






 本文介绍了正则表达式的概念及其应用场景,包括验证、查找和替换等,并详细解释了构成正则表达式的各种基本要素,如字符类、数量限定符、位置限定符和特殊符号。
本文介绍了正则表达式的概念及其应用场景,包括验证、查找和替换等,并详细解释了构成正则表达式的各种基本要素,如字符类、数量限定符、位置限定符和特殊符号。
正则表达式
概念
正则表达式是用于描述一组字符串特征的模式,用来匹配特定的字符
串。通过特殊字符+普通字符进行模式的描述,从而达到文本匹配目的
的工具。
应用场景
验证:表单提交时,进行用户名及密码的验证。
查找:从大量信息中提取指定的内容。如:在一批url中,查找指定的url
替换:将指定格式的文本进行正则匹配查找,找到后进行替换。
正则表达式的基本要素
grep:一款Linux下进行匹配文本的工具。通常可带有很多的可用选项:
-E:使用扩展正则匹配
-color:将匹配到的内容进行语法高亮
在接下来的验证过程中,我们选用grep来进行验证
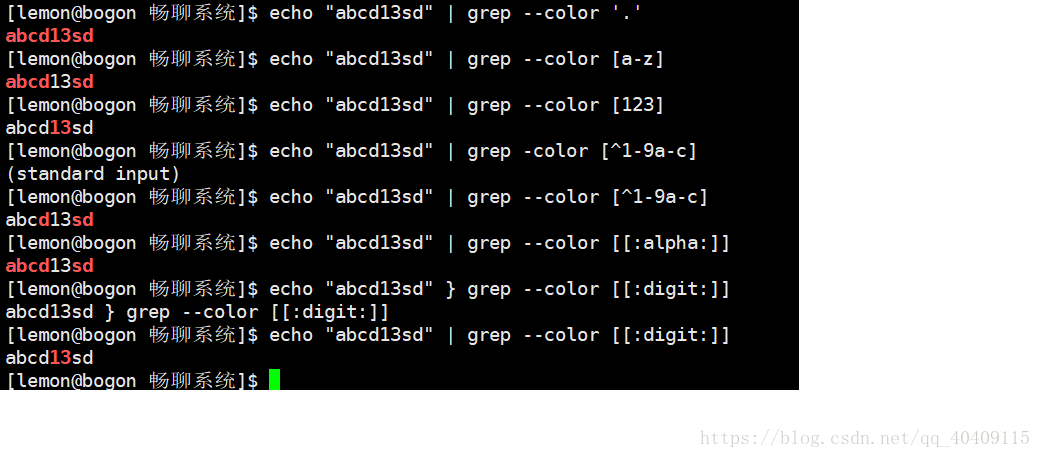
1.字符类
| 表达式 | 可匹配内容 |
|---|---|
| . | 匹配任意一个字符 |
| [] | 匹配括号中任意一个字符 |
| - | 在[]括号范围内表示字符的范围 |
| ^ | 位于[]括号内的开头,匹配除过括号内字符外的任意一个字符 |
| [[:xxx:]] | grep工具预定义的一些命令字符 |
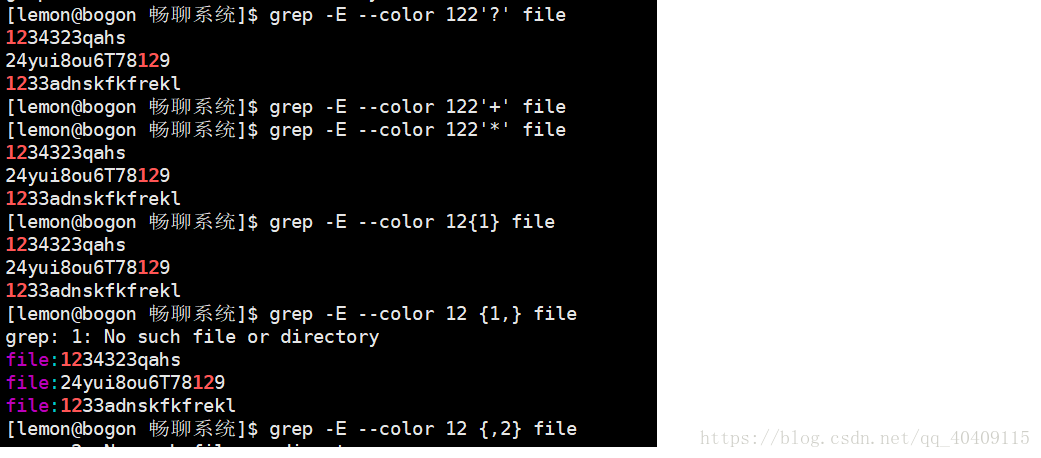
2.数量限定符
| 表达式 | 可匹配内容 |
|---|---|
| ? | 匹配紧跟在其前的的单元应该匹配0/1次 |
| + | 紧跟在其前面的单元应该匹配1/多次 |
| * | 紧跟在其前的单元应匹配0/多次 |
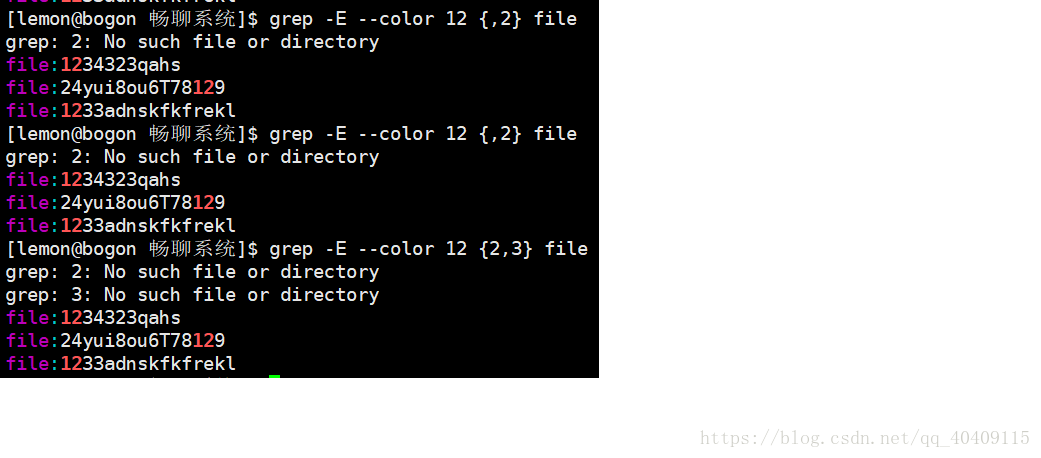
| {N} | 紧跟在其前面的单元应匹配N次 |
| {N,} | 紧跟在其前面的单元至少匹配N次 |
| {,M} | 紧跟在其前面的单元至多匹配N次 |
| {N,M} | 紧跟在其前面的单元应匹配N-M次 |
3.位置限定符
| 表达式 | 可匹配内容 |
|---|---|
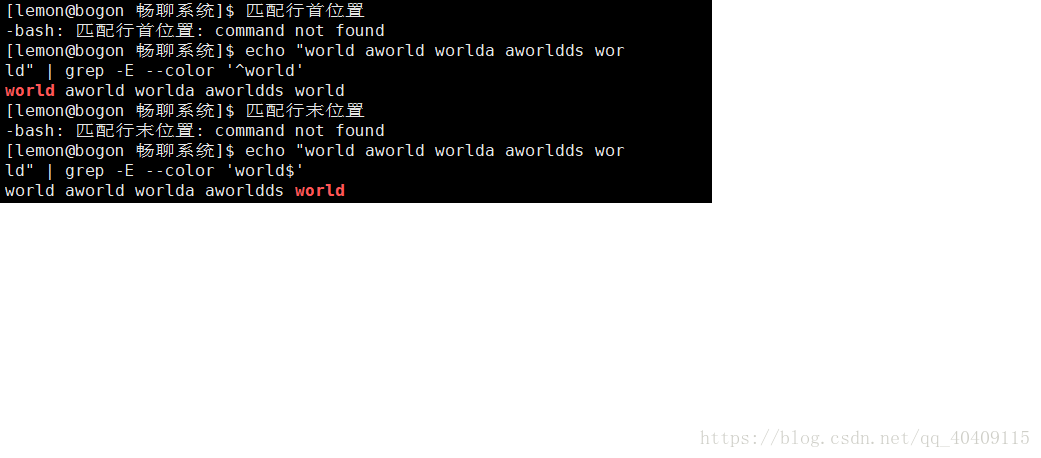
| ^ | 匹配行首位置,从字符串开始的地方匹配,不匹配任何字符 |
| $ | 匹配行末位置,从字符串结束的地方匹配,不匹配任何字符 |
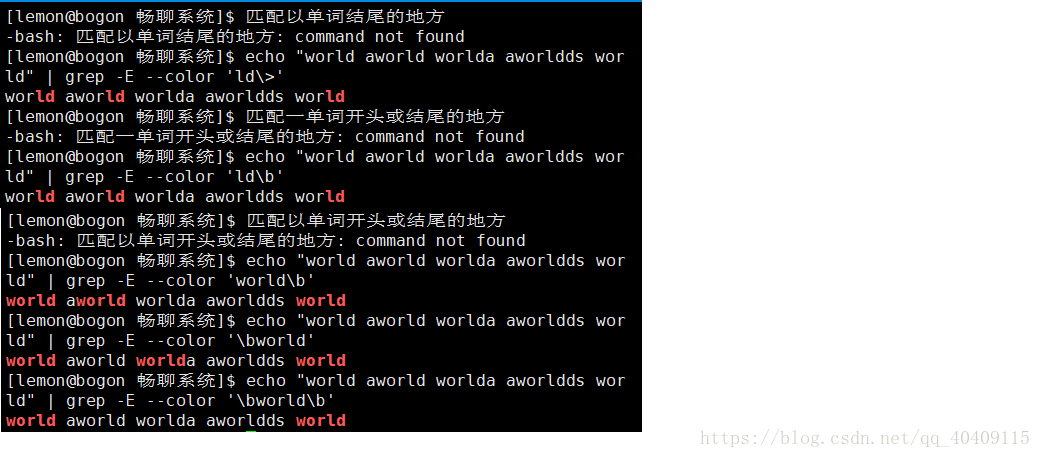
| \< | 匹配单词开头的位置 |
| > | 匹配单词结尾的地方 |
| \b | 匹配单词开头或结尾的地方(一个单词的边界,即单词与空格之间的位置不匹配任意字符) |
| \B | 匹配非单词开头和结尾的地方 |
| ^ $ | 严格匹配一行 |
4.特殊符号
| 表达式 | 可匹配内容 |
|---|---|
| \ | 转义字符,普通字符转义为特殊字符,特殊字符转义为普通字符 |
| () | 将正则表达式的一部分括起来组成一个单元,可以对整个单元使用数量限定符 |
| | | 连接两个表达式,表示或的关系 |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









