






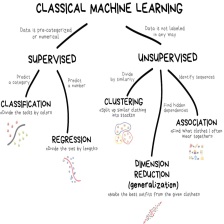
线性分类
分类方式
硬分类
使用的是非概率模型,分类结果是决策函数的决策结果。
代表:线性判别分析、感知机
软分类
分类结果是属于不同类别的概率。
生成式
通过贝叶斯定理,使用MAP比较 P ( Y = 0 ∣ X ) P(Y=0|X) P(Y=0∣X)和 P ( Y = 1 ∣ X ) P(Y=1|X) P(Y=1∣X)的值。
代表:Gaussian Discriminant Analysis
判别式
直接对P(Y|X)进行学习。
代表:逻辑回归
多分类学习
一对一OvO
将K个类别两两配对,产生K(K-1)/2个二分类任务。存储开销和测试时间开销通常比OvR更大。
一对其余OvR
将一个类的样例作为正例,所有其他类的样例作为反例来训练N个分类器。在类别很多的时候,OvR的训练时间开销较大(每一次训练都是全量样本)。
多对多MvM
每次将若干个类作为正类,若干个其他类作为反类。
技术:纠错输出码ECOC。
过程:编码,对K个类别做p次划分,一共产生p个训练集,和p个分类器。解码,p个分类器分别对测试样本进行预测,预测标记组成一个编码。将编码与每个类别自己的编码比较,返回其中距离最小的类别。类别划分通过编码矩阵(二元码或者三元码)。
在测试阶段,ECOC编码对分类器的错误有一定的容忍和修正能力。一般来说,对同一个学习任务,编码越长,纠错能力越强(所训练的分类器越多)。
类别不平衡问题
基本策略就是再缩放。利用 y ′ 1 − y ′ = y 1 − y ∗ m − m + \frac{y'}{1-y'} = \frac{y}{1-y}*\frac{m^-}{m^+} 1−y′y′=1−yy∗m+m−。
欠采样
代表有EasyEnsemble算法。将反例划分成若干个集合供不同学习器使用,在全局来看不会丢失重要信息。
过采样
代表有Smote算法。
阈值移动
将基本策略内嵌。
Reference
- 《美团机器学习实践》by美团算法团队,第三章
- 《机器学习》by周志华,第三、四章
- 白板推导系列,shuhuai007














 2429
2429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









