






如果你像我一样,经常在终端里敲着
git push,
却偶尔遇到莫名其妙的
Connection closed提示,
那你可能也正被云原生时代的「随机性」折磨着。
我是怎么撞见这只“幽灵”的?
作为一名程序员,我每天几乎都会和终端打交道。说起来有点玄学,但相信每个程序员都至少遇过一次这样的灵异事件:
上周三下午,我像往常一样敲下:
git push origin master
一切本该像过去的几千次一样顺畅,却意外出现了下面这个冰冷的错误提示:
kex_exchange_identification: Connection closed by remote host
Connection closed by 180.76.198.77 port 22
fatal: Could not read from remote repository.
我的第一反应当然是重试——每个程序员的条件反射动作。但事情变得有趣了:当我再次执行相同的命令时,竟然毫无障碍地通过了:
Enumerating objects: 10, done.
Counting objects: 100% (10/10), done.
Delta compression using up to 8 threads
...
remote: Resolving deltas: 100% (8/8), completed with 8 local objects.
To gitee.com:renda/project.git
9f3e1a8..c2b8d7f master -> master
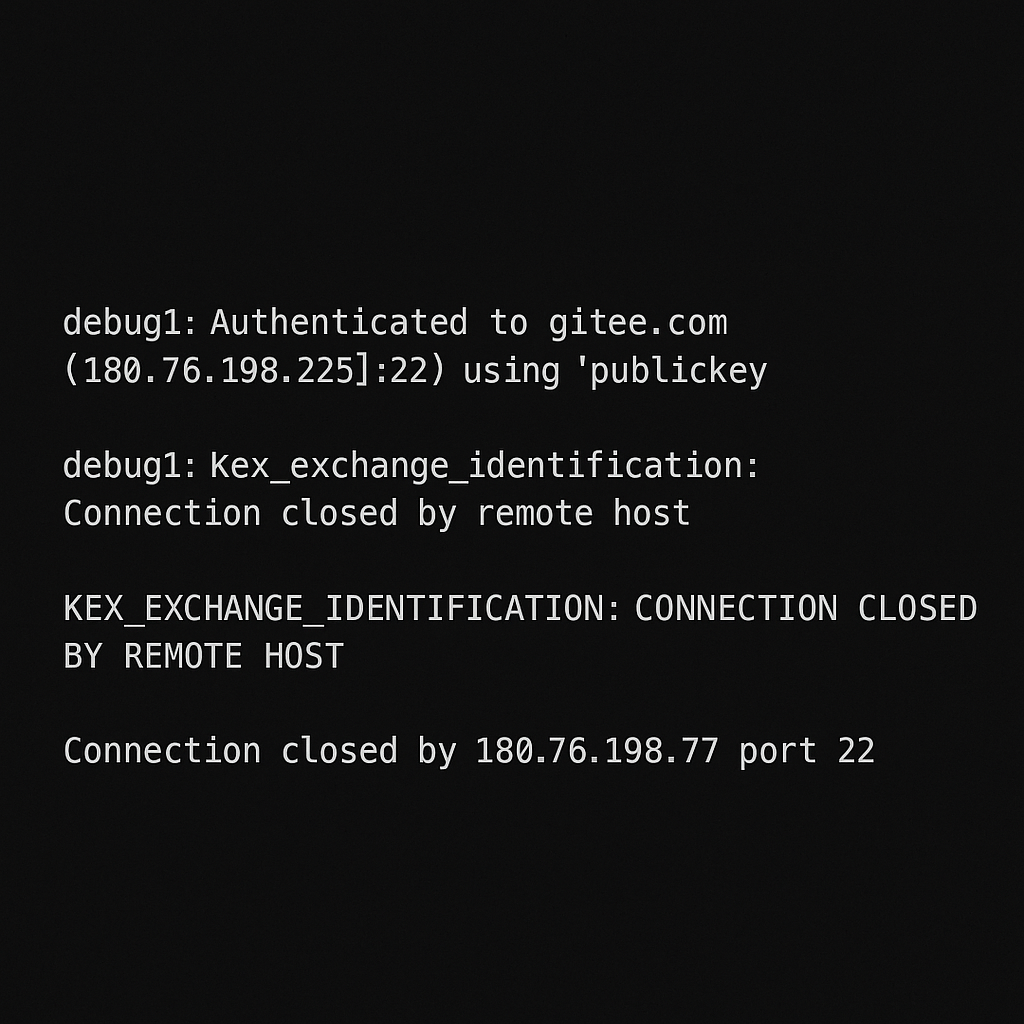
为了搞清楚到底发生了什么,我仔细检查了一下两次推送的连接节点:
-
成功连接的节点 IP 是
180.76.198.225 -
失败连接的节点 IP 是
180.76.198.77
显然,这不是我的密钥出了问题,否则不会第二次就莫名其妙地好了。这种“随机性”提醒着我,真正的问题很可能在服务端,或者更准确地说,在背后那个看不见摸不着的「云原生架构」里。
技术直觉让我决定更深地去挖一挖。
于是我打开了 SSH 调试模式,开始捕捉失败时更详细的信息:
ssh -vvv git@gitee.com
在详细日志里,我很快定位到这句关键的信息:
debug1: Connecting to gitee.com [180.76.198.77] port 22.
debug1: kex_exchange_identification: Connection closed by remote host
显然,是服务器主动关掉了我的连接请求。
这就是我第一次意识到,一个简单的 git push 背后,隐藏着巨大的不确定性。
它不仅关乎代码本身,更关乎这个时代最前沿的技术架构——云原生。
说得通俗一点:
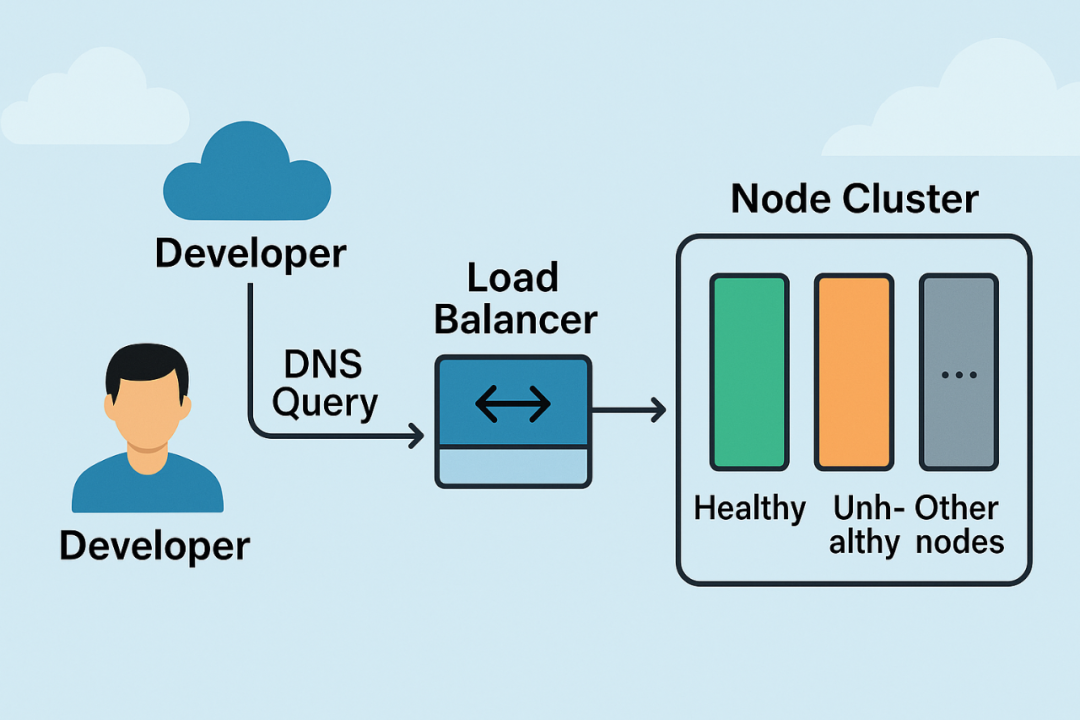
当我们使用 git push 推送代码时,实际上并不是连接到某一台固定的服务器上,而是连接到一个由许多服务器组成的集群里。
每一次连接,就像去银行取号排队,你永远不知道下一秒会被叫到哪个柜台办理业务。
但万一你被叫到了一个故障的柜台呢?
不好意思,你只能得到一句冰冷的「请重新排队」。
我的 SSH 连接失败,就源自于这个机制:随机地连到了一个正在「罢工」的服务器节点。
带着这个发现,我开始对云原生架构产生了更多的兴趣——以及一点恐惧。
这究竟是云原生架构的本质性缺陷,还是某种可控的“小问题”?
更重要的是,作为开发者,我该如何应对?
我决定继续深入探索。
原来,这就是云原生的“随机真相”
要搞懂为什么一个简单的 git push 操作会随机失败,首先我们得先来聊聊 云原生。
坦白说,我第一次听到“云原生”这个词的时候,还以为只是云厂商搞出来的又一个新概念——毕竟,这年头谁不想蹭点“云”的热度呢?
但当我真遇到问题、深入挖掘之后,才发现 云原生 确实有它的特别之处。
甚至可以说,我们平时使用的绝大多数网络服务,比如Gitee、GitHub、甚至微信、淘宝,都已经不知不觉间变成了云原生架构。
所以,到底什么是云原生呢?
云原生,到底是什么东西?
想象你在一家大型连锁餐厅吃饭。
你点了一道招牌菜,服务员记录好后,却并不是直接去后厨,而是通过一个自动系统,把你的订单随机分配给厨房中正在空闲的厨师。
如果厨师忙不过来了,系统会自动把订单转给另一位空闲厨师,甚至直接叫来临时厨师救场。
如果某位厨师突然生病或者炒锅坏了,系统就自动跳过他,把订单交给其他人。
你坐在餐厅里,只需要安心等待菜品送上桌,而不用关心背后究竟是哪位厨师炒的菜。
这,就是云原生架构的本质:
-
微服务(Microservices): 把服务拆解成更小的模块,各模块独立运行、互不影响。就像厨师专攻一道菜一样,每个人都有明确的职责和边界。
-
容器化(Containerization): 所有服务标准化打包,类似厨师统一使用标准化炒锅,确保所有服务启动起来都是标准流程,不会出岔子。
-
负载均衡(Load Balancing): 系统自动分配用户请求给多个服务节点,就像餐厅系统随机把订单分配给空闲的厨师一样。
-
弹性伸缩(Auto Scaling): 根据用户请求数量自动增减服务节点数量,类似饭点高峰期餐厅临时调来更多厨师,饭点过去再让他们休息去。
而我遇到的 SSH 连接随机失败问题,其实就出在这个环节:
每当我输入
git push的时候,我并不是固定连接到某台服务器,而是通过负载均衡器被随机指派到某个服务器节点。
如果被分配到的节点正常,万事顺利;
但万一节点出现了问题,那就是随机倒霉。
为什么服务器节点会突然“罢工”?
你可能会问,服务器又不像人类厨师一样会累,怎么会突然就不工作了呢?
事实上,服务器节点出问题的原因多种多样,常见的比如:
-
服务器过载: 用户请求太多,某个节点扛不住了,像炒菜时突然接到几百份订单,结果就是「爆单」。
-
滚动更新维护: 系统升级时,节点需要短暂下线或重启,这时如果负载均衡器没及时发现,它就成了一个短暂的「黑洞」,把请求全部吞掉。
-
网络抖动或分区: 数据中心的网络出问题了,类似厨师房间突然停电或断网了,系统无法联系到这个节点。
而负载均衡器本身,也并不是万能的。
传统的负载均衡器大多是定时(比如每隔几秒或几分钟)检测一下节点的健康状态:
-
如果检测间隔太长,那么在发现问题之前,用户请求已经被随机送进了“坑”里。
-
如果检测机制过于简单,有时候无法精准识别某些短暂且复杂的异常,导致故障节点未被及时隔离。
我的SSH连接问题,就是典型的节点健康检查机制失效:
当节点
180.76.198.77出现异常时,负载均衡器仍然持续把我的请求送给它,直到下次健康检查才能发现并隔离它。
到这里,我终于彻底明白了我的 SSH 故障背后的真正原因:
-
当我 SSH 到
gitee.com时,实际上是在跟一个“群”服务器连接。 -
每一次连接随机分配一个节点,大多数节点正常,但偶尔会碰上一个临时异常节点。
-
一旦碰上异常节点,我就只能倒霉重试,期待下次能被分配到一个健康的节点。
因此,这个问题不是个别现象,也不是偶然发生的“鬼故事”,而是现代互联网服务普遍存在的现象。
云原生的随机性,是它能提供高可用、高性能服务的代价之一。
不过,虽然我理解了这个机制,但作为程序员,这种“随机碰运气”的做法显然不是长久之计。
从技术排查到方案落地:我是如何与「云原生随机性」和平共处的
了解问题的本质之后,作为程序员,自然不能只停留在理解问题,更得动手解决问题——至少是减少这种随机性带来的困扰。
于是,我开始系统地排查与优化:
技术排查(SSH 诊断)
我总结了一套简单但有效的排查流程,任何人遇到类似问题都可以直接复用。
步骤一:检测节点端口是否可用
在遇到 SSH 连接失败时,最快速的确认方式是直接检查对应服务器节点的 22 端口是否开放:
nc -zv 180.76.198.77 22
正常情况下,会返回类似:
Connection to 180.76.198.77 port 22 [tcp/ssh] succeeded!
异常节点则会返回:
nc: connect to 180.76.198.77 port 22 (tcp) failed: Connection refused
如果端口拒绝连接,问题几乎可以确认就是节点服务异常。
步骤二:确认域名 DNS 解析状况
为了确保并非 DNS 缓存或异常导致请求一直被送到坏掉的节点,可以快速做一个 DNS 解析:
dig gitee.com
正常情况应该返回多个 IP 地址:
;; ANSWER SECTION:
gitee.com. 298 IN A 180.76.198.225
gitee.com. 298 IN A 180.76.198.77
gitee.com. 298 IN A 180.76.198.152
如果 DNS 返回结果始终只有一个 IP,说明可能是缓存或解析问题,需要手动刷新 DNS 缓存:
-
Windows:
ipconfig /flushdns
-
Linux (Ubuntu):
sudo systemd-resolve --flush-caches
步骤三:详细 SSH 日志排查
如果以上两步未完全定位问题,启用 SSH 调试模式:
ssh -vvv git@gitee.com
找到出现问题的关键日志:
-
正常连接会提示认证成功:
Authenticated to gitee.com using "publickey"
-
异常连接提示:
kex_exchange_identification: Connection closed by remote host
如果总在特定节点失败,基本可以确定就是该节点问题。
客户端层面的临时方案(快速止损)
知道原因后,我也总结了两条能快速应急的方法:
SSH over HTTPS 方案(绕过 22 端口)
某些平台支持 SSH 通过 443 端口访问(HTTPS 通道),这样基本规避了 22 端口随机故障:
# ~/.ssh/config
Host gitee.com
Hostname altssh.gitee.com
Port 443
User git
我实际测试过几次,这个方案能快速解决临时 SSH 无法连接的尴尬问题。
Git 客户端重试机制
如果你用的是 HTTP 协议的 Git,也可以配置客户端自动重试策略:
git config --global http.autoRetry true
git config --global http.retryTimeout 30
这样一旦连接失败,Git 会自动帮你重试,节省手动重试的麻烦。
服务端优化
当然,作为一名对技术始终怀抱热情的程序员,我更希望从根源上减少这类随机问题的发生。
如果你有权限或者你是团队的 SRE,可以从以下几方面入手:
优化负载均衡节点健康检查频率
传统的健康检查周期通常是几分钟一级,如果缩短为秒级,会更快发现节点异常并自动隔离:
-
Kubernetes + Nginx Ingress 实例:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: gitee-ingress
annotations:
nginx.ingress.kubernetes.io/health-check: "true"
nginx.ingress.kubernetes.io/health-check-interval: "5s"
服务网格(Service Mesh)自动熔断机制
引入 Service Mesh (如 Istio) 之后,可配置更精细的故障重试与熔断策略:
retries:
attempts: 3
perTryTimeout: 1s
retryOn: reset,connect-failure
实时熔断工具(Netflix Hystrix)
如果你们团队使用 Java 微服务,Hystrix 也可以实现快速自动隔离:
if (node.errorRate() > 10% && node.latency() > 1000) {
loadBalancer.isolate(node);
}
我的最终选择和思考
在这次实际遇到的 SSH 随机失败案例中,我最终采用了:
-
客户端 SSH over HTTPS 绕行方案快速止损
-
和平台服务商反馈,推动其服务端优化健康检查机制,减少根源性问题
经历这一次故障排查,我对云原生的理解更深了:
云原生的本质就是牺牲确定性换取高性能与灵活性,我们无法彻底消灭随机性,但能通过技术手段控制它的影响范围。
当我们对云原生随机性“握手言和”之后,也意味着我们真正进入了这个时代。
为什么连投资人都应该关注这样的小故障?
写到这里,你可能会好奇:
这种 SSH 连接偶尔失败的问题,程序员折腾一下也就过去了,为什么投资人或公司管理层也需要关注?
其实我自己在刚入行的时候,也很难理解这种「微小的技术问题」究竟有什么大不了的。
但工作几年下来,经历的技术事故越来越多,我开始明白一个道理:
大多数致命的技术危机,最初往往只是一些不起眼的小故障。
从技术人员到企业管理者,再到投资人,都必须清楚地知道:
一个简单的 SSH 连接问题背后,可能隐藏着企业整体架构的潜在风险。
投资人视角下的「技术指标」
假设你是一个投资人,准备投一家刚刚崛起的互联网公司。
你对他们的技术团队进行尽职调查时,关注的不应该只是营收、用户增长,而应该进一步了解技术稳定性背后的数据:
比如这次我遇到的 SSH 故障,反映出的正是云原生架构里一些容易忽略的关键指标:
|
技术指标 |
优秀标准 |
警告标准 |
背后隐含的技术风险 |
|---|---|---|---|
|
节点故障隔离速度 |
< 10秒 |
> 60秒 |
架构或监控机制存在缺陷 |
|
服务自动恢复成功率 |
> 99.99% |
< 95% |
系统缺乏自愈能力,故障成本高昂 |
|
跨区域灾备能力 |
多区域部署 |
单点部署 |
存在单点故障隐患,潜在损失巨大 |
这些看似细碎的指标,真实反映的是企业在稳定性上的技术负债:
-
如果节点故障未及时隔离,就像一个坏掉的零件迟迟未更换,迟早引起系统级崩溃;
-
如果系统无法自我恢复,每一次故障都要靠人工抢救,那么运营成本将非常高昂;
-
如果没有跨区域的容灾能力,一旦数据中心意外下线,损失的将不仅仅是业务,甚至是整家公司的品牌价值。
我曾亲身经历过一次公司的技术事故,
当时我们的负载均衡机制存在缺陷,某个故障节点未被及时隔离,导致接近 30% 的用户随机登录失败。
这本来只是个技术小故障,却在短短几个小时内引发了用户大量流失,
最后严重影响了公司的市场估值,甚至一度险些融资失败。
同样的故事其实并不少见:
-
某云厂商因一次网络路由异常,持续数小时无法隔离故障节点,导致大量企业客户服务宕机,品牌信誉严重受损;
-
某电商平台因为跨区域容灾机制缺失,导致一次机房故障造成上千万级的经济损失。
这些都不是什么特别复杂的问题,起因往往只是几个节点、几个配置的问题,
但却因为技术债务的积累,最终引发致命的商业危机。
为什么投资人应关心技术稳定性?
投资人关注这些技术细节的本质原因,是因为技术稳定性早已成为企业竞争力的重要组成部分:
-
用户体验和口碑
互联网时代,用户体验是一切业务增长的基础。
SSH 连接失败一次可能用户不会察觉,但背后如果有潜在风险,迟早会发生影响到用户端的大规模故障,届时用户信任成本将是天文数字。
-
可扩展性与成长性
一家公司的业务扩张必然伴随技术规模的扩大。
如果早期技术架构不稳健,那么扩展过程中技术负债就像雪球一样迅速膨胀,最终拖累公司成长速度,甚至卡住整个公司的增长曲线。
-
投资安全性
技术风险越低,投资人资金的安全边际就越高。
相反,如果企业频繁出现技术事故,每次事故都意味着额外的资本投入和业务损失,这种企业即使前期营收不错,长期看也并不是好投资。
反思与建议
从一个程序员的角度,给投资人和企业决策者的建议是:
-
定期审视技术架构的健康状态,不要忽略小故障背后的风险;
-
鼓励团队建设系统级的实时监控与自动化故障处理能力;
-
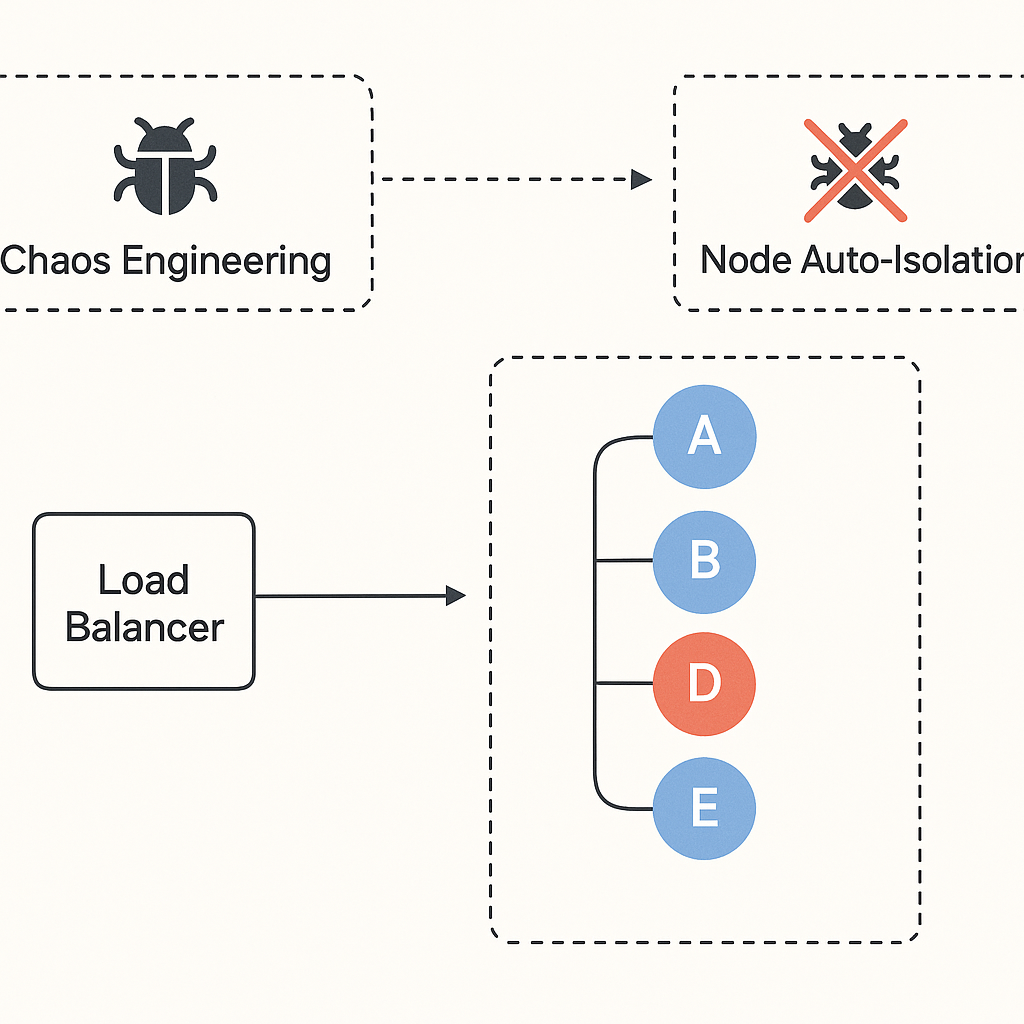
技术团队应定期开展混沌工程(Chaos Engineering),主动模拟故障来验证系统韧性。
只有这样,我们才能确保企业在快速发展的同时,技术架构不成为发展的瓶颈,更不会在关键时刻拖企业后腿。
好的技术架构,就是企业稳定增长的基石。
作为开发者,我日常如何避免“云原生随机坑”?
说了这么多大的架构和投资视角上的问题,最后,我想回到最熟悉的开发者角度。毕竟,无论问题多宏大,最直接面对故障和背锅的,始终还是我们这些敲代码的人。
回到开头那个「SSH 随机失败」的小插曲,它给我最深的教训之一就是:
你无法彻底消除云原生架构带来的随机性,但你可以提前做好准备。
换句话说,作为开发者,我们必须主动采取一些措施,避免自己被这类随机问题搞得焦头烂额。
下面我整理了一些平时自己实际在用的「生存指南」,希望对你也有帮助。
客户端技巧(日常必备)
SSH 多端口策略(绕过常规端口故障)
无论你用的是 GitHub、Gitee,还是企业内部的 Git 仓库,建议都提前配置好备选方案:
比如 SSH over HTTPS:
# ~/.ssh/config
Host gitee.com
Hostname altssh.gitee.com
Port 443
User git
-
这么一来,如果默认 22 端口抽风了,你就可以立刻切换到备用通道,节省大量排查时间。
Git 配置自动重试(HTTP 模式下更有效)
如果你团队的仓库是用 HTTP 方式连接的,建议直接开启 Git 客户端的重试功能:
git config --global http.autoRetry true
git config --global http.retryTimeout 30
-
不用你手动重试,Git 就能自动搞定。虽然不是万能,但至少节省了手动反复尝试的烦躁感。
使用 VPN 或切换网络环境
这招最土,却也是最有效的办法之一。如果你怀疑是本地网络抖动,直接开个 VPN 或者换个网络环境试一下。毕竟,有时候真的是运营商的锅,而不是你代码的锅。
服务端与运维角度的建议(开发者如何推动优化?)
作为开发者,虽然我们未必能完全掌控服务端的架构决策,但至少可以向团队 SRE 或 DevOps 同事积极反馈、推动改进:
缩短负载均衡器健康检查周期
最直观有效的改善手段,就是要求负载均衡器更快识别并隔离故障节点:
-
例如 Kubernetes 配置 Nginx Ingress:
annotations:
nginx.ingress.kubernetes.io/health-check: "true"
nginx.ingress.kubernetes.io/health-check-interval: "5s"
-
将健康检查从分钟级提升到秒级,效果立竿见影。
推动引入服务网格(如 Istio)
Istio 等 Service Mesh 工具,提供了自动熔断和重试机制。
虽然初期成本较高,但长期来看非常值得:
retries:
attempts: 3
perTryTimeout: 1s
retryOn: reset,connect-failure
-
通过细粒度的策略自动应对节点随机故障,极大提升用户体验。
建议团队定期做混沌工程测试
开发者也应该主动建议运维团队定期开展“混沌工程”,
通过主动注入故障(Chaos Engineering),提前发现系统的薄弱环节:
-
示例工具(Chaos Mesh):
chaos mesh inject node-failure -n git-node-77 --duration 5m
-
主动引发故障,比被动应急要舒服得多。
开发日常的“习惯养成”
当然,除了技术本身,良好的开发习惯同样能帮我们有效降低遇到随机故障时的成本:
-
随时保存与备份代码
别总等到要提交时再push代码,提前备份,总是更安全。
-
本地维护多分支
如果远程分支暂时无法更新,本地单独开分支继续开发,不至于被一个连接问题卡死。
-
记录与分享异常经验
遇到故障及时做简单记录,下次再碰到时可以快速参考或分享给团队,形成良性循环。
心态上的调整与经验总结
经历了不少次“随机事件”,我慢慢意识到:
-
云原生时代,服务的复杂性注定会带来不确定性。 作为程序员,我们能做的不是抱怨,而是主动了解、适应,并提前做好应急预案。
-
保持好奇心,多了解一点底层原理。 每个看似偶然的问题背后,其实都有迹可循。了解越多,应对越从容。
回头想想,这次 SSH 随机失败的经历,其实也给了我一次难得的学习机会。
「技术进步的本质,往往就是一次又一次直面问题,并解决问题的过程。」
从这次小故障出发,谈谈我对云原生未来的看法
回顾整个 SSH 随机失败事件,一开始只是觉得诡异、难缠,但当我真的把问题一层层剥开后,却意外地收获了不少深入的思考。
坦率地说,这几年,「云原生」这个词已经快被用烂了,各种场合到处都是它的身影,以至于很多开发者一听到就开始疲惫和抗拒。我最初也是如此。
但这次真实的经历却让我意识到:
云原生不只是流行的技术概念,
更是我们当前所处的开发环境的本质特征
—— 复杂、不确定,却又不可避免。
站在这个视角上,我想分享一下自己对云原生未来发展趋势的一些个人看法。
趋势一:云原生架构的「确定性革命」
云原生带来的高灵活性与弹性伸缩,本质上以“不确定性”为代价。但这种不确定性不能永远任由开发者承担,于是下一波技术潮流一定是围绕提升云原生架构的确定性展开:
-
实时监控与秒级响应机制将逐渐成为行业标配,而不再是高阶玩家的专利。
Kubernetes、服务网格将更加精细化,让服务端的不确定性被精准控制在最小范围。
-
自动化运维(GitOps、AIOps) 将进一步成熟。
通过机器学习算法提前预测潜在故障,并自动隔离,将大幅提升服务的稳定性与可靠性。
-
混沌工程(Chaos Engineering) 不再只是少数巨头的游戏,而会成为大部分团队的标配工具。
主动引入故障验证系统韧性,会逐渐成为企业技术稳定性审计的必经之路。
换句话说:
未来的云原生,一定是“不确定性”逐渐被技术手段“确定化”的过程。
趋势二:开发者与云原生架构的协作将更加紧密
过去几年,我们通常把云原生架构看成「黑盒子」,代码一扔进去就完事儿。
但经历了这次故障之后,我越发意识到:
云原生架构的可靠性不仅取决于基础设施,更取决于开发者的参与深度。
未来的开发流程一定是:
-
开发者更主动地介入容器编排与服务网格层面,而不是完全依赖于运维;
-
开发者写代码时会更多地考虑到系统的弹性和韧性,而非只关注业务逻辑;
-
基础设施和应用开发的界限会逐渐模糊,开发者与运维的界限也将进一步淡化。
而这种趋势已经初见端倪:
-
越来越多的开发者主动学习 Kubernetes 和 Istio,哪怕只是在个人开发环境里使用;
-
越来越多的开发工具(例如 VS Code、GitHub Codespaces 等)开始将容器化和云原生能力内置其中。
未来,掌握云原生技术不再是开发者的额外技能,而是基础素养之一。
趋势三:投资与企业决策更加关注技术架构的韧性
这几年,技术故障导致的巨额损失案例层出不穷,投资人和企业高管们开始意识到:
技术架构的稳健性与弹性能力,实际上是企业的核心竞争力之一。
未来,企业融资、估值、上市准备时,对技术架构的尽职调查会更加精细深入,具体表现在:
-
技术债务水平成为投资人考核的关键指标;
-
容灾能力与故障自愈能力成为上市企业必备的技术合规审计内容之一;
-
企业内部会更积极地推动系统性故障管理、应急演练,并重视技术团队的投入产出比。
说到底:
技术不再仅仅是业务增长的辅助,而将直接决定企业的长期竞争力和生存能力。
建议(技术选型视角)
-
主动接触与学习容器、Kubernetes、服务网格技术。
哪怕你的团队还没有用,提前学习和了解,绝对能让你在未来几年更有竞争力。
-
开发日常就要养成「韧性开发」的意识。
代码不要只追求性能与功能,也要考虑异常、降级与弹性,这会让你的程序在云原生环境中活得更好。
-
多参与架构与运维的沟通与实践。
打破开发和运维之间的“墙”,主动了解基础设施的运作原理,避免将架构视作“黑盒”。
-
积极了解行业内故障案例与经验教训。
每一次行业重大事故,都是一次宝贵的免费教学,帮助我们更清晰地看见潜在风险。
最后的思考
回头看这次看似不起眼的 SSH 随机失败事件,我很庆幸自己没有只是简单抱怨一下就过去,
而是真正地去挖掘背后的原因,最终让我看到了更多关于云原生的本质和趋势。
一个小故障的背后,往往隐藏着整个技术时代的演进轨迹。
愿你我都能抱着对技术的好奇心,不断挖掘、不断进步。
毕竟,未来并不会属于任何特定的技术或框架,而一定属于始终保持学习、拥抱变化的程序员。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









