







软件版本:
JDK:1.8.0_131
Hadoop:2.7.2
Scala:2.11.12
Spark:2.4.3
一、下载Spark源代码
https://archive.apache.org/dist/spark/spark-2.4.3/
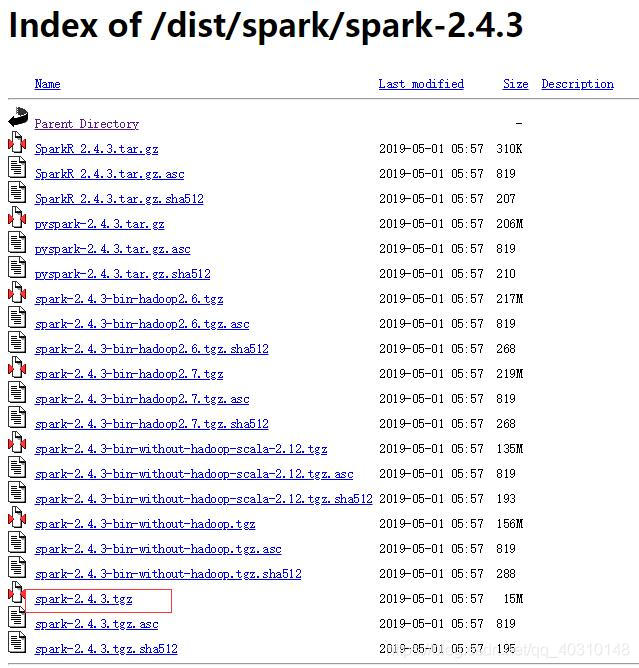
将下载好的源代码包上传到Linux目录下,并在节点上解压缩
二、使用Maven编译Spark
1.下载Maven安装包
http://maven.apache.org/download.cgi
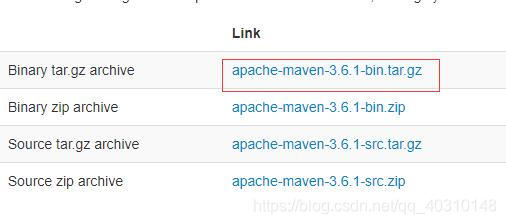
2.解压Maven并配置参数
1)上传至Linux中
2)解压
3)配置/etc/profile,加上如下设置:
export MAVEN_HOME=maven的安装目录
export PATH=$PATH:$MAVEN_HOME/bin4)配置完毕后,使用如下命令编译该配置文件,并验证Maven配置是否生效
source /etc/profile
mvn -version三、编译代码
编译过程需要保证编译机器联网状态,以保证Maven从网上下载其依赖包。另外,编译前需要设置JVM内存大小,否则在编译过程中,会由于默认内存小而出现内存溢出的错误。编译执行脚本如下,其中,参数-P表示激活依赖的程序及版本,-Dskip Tests表示编译时跳过测试环节。
cd spark源码包目录
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
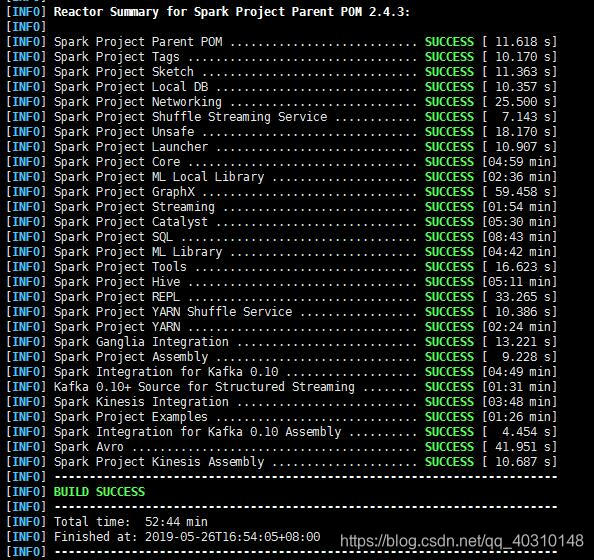
mvn -Pyarn -Phadoop-2.7 -Pspark-ganglia-lgpl -Pkinesis-asl -Phive -DskipTests clean package编译时可以通过以下命令查看编译文件夹的大小:
du -sh spark源码包目录成功结果页面:
四、生成Spark部署包
通过编译Spark源代码后,可以使用Spark源代码dev目录下一个生成部署包的脚本(make-distribution.sh)
在dev目录下的make-distribution.sh命令脚本中,使用如下命令生成Spark部署包
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
./make-distribution.sh --name hadoop2.7 --tgz -PR -Phadoop-2.7.2 -Phive -Phive-thriftserver -Pyarn编译成功页面如下图所示:
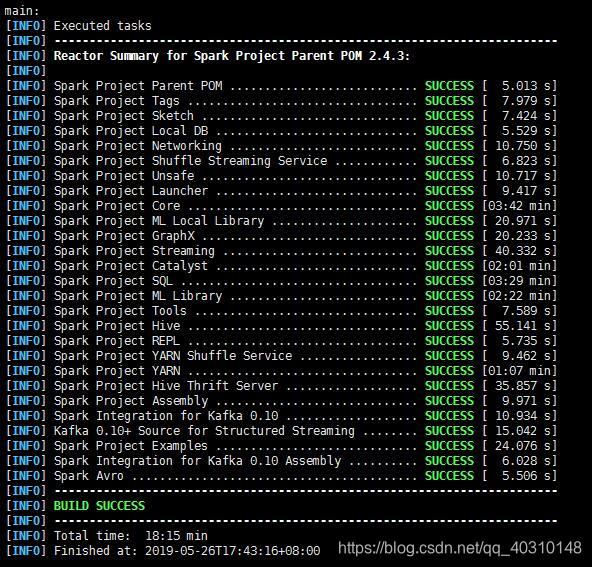
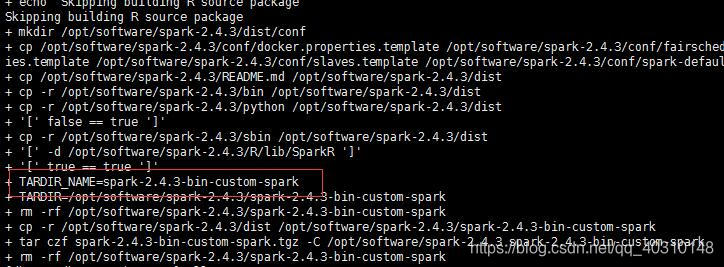
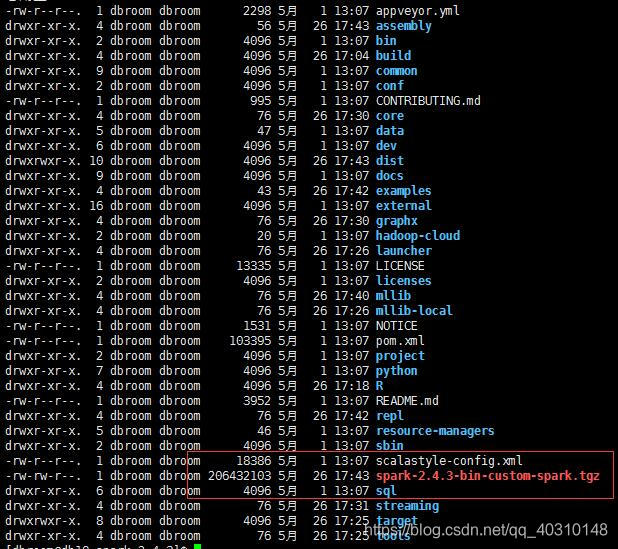
生成的部署包位于根目录下,文件名为:















 1201
1201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











