







Python爬虫教程-17-ajax爬取实例(豆瓣电影)
ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互
对于ajax:
- 1.一定会有 url,请求方法(get, post),可能有数据
- 2.一般使用 json 格式
爬取豆瓣电影
- 网站分析:
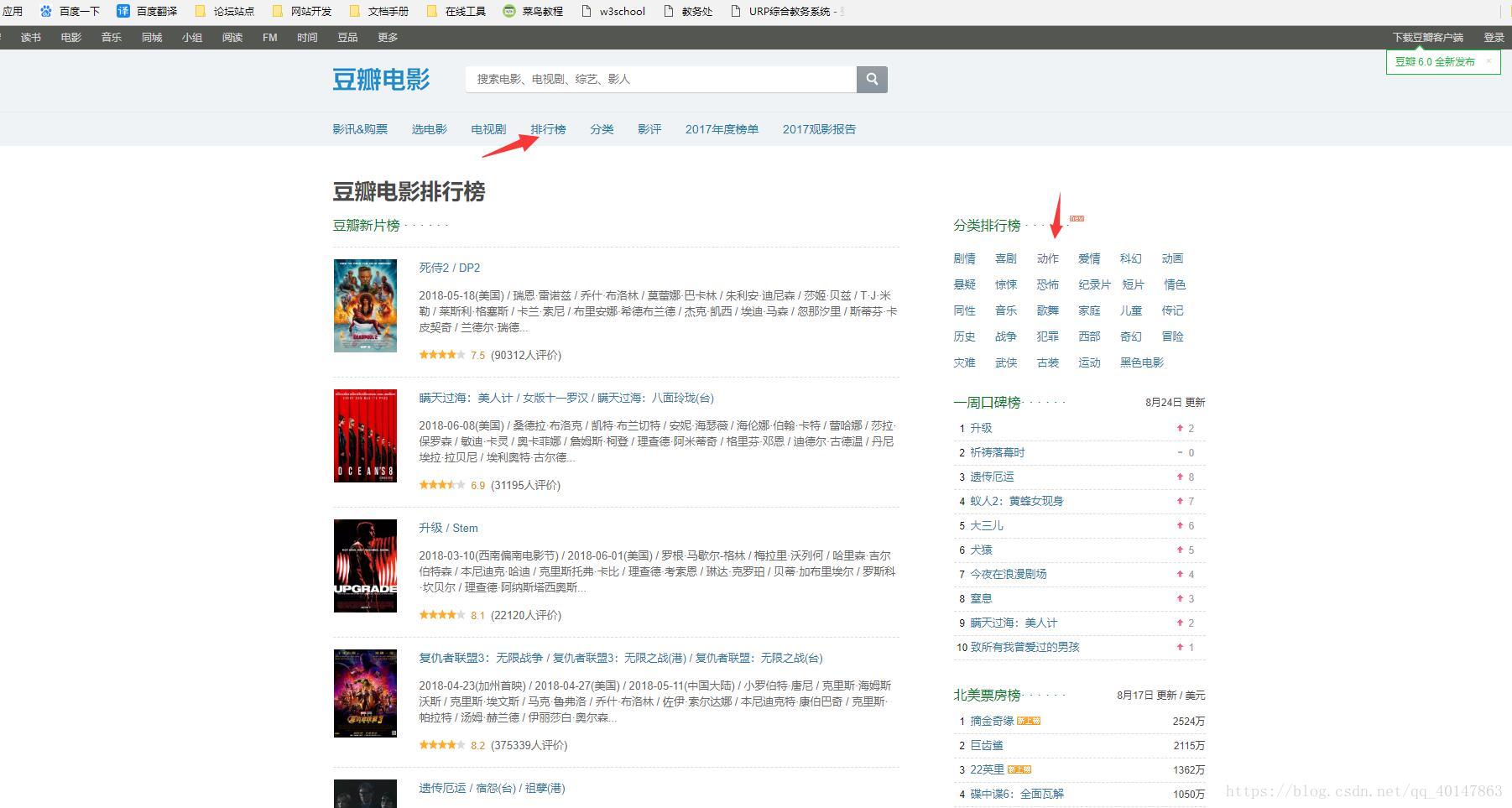
- 打开豆瓣电影网站:https://movie.douban.com/,选择【排行榜】,点击【动作】分类
- 一直往下滑,可以看到这样的效果:快到低的时候又有了新的内容,也就是往下没完
- 基本可以判定使用了 ajax 请求,进行异步的加载
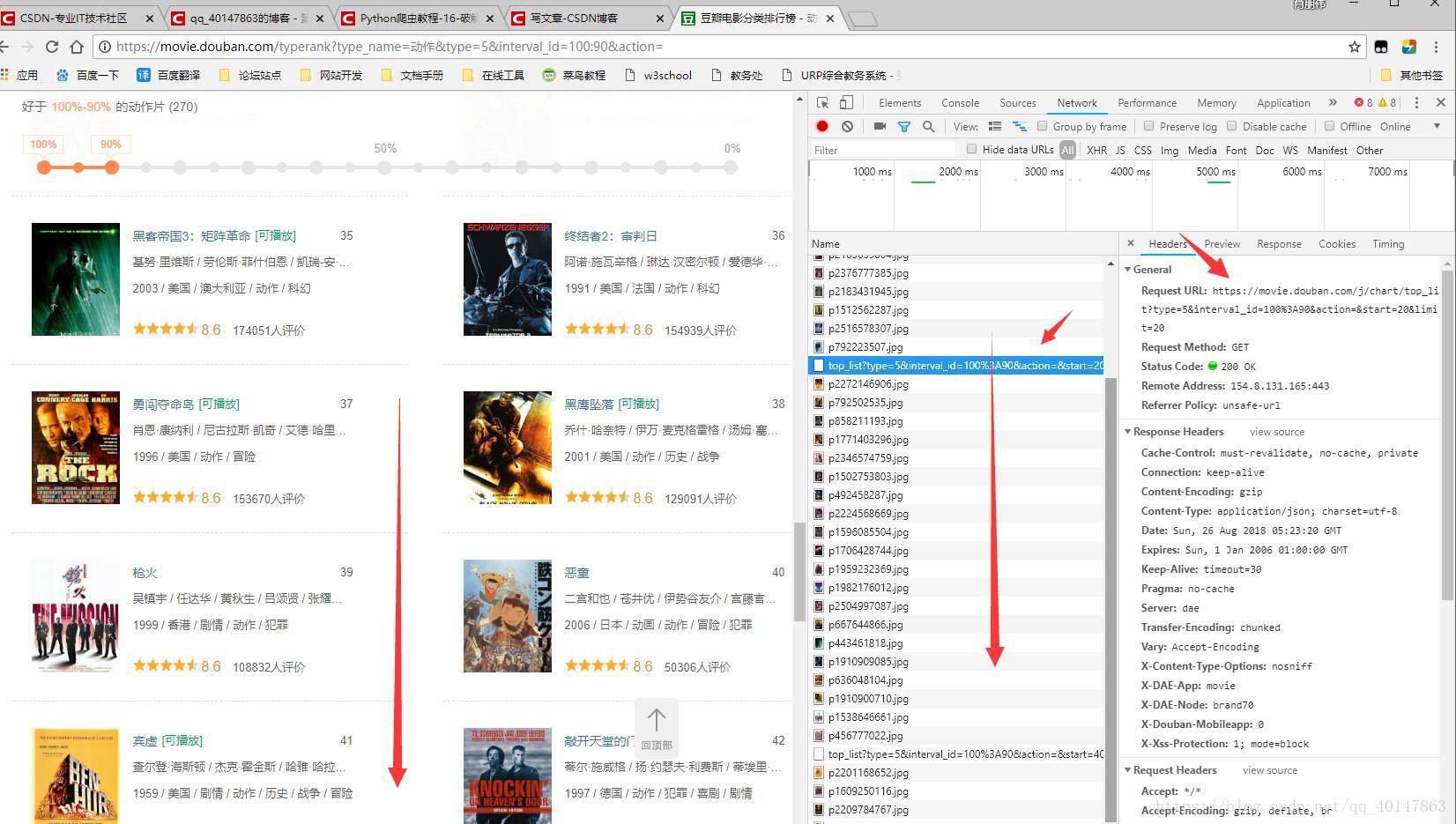
- 然后进去检查请求的信息:
- 1.右键【检查】>【Network】
- 2.向下滚动页面
- 3.可以看到请求在不断不更新,点击一个请求,就可以看到请求的信息
- 代码文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py19db.py
# 爬取豆瓣电影数据
# 了解ajax的爬取方式
# https://movie.douban.com/
from urllib import request
import json
# url信息:interval_id表示排名段(可自行修改),limit限制20个
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20"
rsp = request.urlopen(url)
data = rsp.read().decode()
data = json.loads(data)
print(data)
运行结果
可以看到结果在一行显示

修改输出格式
- 对于返回的json数据,我们选择想要的内容,想要的格式输出
- 代码文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py19db2.py
# 爬取豆瓣电影数据
# 了解ajax的爬取方式
# https://movie.douban.com/
from urllib import request
import json
# url信息:interval_id表示排名段(可自行修改),limit限制20个
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20"
rsp = request.urlopen(url)
data = rsp.read().decode()
data = json.loads(data)
# 遍历输出每个'k'和'v'的值
for item in data:
print("排名:", item['rank'], "\n",
"名称:", item['title'], "\n",
"类型:", item['types'], "\n",
"主演:", item['actors'], "\n",
"分数:", item['score'],"\n-------------",)运行结果
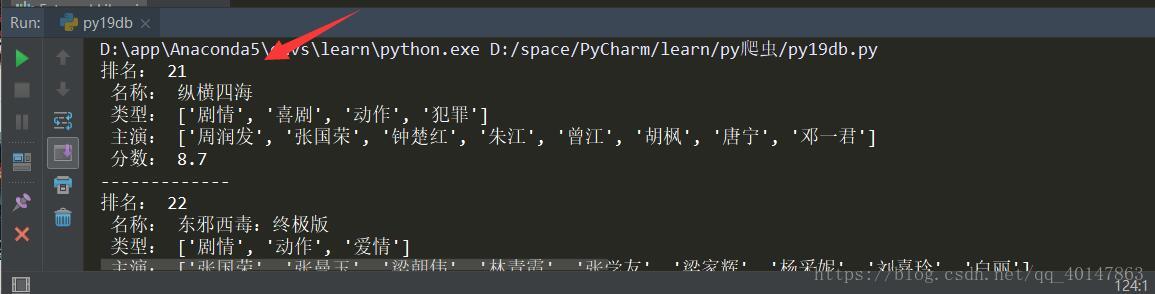
这里结果就比较顺眼了,如果需要更改排名段,因为是get请求,修改需要在url参数即可
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











