




Warp 分化是 NVIDIA GPU 上执行效率低下的主要原因之一,它直接源于 Warp(线程束)的 **SIMT(单指令多线程)**执行模型。
1. 什么是 Warp 分化?
1.1 定义
Warp 分化发生在 同一 Warp 内的 32 个线程 遇到条件语句(如 if/else, switch, 或循环中的 break)时,执行了不同的代码路径。
1.2 发生机制
一个 Warp 必须在同一时间执行同一条指令。当线程分化时,GPU 硬件会采取以下步骤强制执行:
-
串行化执行: GPU 不会同时执行所有分支,而是将整个 Warp 的执行串行化。
-
禁用线程: 硬件依次执行每个不同的分支路径。在执行某一特定分支时,不应执行该分支的所有线程都会被禁用(Masked Out)。
-
重新汇合: 只有当所有不同的分支路径都被执行完毕后,所有线程才会重新汇合(Reconverge)到分支结构之后的共同指令点。
1.3 性能影响
当 Warp 分化发生时:
-
指令吞吐量损失: 即使只有一半的线程在执行,整个 Warp 仍然消耗了执行所有分支路径所需的时钟周期。
-
资源浪费: 所有的计算核心(CUDA Cores)虽然被占用,但大部分时间处于被禁用状态,导致实际计算吞吐量下降。
极度分化(例如,每个线程都走向不同的代码路径)可能导致执行时间比理想状态慢 32 倍。
2. 识别 Warp 分化的典型场景
分化通常发生在线程的索引或数据值决定了它们走向不同的代码分支时。
2.1 边界检查(Boundaries)
线程块边缘的线程通常用于处理数据的边界条件,这常常导致分化:
// 假设 N 不是 blockDim.x 的倍数
int i = blockIdx.x * blockDim.x + threadIdx.x;
// Warp 末尾的线程发现 i >= N,进入 if 路径;其他线程进入 else 路径。
if (i < N) {
// 处理有效数据
C[i] = A[i] + B[i];
} else {
// 空操作(但仍需消耗指令周期)
}
虽然这种分化是必要的,但它只影响少数 Warp(网格边缘的 Warp),开销相对可控。
2.2 数据依赖的条件分支(Data-Dependent Branches)
这是最严重的分化类型,它取决于线程处理的数据:
// 假设 data[i] 的值是随机的
if (data[i] > threshold) {
// 路径 A
result[i] = funcA(data[i]);
} else {
// 路径 B
result[i] = funcB(data[i]);
}
如果 Warp 内的 32 个线程中,16 个执行路径 A,16 个执行路径 B,那么该 Warp 必须执行路径 A 和路径 B 的所有指令,导致 50%50\%50% 的效率损失。
3. 避免 Warp 分化的方法
优化的核心目标是确保同一 Warp 内(即 threadIdx 接近的线程)的线程尽量走向同一代码分支。
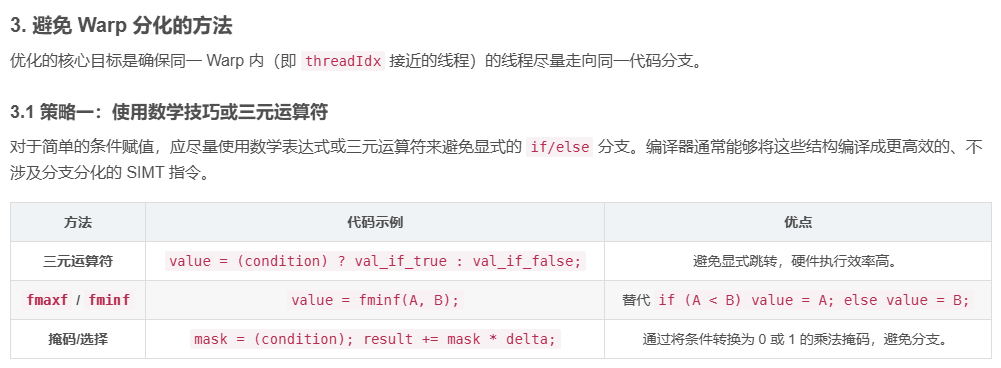
3.1 策略一:使用数学技巧或三元运算符
对于简单的条件赋值,应尽量使用数学表达式或三元运算符来避免显式的 if/else 分支。编译器通常能够将这些结构编译成更高效的、不涉及分支分化的 SIMT 指令。
| 方法 | 代码示例 | 优点 |
|---|---|---|
| 三元运算符 | value = (condition) ? val_if_true : val_if_false; | 避免显式跳转,硬件执行效率高。 |
fmaxf / fminf | value = fminf(A, B); | 替代 if (A < B) value = A; else value = B; |
| 掩码/选择 | mask = (condition); result += mask * delta; | 通过将条件转换为 0 或 1 的乘法掩码,避免分支。 |
3.2 策略二:重新组织数据
如果数据依赖导致分化,可以尝试在 Kernel 启动前重新组织数据,以提高局部性。
-
数据预排序: 在 CPU 或另一个 Kernel 中对数据进行预处理,使其在内存中按照某个关键值(如上面的
threshold)排序。 -
效果: 这样,索引相近的线程(它们组成同一个 Warp)将更有可能读取相似的数据值,从而满足相同的条件,走向相同的分支。
3.3 策略三:处理边界条件
对于边界检查,应尽量将分化控制在最小范围内。
-
方法: 相比于在 Kernel 内部使用
if (i < N)进行边界检查,有时可以将整个 Kernel 的启动配置为恰好覆盖 NNN 个元素,或者只对边界 Warp 执行分化检查。 -
向量化: 对于简单的边界检查,可以将其转换为循环,或者使用统一处理。例如,如果
i >= N,则将输入值设为 0,然后统一执行计算,最后再写回。
3.4 策略四:减少分支数量
如果必须使用 if/else 结构:
-
尽量在线程块级别或网格级别使用条件,而不是在线程级别使用。
-
在同一 Warp 内,尽量简化逻辑,确保线程在分支结束后尽快重新汇合。
4. 性能分析工具的应用
要确定 Warp 分化是否是你的性能瓶颈,必须使用专业的分析工具:
- Nsight Compute (NCu): NCu 提供了 **Branch Efficiency(分支效率)**指标。低分支效率(接近 50%50\%50% 或更低)直接表明存在严重的分化问题。NCu 还能将分支效率指标关联到源代码的
if/else语句上,帮助你精确定位问题所在。
总结:
Warp 分化是 SIMT 架构的固有特性,它将并行执行串行化。要调优 CUDA 性能,开发者必须:
-
设计算法: 确保同一 Warp 内的线程执行相同的指令路径。
-
使用技巧: 用三元运算符和数学技巧替代显式
if/else分支。 -
分析验证: 使用 Nsight Compute 量化分支效率,并验证优化效果。

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









