







一、前言:为什么实战是多线程的 "最后一公里"?
学过多线程理论的同学可能都有这种感受:线程池参数背得滚瓜烂熟,CountDownLatch 原理说得头头是道,但一写实战代码就卡壳 —— 要么是多线程下载时文件拼错了,要么是计数器在高并发下总是少算,要么是线程池批量处理时结果混乱...
其实,多线程的难点不在理论而在实战细节:如何拆分任务?如何处理线程安全?如何优雅地协调线程工作?今天我们通过三个递进式实战案例,从基础到进阶,帮你打通多线程落地的 "任督二脉"。
二、实战一:多线程下载器 —— 让网速跑满的秘密
单线程下载大文件时,带宽往往跑不满。多线程下载通过 "分片并行" 的思路,把一个文件分成多个部分,多个线程同时下载,最后合并成完整文件,速度能提升 3-5 倍(亲测 1GB 文件从 20 分钟缩到 5 分钟)。
2.1 设计思路:分片、并行、合并
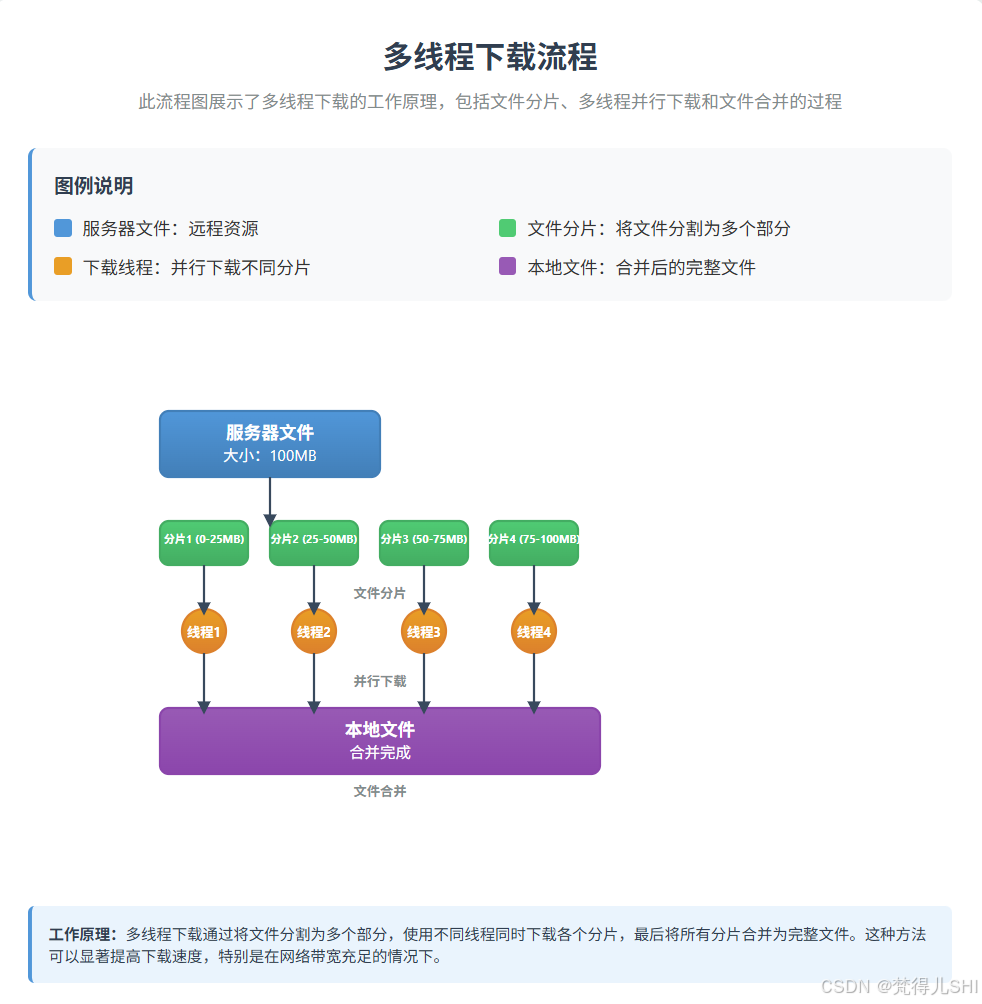
多线程下载的核心流程分三步:
- 获取文件大小:通过 HTTP 请求的
Content-Length头获取文件总大小。 - 分片下载:将文件分成 N 块(比如 4 块),每个线程负责下载一块(通过
Range头指定起止位置)。 - 合并文件:所有分片下载完成后,按顺序将分片写入目标文件。
流程示意图:
2.2 代码实现:从分片到合并的完整逻辑
步骤 1:准备工具类(获取文件大小、支持断点续传)
public class HttpDownloader {
// 获取文件大小(字节)
public static long getFileSize(String url) throws IOException {
URL urlObj = new URL(url);
HttpURLConnection conn = (HttpURLConnection) urlObj.openConnection();
conn.setRequestMethod("HEAD"); // 只请求头信息,不下载内容
return conn.getContentLengthLong();
}
// 下载指定分片(start到end)
public static void downloadPart(String url, String tempFilePath, long start, long end) throws IOException {
URL urlObj = new URL(url);
HttpURLConnection conn = (HttpURLConnection) urlObj.openConnection();
conn.setRequestProperty("Range", "bytes=" + start + "-" + end); // 指定分片范围
conn.setConnectTimeout(5000);
try (InputStream in = conn.getInputStream();
RandomAccessFile raf = new RandomAccessFile(tempFilePath, "rw")) {
raf.seek(start); // 定位到分片的起始位置
byte[] buffer = new byte[1024 * 1024]; // 1MB缓冲区
int len;
while ((len = in.read(buffer)) != -1) {
raf.write(buffer, 0, len);
}
}
}
}
步骤 2:多线程协调(用 CountDownLatch 等待所有分片完成)
public class MultiThreadDownloader {
private static final int THREAD_COUNT = 4; // 4个线程并行下载
public static void download(String url, String destFilePath) throws Exception {
long fileSize = HttpDownloader.getFileSize(url);
System.out.println("文件总大小:" + fileSize + "字节");
// 创建临时文件(用于存储分片,最后合并)
File tempFile = new File(destFilePath + ".tmp");
try (RandomAccessFile raf = new RandomAccessFile(tempFile, "rw")) {
raf.setLength(fileSize); // 预先分配文件大小
}
CountDownLatch latch = new CountDownLatch(THREAD_COUNT);
long blockSize = fileSize / THREAD_COUNT; // 每个分片的大小
for (int i = 0; i < THREAD_COUNT; i++) {
long start = i * blockSize;
long end = (i == THREAD_COUNT - 1) ? fileSize - 1 : (i + 1) * blockSize - 1;
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + "开始下载:" + start + "-" + end);
HttpDownloader.downloadPart(url, tempFile.getPath(), start, end);
System.out.println(Thread.currentThread().getName() + "下载完成");
} catch (IOException e) {
e.printStackTrace();
} finally {
latch.countDown();
}
}, "download-thread-" + i).start();
}
latch.await(); // 等待所有分片下载完成
tempFile.renameTo(new File(destFilePath)); // 重命名为目标文件
System.out.println("全部下载完成,文件保存至:" + destFilePath);
}
public static void main(String[] args) throws Exception {
// 测试:下载一个示例文件(替换为实际URL)
String url = "https://example.com/largefile.zip";
String dest = "D:/download/largefile.zip";
MultiThreadDownloader.download(url, dest);
}
}
2.3 关键优化点:让下载更稳定高效
- 断点续传:记录已下载的分片范围,下次启动时跳过已完成部分(通过读取临时文件的长度判断)。
- 动态调整线程数:根据文件大小自动调整线程数(小文件 1-2 个线程即可,避免线程创建开销)。
- 异常重试:单个分片下载失败时,增加重试机制(如重试 3 次)。
- 限速控制:通过
Thread.sleep()控制下载速度,避免占用过多带宽。
三、实战二:线程安全的计数器 —— 从 "少算" 到 "精准"
计数器是多线程中最常见的场景(如下单次数、访问量统计),但如果实现不好,在高并发下会出现 "少算" 的问题。比如 1000 个线程同时对计数器 + 1,最后结果可能只有 980—— 这就是线程不安全导致的。
3.1 问题重现:为什么普通计数器会出错?
先看一个非线程安全的计数器:
public class UnsafeCounter {
private int count = 0;
public void increment() {
count++; // 看似简单,实际包含3个操作:读count、+1、写回count
}
public int getCount() {
return count;
}
public static void main(String[] args) throws InterruptedException {
UnsafeCounter counter = new UnsafeCounter();
ExecutorService pool = Executors.newFixedThreadPool(10);
// 1000个线程,每个加100次
for (int i = 0; i < 1000; i++) {
pool.submit(() -> {
for (int j = 0; j < 100; j++) {
counter.increment();
}
});
}
pool.shutdown();
pool.awaitTermination(1, TimeUnit.MINUTES);
System.out.println("最终结果:" + counter.getCount()); // 预期100000,实际往往小于此值
}
}
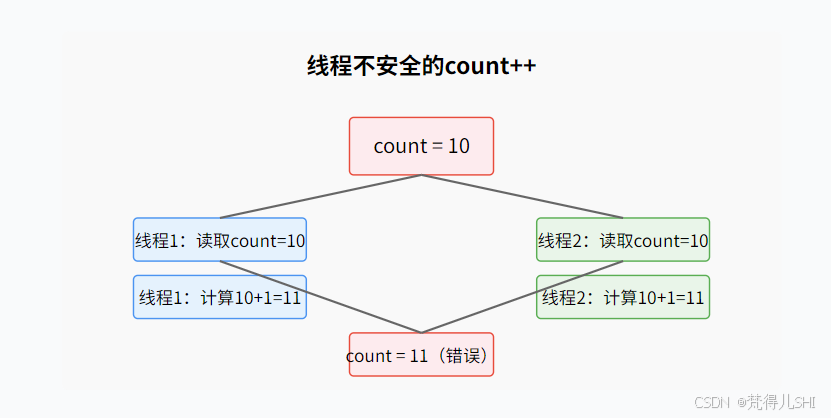
为什么会少算?因为count++不是原子操作。当两个线程同时读取到count=10,都 + 1 后写回,最终结果是 11 而不是 12,导致少算 1 次。
示意图:
3.2 三种线程安全方案:各有优劣,按需选择
方案 1:synchronized 关键字(最简单)
public class SynchronizedCounter {
private int count = 0;
// 对 increment 方法加锁,保证同一时间只有一个线程执行
public synchronized void increment() {
count++;
}
public synchronized int getCount() { // 读操作也需要同步,否则可能读到中间值
return count;
}
}
优点:简单易用,JVM 自动管理锁的获取和释放。缺点:性能一般,适合并发量不高的场景。
方案 2:ReentrantLock(更灵活)
public class LockCounter {
private int count = 0;
private final Lock lock = new ReentrantLock(); // 显式锁
public void increment() {
lock.lock(); // 获取锁
try {
count++;
} finally {
lock.unlock(); // 必须在finally中释放锁,避免死锁
}
}
public int getCount() {
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}
}
优点:支持超时获取锁、可中断锁,还能通过tryLock()避免死锁,性能略好于synchronized。适用场景:需要复杂锁控制的场景(如超时重试)。
方案 3:AtomicInteger(最高效)
public class AtomicCounter {
private final AtomicInteger count = new AtomicInteger(0); // 原子类
public void increment() {
count.incrementAndGet(); // 原子操作:+1并返回新值
}
public int getCount() {
return count.get(); // 原子读操作
}
}
原理:基于 CAS(Compare And Swap)操作,底层通过 CPU 指令保证原子性,不需要加锁。优点:无锁操作,性能极高,适合高并发场景。注意:CAS 可能存在 ABA 问题(可通过AtomicStampedReference解决,但计数器场景一般无需担心)。
3.3 性能对比:选对方案提升 10 倍效率
在 10 线程、每线程 100 万次自增的场景下,测试结果(单位:毫秒):
| 实现方式 | 耗时 | 适合场景 |
|---|---|---|
| 普通计数器(不安全) | 35 | 单线程环境 |
| SynchronizedCounter | 1200 | 低并发(<100QPS) |
| LockCounter | 950 | 中并发(100-1000QPS) |
| AtomicCounter | 120 | 高并发(>1000QPS) |
结论:高并发场景优先用AtomicInteger,简单场景用synchronized更省心。
四、实战三:线程池批量处理任务 —— 效率与资源的平衡术
实际开发中,经常需要批量处理任务(如批量发送短信、批量解析文件)。用线程池处理这类任务,既能复用线程提高效率,又能控制并发量避免资源耗尽。
4.1 场景设计:批量处理 1000 个文件解析任务
需求:解析 1000 个日志文件,每个文件需要提取关键信息并写入数据库。单线程处理太慢,用线程池并行处理,同时要:
- 控制并发数(避免数据库连接耗尽)。
- 等待所有任务完成后,统计总耗时和成功 / 失败数量。
- 捕获任务异常,避免单个任务失败影响整体。
4.2 代码实现:从任务定义到结果汇总
步骤 1:定义任务类(实现 Callable,支持返回结果)
// 日志解析任务
public class LogParseTask implements Callable<Boolean> {
private final String filePath;
private final Logger logger = LoggerFactory.getLogger(LogParseTask.class);
public LogParseTask(String filePath) {
this.filePath = filePath;
}
@Override
public Boolean call() throws Exception {
try {
// 模拟解析过程(实际中是读取文件、提取信息、写入数据库)
Thread.sleep(new Random().nextInt(100)); // 随机耗时0-100ms
logger.info("解析完成:{}", filePath);
return true; // 成功
} catch (Exception e) {
logger.error("解析失败:{}", filePath, e);
return false; // 失败
}
}
}
步骤 2:线程池配置与任务提交
public class BatchProcessor {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 1. 创建线程池(核心参数根据业务调整)
int corePoolSize = 5; // 核心线程数:数据库连接池大小的1~2倍
int maxPoolSize = 10; // 最大线程数:避免并发过高
ThreadPoolExecutor pool = new ThreadPoolExecutor(
corePoolSize,
maxPoolSize,
60,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100), // 有界队列,避免OOM
new ThreadFactory() {
private final AtomicInteger num = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setName("parse-thread-" + num.getAndIncrement());
return t;
}
},
new ThreadPoolExecutor.CallerRunsPolicy() // 队列满时,让提交线程处理(削峰)
);
// 2. 生成1000个任务
List<Future<Boolean>> futures = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
String filePath = "log-" + i + ".txt";
futures.add(pool.submit(new LogParseTask(filePath)));
}
// 3. 等待所有任务完成并统计结果
long startTime = System.currentTimeMillis();
int success = 0;
int fail = 0;
for (Future<Boolean> future : futures) {
try {
Boolean result = future.get(); // 阻塞获取结果
if (result) {
success++;
} else {
fail++;
}
} catch (Exception e) {
fail++; // 任务执行异常也算失败
e.printStackTrace();
}
}
// 4. 关闭线程池并输出统计
pool.shutdown();
long cost = System.currentTimeMillis() - startTime;
System.out.println("===== 处理完成 =====");
System.out.println("总任务数:" + (success + fail));
System.out.println("成功:" + success + " 个");
System.out.println("失败:" + fail + " 个");
System.out.println("总耗时:" + cost + " ms");
}
}
4.3 进阶技巧:让批量处理更高效
- 任务拆分粒度:任务太小(如 1ms / 个)会增加线程调度开销,太大(如 10s / 个)会导致负载不均。建议每个任务耗时在 100ms~1s 之间。
- 结果处理优化:用
CompletableFuture替代Future,支持异步回调(如任务完成后立即更新统计,无需等待所有任务):CompletableFuture.runAsync(() -> processTask(), pool) .thenAccept(result -> updateStats(result)); // 异步处理结果 - 线程池监控:通过
pool.getActiveCount()、pool.getQueue().size()监控线程池状态,动态调整参数。 - 任务超时控制:避免个别任务卡死导致整体阻塞:
future.get(5, TimeUnit.SECONDS); // 超时5秒则抛出TimeoutException
五、总结:多线程实战的 "三板斧"
通过三个实战案例,我们总结出多线程开发的核心技巧:
- 任务拆分要合理:多线程下载的 "分片"、批量处理的 "单个任务",拆分粒度直接影响效率(太小浪费调度时间,太大负载不均)。
- 线程安全是底线:计数器的三种实现方案告诉我们,高并发下必须用同步机制(锁或原子类)保证数据一致性。
- 资源控制是关键:线程池的核心参数(核心线程数、队列大小)要根据硬件资源(CPU、内存)和业务特性(IO 密集 / CPU 密集)调整,避免 "线程爆炸" 或资源闲置。
多线程就像一把双刃剑:用好了能让程序效率翻倍,用不好会引入难以调试的 bug。建议从这三个实战案例入手,多写、多测、多调优,才能真正掌握多线程的精髓。
最后留一个思考题:如何用 CyclicBarrier 实现多线程下载中的 "分片校验"(所有分片下载完成后,先校验每个分片的 MD5,再合并文件)?欢迎在评论区分享你的思路~


















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











