







前言
如何快速高效的寻到在硬盘存储的数据,于是文件系统就诞生了。文件系统是逻辑层面的,那么文件系统是如何管理好硬件层提供的磁盘空间的?
文件系统的技术方案
- 1.连续分配 创建文件时,分配一组连续的数据块。然后再单独的地方存储文件信息
- 2.链式分配 将文件块像链表一样管理起来,每个块放指针,指针指向下一个文件块位置
- 3.索引分配 通过文件索引找到存放文件的信息的数据块(数据库中有文件名,数据块位置等),然后再找到数据块的位置,类似图书馆中查找一本书的过程
现在,大部分文件系统采用索引分配方案
优点:
1.能够保持好大部分文件的局部性
2.满足文件插入,删除的高效
3.随机读写不需要沿着指针前行
缺点
1.会有较多的磁盘寻道次数
2.索引表本身管理复杂,会带来额外的系统开销
ext2文件系统
ext类有ext2、ext3、ext4文件系统,是ext类版本的升级
这里介绍ext2文件系统,当然它是属于索引分配的
基本概念
- 块. 即Block, 数据存储的最小单元, 每个块都有一个唯一的地址, 从0开始编号, 起源于第一个可以用来存储数据的扇区
- 超级块. 超级块保存了各种文件系统的meta信息, 比如块大小信息。他位于文件系统的2号和3号扇区(物理地址), 占用两个扇区大小
- 块组. 所有的块会划分成多个块组, 每个块组包含同样多个块, 但是可能整个文件系统整个块数不是块组的整数倍, 所以最后一个块组包含的个数可能会小于其他块
总体结构
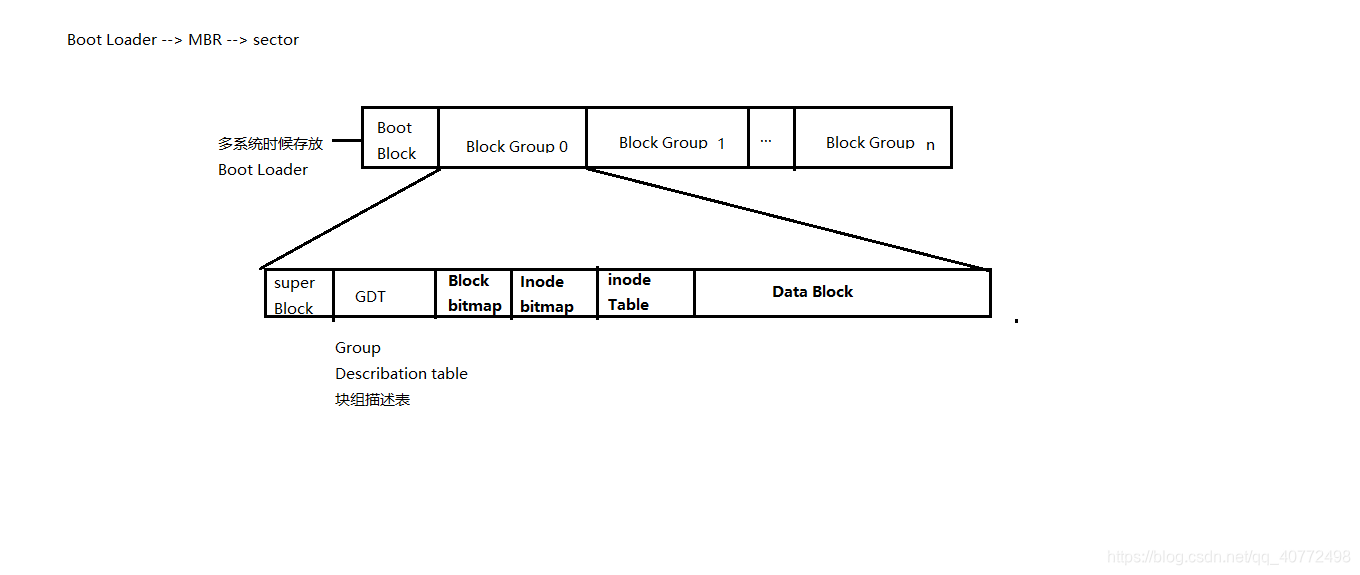
1.DataBlock 数据块
即Block, 数据存储的最小单元, 每个块都有一个唯一的地址, 从0开始编号, 起源于第一个可以用来存储数据的扇区;
2.inode Table inode节点表
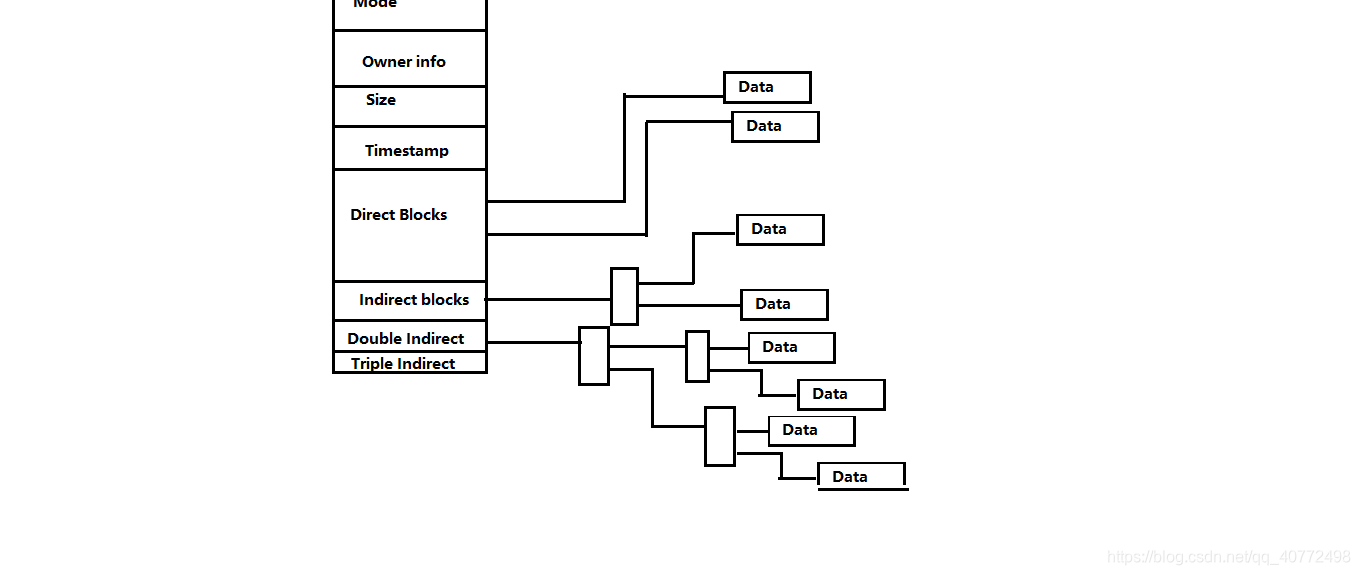
- 每个inode会被分配给一个目录或者一个文件,每个inode包含了128字节,文件的各种meta信息
- 在所有inode中, 1~10号会用作保留给内核使用, 在这些保留节点中, 2号节点用于存储根目录信息, 1号表示坏块, 8号表示日志文件信息。
- 第一个用户可见的都是从11号inode开始, 11号节点一般用作lost+found目录, 当检查程序发现一个inode节点已经被分配, 但是没有文件名指向他的时候, 就会把他添加到lost+found目录中并赋予一个新的文件名
文件项
- inode编号、文件类型、属主UID、属主的组GID、文件大小、文件所使用的磁盘块的实际数目、时间、以及数据块的信息
注:inode中没有文件名,只能通过inod找到;stat命令可以查看
目录项
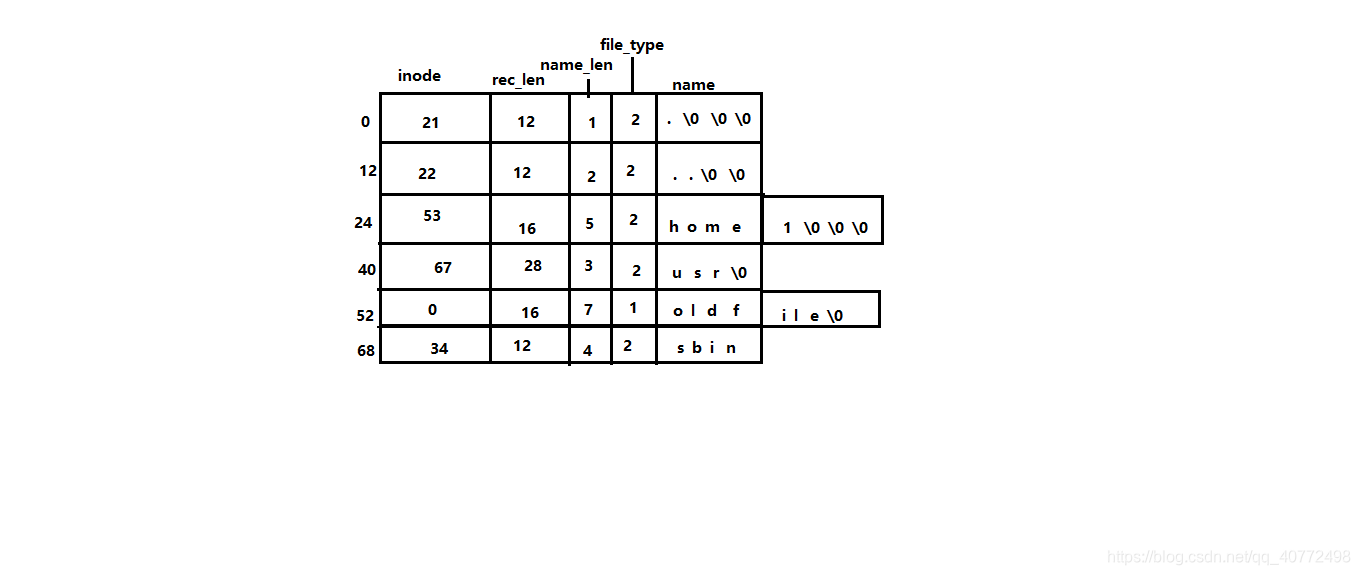
-
每个目录对应一个inode节点,该inode节点对应的数据块里面会存储该目录下所有文件和目录的信息(meta)
-
每个文件/目录对应的信息就叫目录项, 目录项包含的内容也很简单, 主要就是文件名和指向该文件名的inode指针, 详细信息如下
| 偏移(16进制) | 字节数 | 含义&解释 |
|---|---|---|
| 00-03 | 4字节 | inode节点号 |
| 04-05 | 2字节 | 本目录项的长度字节数 |
| 06 | 1字节 | 名字长度字节数 |
| 07 | 1字节 | 文件类型 |
| 08~ | 不定长度 | 名字的ascii码 |
3.inode bitmap inode节点位图
- 由于一个文件系统中会有许多的文件和目录,都需要inode。那么如何知道哪些inode块分配过了,哪些inode块可使用,就需要遍历一遍inode Table,为了提高效率,使用位图,将已分配的inode映射到bitmap中。
- 默认inode节点位图和一个数据块的大小一样
4.block bitmap 数据块位图
- 同样,那么多的数据块为了方便管理,使用数据块位图,默认数据块位图和一个数据块的大小一样
5.GDT Group Description table 块组描述表
- 往往会将一个分区,分成多个块组,也是为了文件系统内部有方便管理。
- 组描述符表中包含了所有组描述信息,每个块组占据32个字节。
- 组描述符在每个块组中都会备份,但也有特殊情况,只在当块组号是3,5,7的幂的块组才保存(稀疏超级块)
- 数据块位图,inode节点位图,inode节点表的起始位置都在组描述符中表示
| 偏移(16进制) | 字节数 | 含义&解释 |
|---|---|---|
| 00~03 | 4 | 块位图起始地址(块号) |
| 04~07 | 4 | inode节点位图起始地址(块号) |
| 08~0B | 4 | inode节点表起始地址(块号) |
| 0C~0D | 2 | 块组中空闲块数 |
| 0E~0F | 2 | 块组中空闲inode节点数 |
| 10~11 | 2 | 块组中的目录数 |
| 12~1F | - | 未使用 |
6.Super block超级块
2-3号扇区(在文件系统第1024-2048字节处),包含各种meta信息
- 块大小, 每个块组包含块数, 总块数, 第一个块前保留块数, inode节点数, 每个块组的inode节点数
- 卷名, 最后挂载时间, 挂载路径, 文件系统是否干净, 是否要调用一致性检查标识
- 空间inode节点和空闲块的记录信息, 在分配inode节点和新块的时候使用
7.0-1扇区 引导扇区
如如果没有引导代码,则这两个扇区为空,全部用0填充
总结
如图书馆存书为例,如果一本本的跑遍整个图书馆,你肯定不会这么做。于是就有图书索引,这本书放在几楼,第几个书架。
然而,这么多书靠索引还是要找很久,于是就有分门目。而在文件系统中就是块组。大致区域就是一个分区,多个块组,用索引查找,索引存放在inode Table中,书本放在数据块中。
而inode bitmap和block bitmap是为了插入和删除的时候,更加快的找到那个数据块和inode存放块是否分配,便于文件系统管理
内容很多,刚刚这一遍下来,其实心里还没有清楚每一个区块的作用,还需要实际的例子来演示一把,由于怕篇幅过长,就放到下一篇啦














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









