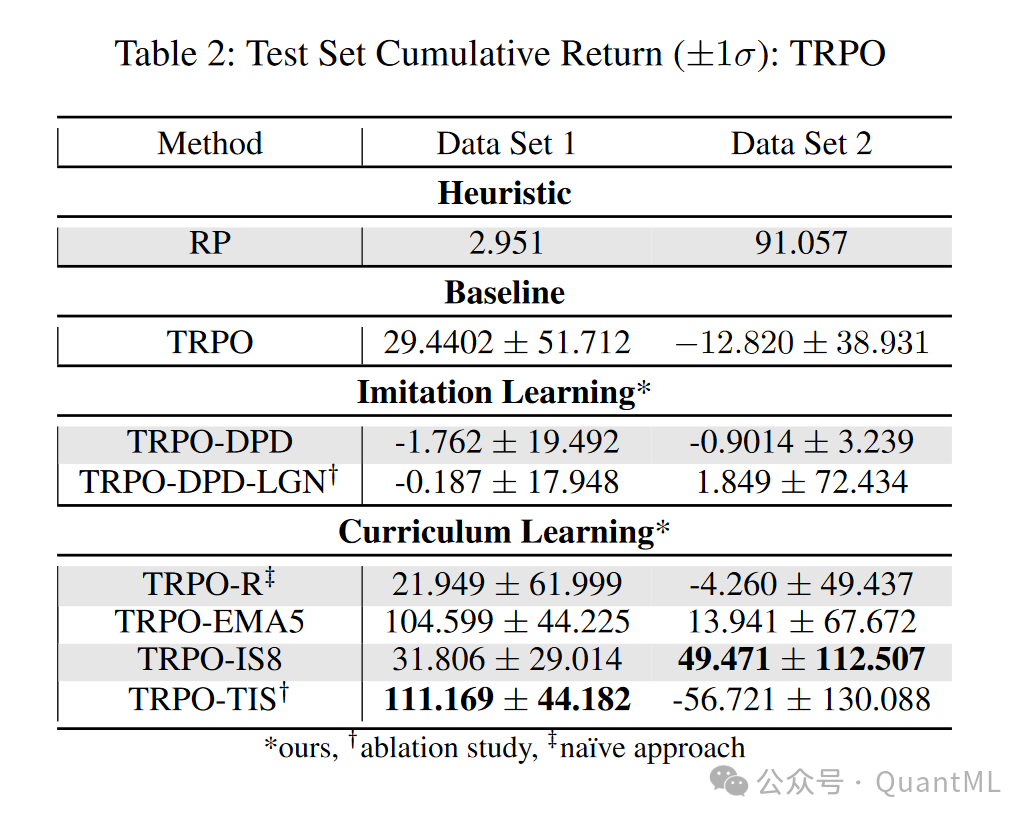
消融研究(Ablation Study)
-
分析:对模仿学习方法和课程学习方法进行了额外的消融研究,以更好地理解结果。
结果分析与讨论(Analysis and Discussion Results)
-
结果:课程学习方法在所有测试环境中均显示出优越的性能,而模仿学习方法的性能显著下降。
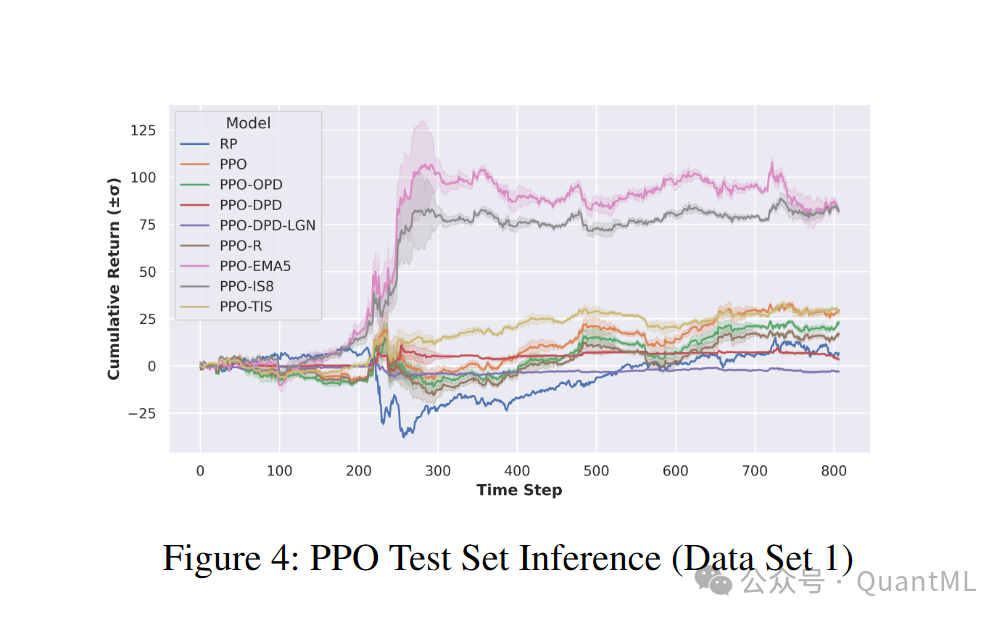
-
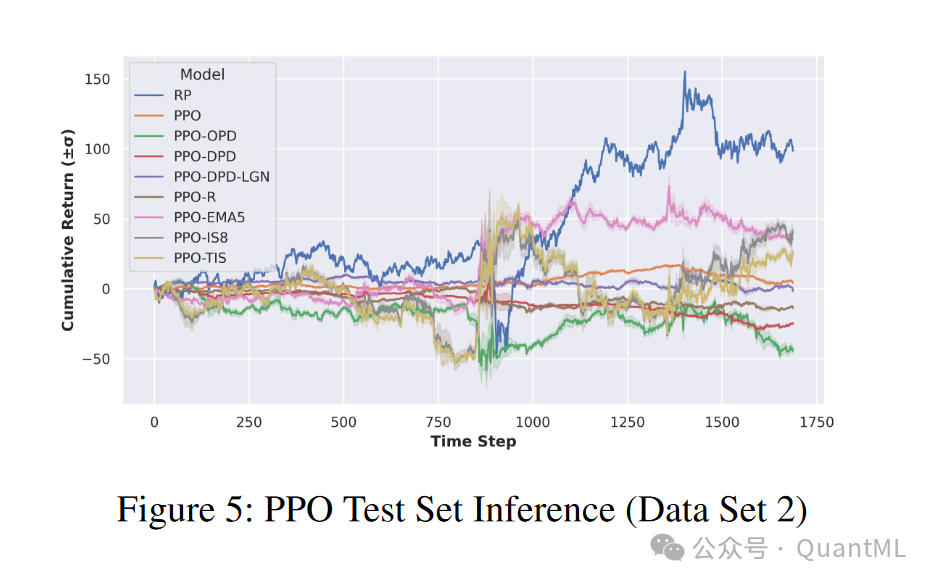
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









