







关键字:K-means算法,聚类中心,畸变函数
一、定义
与有监督学习相比,无监督学习的样本没有任何标记。无监督学习的算法需要自动找到这些没有标记的数据里面的数据结构和特征。这里介绍一下聚类算法和降维。
二、聚类算法
2.1 定义
把数据集分成一个个的簇cluster(也可以理解为一组一组的形式)
2.2 K-means算法(K均值算法)
(1)首先随机生成几个点,叫聚类中心(Cluster Centroids)。Cluster Centroids的个数一般与想把数据分成几类的类数相同。如下图,想分成两类,首先随机生成两个点。
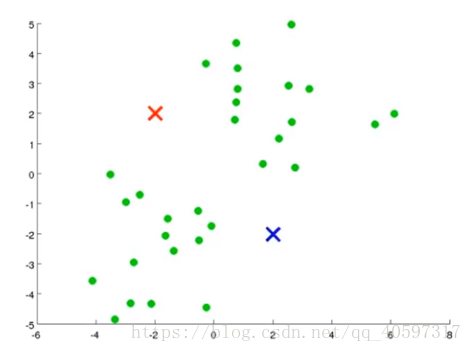
(2)这是一个迭代算法,一次迭代包含两个步骤。第一个是簇分配,第二个是移动聚类中心。
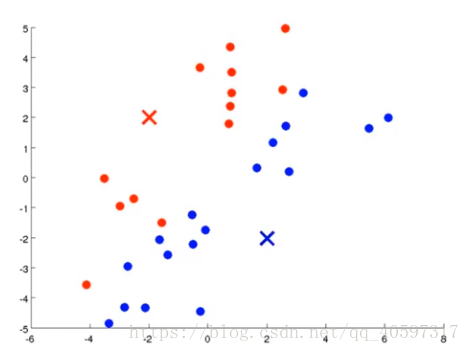
簇分配:遍历数据集里面的每个数据,也就是图例的绿色的点。然后根据每个数据是距离红色的聚类中心近还是蓝色的聚类中心近,来判断将数据分配给其中一个聚类中心。迭代终止条件:聚类中心不再变化,每个数据分配到的聚类不变。
图例判断结束之后是这样的:
移动聚类中心:算出每一个聚类的均值,将聚类中心移动到该点处。图例就分别算出蓝色聚类和红色聚类的均值,然后移动聚类中心。
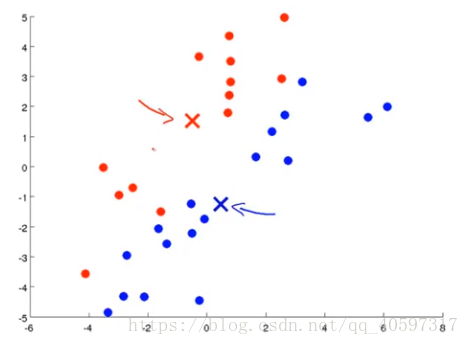
(3)伪代码表示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2179
2179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









