






Hadoop从无到有集群搭建
一、搭建环境
1.主机为win10(这个没什么影响)
2.虚拟机软件为VMware10
3.Linux系统为CentOS 7(两台:Master和Slave1)
4.100首轻松愉悦的歌曲(初次安装,心态容易炸掉)
二、大致步骤

从Linux的快照当中我们可以看到博主此次配置并不怎么顺利,也提醒各位养成拍快照的习惯,不然到时候配置失败,一团乱麻,都不知道从什么地方开始,最好每一个步骤成功就拍一张,以策万全。
注:步骤中加了 ** 号的,是需要主节点和从节点都要完成的。
1.创建hadoop用户 **
2.配置网络环境,能安装软件 **
3.Hadoop单机配置
4.Hadoop伪分布式配置
5.hadoop环境变量配置 **
6.运行Hadoop实例
三、整体实践
1.创建hadoop用户 **
博主本人是在配置过的基础上写的博客,因此,仅仅给出相关命令,以及相关配置信息
$ useradd -m hadoop -s /bin/bash # 创建新用户hadoop
$ passwd hadoop # 为用户添加密码两个机器上都要进行配置,为了方便,主节点可取名为master,从节点为slave1,接下来也用这两个名字加以区分。
为了以后操作方便,为hadoop用户赋予权限
$ visudo
我们要修改的位置应该是第93行,因此进入编辑界面后,按一下Esc,然后使用 :93 找打我们需要修改的地方。然后添加如下图的信息(红色方框中的位置)。

然后保存信息,按Esc,使用 :wq保存。
使用logout命令登出,然后登录刚才创建的hadoop用户。
2.配置网络环境,安装相关软件 **
首先我们将网卡修改为桥接模式,然后修改网络文件
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33 #修改网络配置文件
注意修改红色字体部分。然后重启一下网卡
sudo systemctl restart network1)安装ssh,并配置无密码登录 **
sudo yum -y install openssh-clients
sudo yum -y install openssh-serve
接下来,在Master上进行操作
ssh localhost输入yes,并输入密码进行登录,登录之后,按使用exit命令退出ssh登录。
然后接下来配置无密码登录。
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 ./authorized_keys # 修改文件权限(转载自厦大博客平台)配置完之后,再用ssh localhost登录就不需要密码了。
2)安装Java环境 **
sudo yum -y install java-1.7.0-openjdk java-1.7.0-openjdk-devel
vi ~/.bashrc在最后加入如下一行字,最后的目录名可能不一样,按照自己的添加便是。

编辑完了依然要保存退出。然后使用如下命令
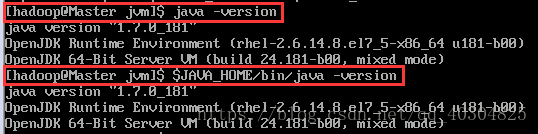
sudo source ~/.bashrc # 使变量设置生效检验我们配置是否正确,使用截图的两个命令,看到的内容应该是一样的。
3)安装Hadoop2 **
这是一个小难点,我们首先要安装的wget,这是一款可以从网页上下载软件的一个软件,博主在安装Hadoop2这里整了很久,最终才将其安装完毕。
yum -y install wget安装完毕之后,使用命令
sudo wget -P /root http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz #下载Hadoop2.7.6的压缩文件,并安装至指定root目录下然后我们将文件解压至/usr/local目录下,使用命令
sudo tar -zxf ~/root/hadoop-2.7.6.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.7.6/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
然后我们可以看到如下文件,表明我们安装成功了。

cd /usr/local/hadoop
./bin/hadoop version #查看版本Hadoop版本信息3.Hadoop单机配置
在进行这一步操作之前,我们最好将Linux的IP地址设置为静态的,方便以后我们管理,使用命令
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33 #修改网络信息
我们首先修改两台虚拟机的主机名
nmcli general hostname Master #相应主机进行相应的修改我们接下来修改一下我们的hosts文件
sudo vi /etc/hosts修改为如下信息

然后我们可以用Master去ping Slave1 -c 3

然后,我们测试一下伪分布的成果
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果运行结果应该为如下信息

4.Hadoop伪分布式配置
sudo vi ~/.bashrc #配置文件在该配置文件下方,加入如下信息

然后再令文件生效
source ~/.bashrc然后我们进入/usr/local/hadoop/etc/hadoop目录下,修改core-site.xml文件。
PS:hadoop的配置文件是以.xml为后缀的,之后,我们还会配置这两个文件,在Hadoop集群搭建中十分重要。
将其中的<configuration>
</configuration>
修改为如下
- <configuration>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/usr/local/hadoop/tmp</value>
- <description>Abase for other temporary directories.</description>
- </property>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
同样的,修改hdfs-site.xml,将其修改为如下文件
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/usr/local/hadoop/tmp/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/usr/local/hadoop/tmp/dfs/data</value>
- </property>
- </configuration>
然后,我们执行如下命令,对hadoop进行格式化,注意,在执行前,请拍摄快照,这一步很容易出错,而且格式化次数多了会引来更大的问题。
./bin/hdfs namenode -format如果成功,会出现successfully format和Exiting with status 0这两个提示信息。(处于不同位置,一般看到后面这个信息的话,就差不多足够了,也相对较容易发现)
然后我们开启namenode和datanode
使用命令
./sbin/start-dfs.sh然后,启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode”和“secondarynamenode”
------------------------------------------------------------------------------------------------------
分割线,今天太晚了,明天再做Hadoop俩节点的配置。
wasj















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









